
CubeFS,原名 ChubaoFS(储宝)是一个云原生存储平台,也是为大规模容器平台设计的分布式文件系统,它提供分布式文件系统与对象存储服务,为云原生应用提供计算与存储分离的持久化存储方案。
CubeFS 由元数据子系统、数据子系统和资源管理器组成,同时提供对象和文件存储,具有很强的复制一致性,并且特别适合快速处理小文件,这是支持云原生工作负载的另一个有利特性。
整体架构
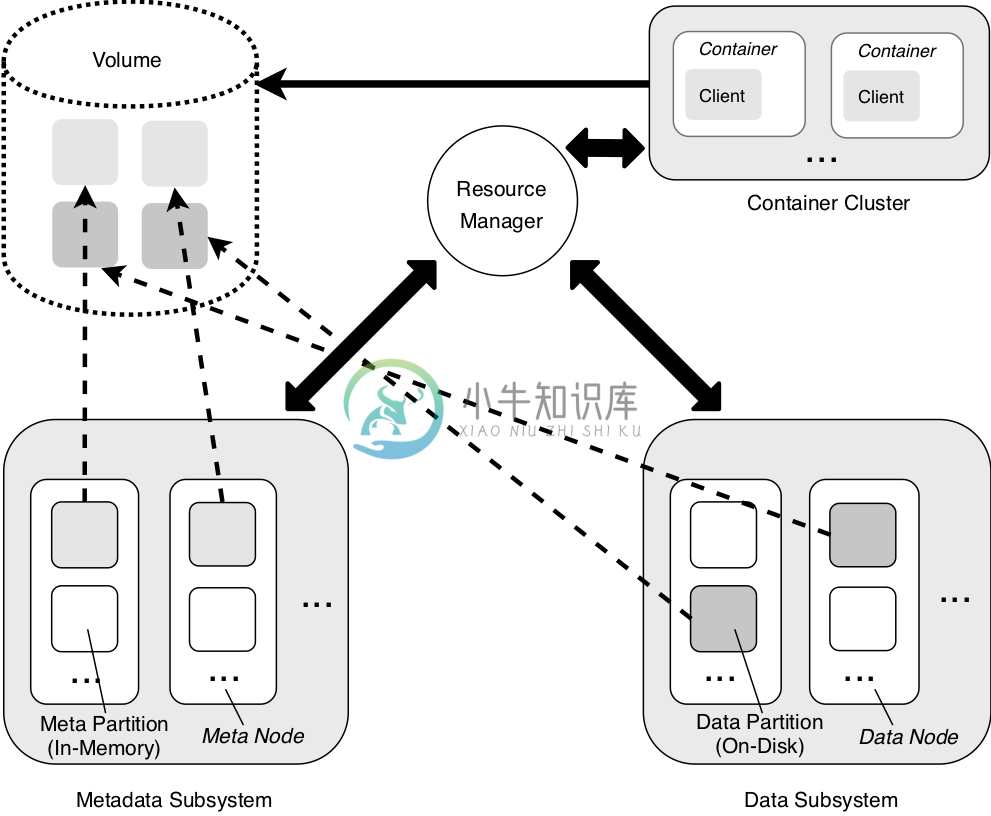
CubeFS 的一些关键特性包括:
- 可扩展元数据管理
- 强一致性的复制协议
- 针对大/小文件和顺序/随机写入的特定性能优化
- 多租户
- POSIX 兼容
- 兼容 S3 的对象存储接口
-
数据存储容量的问题。 数据读写速度的问题。 数据可靠性的问题。 几种常见 RAID 的对比|名称|优点|缺点| |------|------|------| |RAID 0|使用 N 块磁盘的 RAID 0,将数据从内存写入磁盘时,将数据分成 N 块,并发写入,读取同理。所以,读写速度是单盘的 N 倍。|任何一块盘损坏,数据完整性破坏,数据不可用。| |RAID 1|数据写入磁盘时,将一份数据同时
-
一、介绍 HDFS (Hadoop Distributed File System)是 Hadoop 下的分布式文件系统,具有高容错、高吞吐量等特性,可以部署在低成本的硬件上。 二、HDFS 设计原理 2.1 HDFS 架构 HDFS 遵循主/从架构,由单个 NameNode(NN) 和多个 DataNode(DN) 组成: NameNode : 负责执行有关 文件系统命名空间 的操作,例如打开,
-
Hadoop分布式文件系统(HDFS)的设计主旨,在于对超大规模数据集提供可靠的存储功能,并对用户应用程序提供高带宽的输入输出数据流。在大型的集群里,上千台服务器均可直接参与到数据存储和应用程序任务执行。通过多服务器,分布式的存储和计算,计算资源的规模能够按照需要增长,并兼顾在各种规模上经济适用性。 本文主要描述了HDFS的架构,并以Yahoo!企业数据服务为例,介绍了如何使用HDFS系统管理高达
-
原文链接:http://www.aosabook.org/en/hdfs.html 作者:Robert Chansler, Hairong Kuang, Sanjay Radia, Konstantin Shvachko与Suresh Srinivas HDFS(Hadoop Distributed File System,Hadoop分布式文件系统)的设计宗旨,是可靠地存储极大的数据集,并将其以
-
主要内容:一、从一个新闻门户网站案例引入,二、推算一下你需要分析多少条数据?,三、黄金搭档:分布式存储+分布式计算这篇文章聊一个话题:什么是分布式计算系统? 一、从一个新闻门户网站案例引入 现在很多同学经常会看到一些名词,比如分布式服务框架,分布式系统,分布式存储系统,分布式消息系统。 但是有些经验尚浅的同学,可能都很容易被这些名词给搞晕。所以这篇文章就对“分布式计算系统”这个概念做一个科普类的分析。 如果你要理解啥是分布式计算,就必须先得理解啥是分布式存储,现在我们从一个小例子来引入。 比如说
-
被别人指出问题时,别管别人能不能做到,看别人说的对不对,然后完善自己。别人能不能做到是别人的事情,自己能不能做到关系到自己能否发展的更好。——hustlihaifeng Go语言号称是互联网时代的C语言。现在的互联网系统已经不是以前的一个主机搞定一切的时代,互联网时代的后台服务由大量的分布式系统构成,任何单一后台服务器节点的故障并不会导致整个系统的停机。同时以阿里云、腾讯云为代表的云厂商崛起标志着