
GNE 是基于论文《基于文本及符号密度的网页正文提取方法》实现的新闻网页正文通用抽取器。
在论文中描述的正文提取基础上,还增加了标题、发布时间和文章作者的自动化探测与提取功能。
最后的输出效果如下图所示:
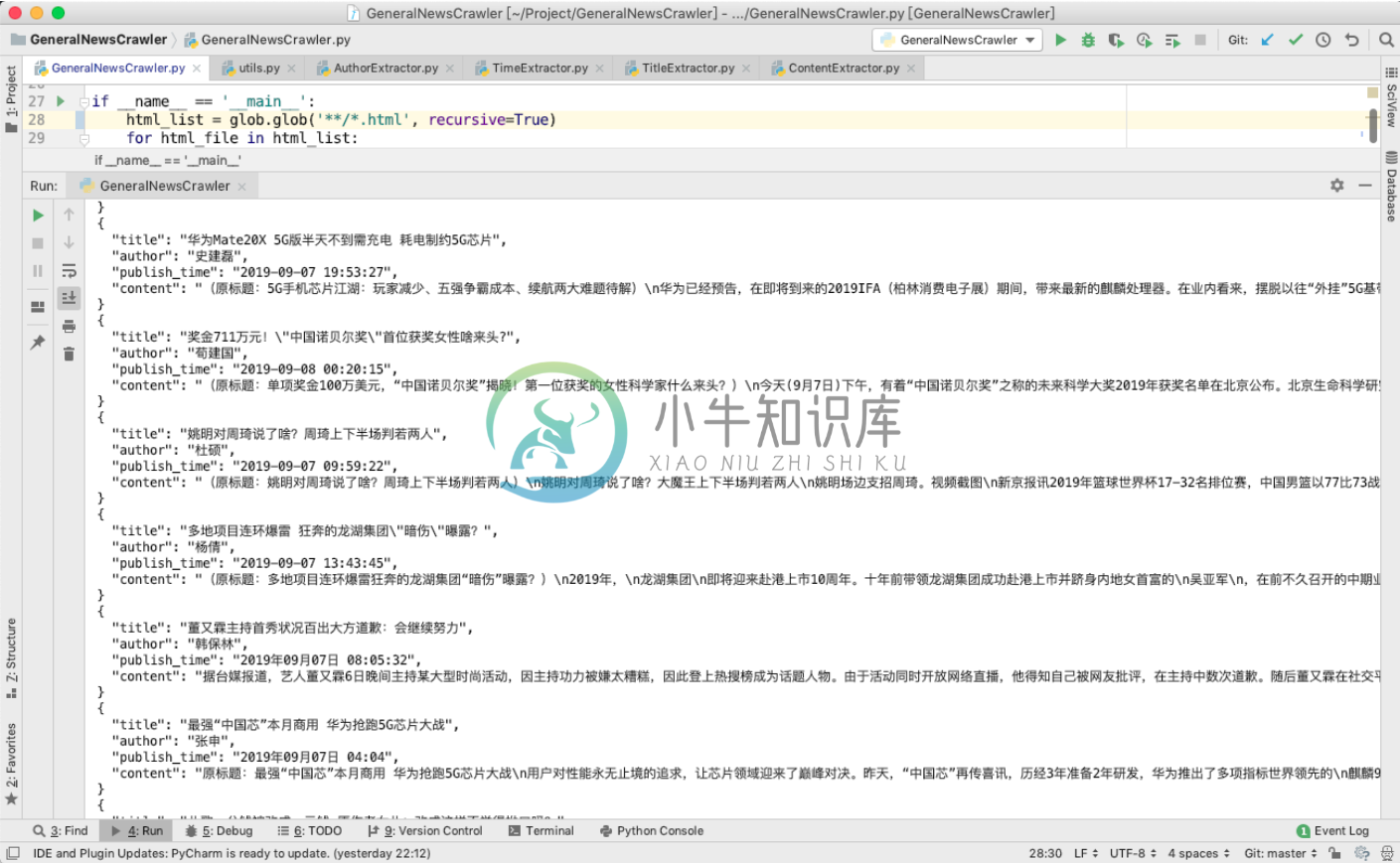
本项目取名为抽取器,而不是爬虫,是为了规避不必要的风险,因此,本项目的输入是 HTML,输出是一个字典。请自行使用恰当的方法获取目标网站的 HTML。
在线体验
如果你想先体验 GNE 的提取效果,那么你可以访问http://gne.kingname.info/。 一般情况下,你只需要把网页粘贴到最上面的多行文本框中,然后点提取按钮即可。通过附加更多的参数,可以让提取更精确。具体 参数的写法与作用,请参阅 API
使用环境
如果你想体验 GNE 的功能,请按照如下步骤进行:
安装 GNE
# 以下两种方案任选一种即可 # 使用 pip 安装 pip install --upgrade gne # 使用 pipenv 安装 pipenv install gne
使用 GNE
提取正文
>>> from gne import GeneralNewsExtractor >>> html = '''经过渲染的网页 HTML 代码''' >>> extractor = GeneralNewsExtractor() >>> result = extractor.extract(html, noise_node_list=['//div[@class="comment-list"]']) >>> print(result) {"title": "xxxx", "publish_time": "2019-09-10 11:12:13", "author": "yyy", "content": "zzzz", "images": ["/xxx.jpg", "/yyy.png"]}
更多使用说明,请参阅 GNE 的文档
提取列表页(测试版)
>>> from gne import ListPageExtractor >>> html = '''经过渲染的网页 HTML 代码''' >>> list_extractor = ListPageExtractor() >>> result = list_extractor.extract(html, feature='列表中任意元素的 XPath") >>> print(result)
运行截图
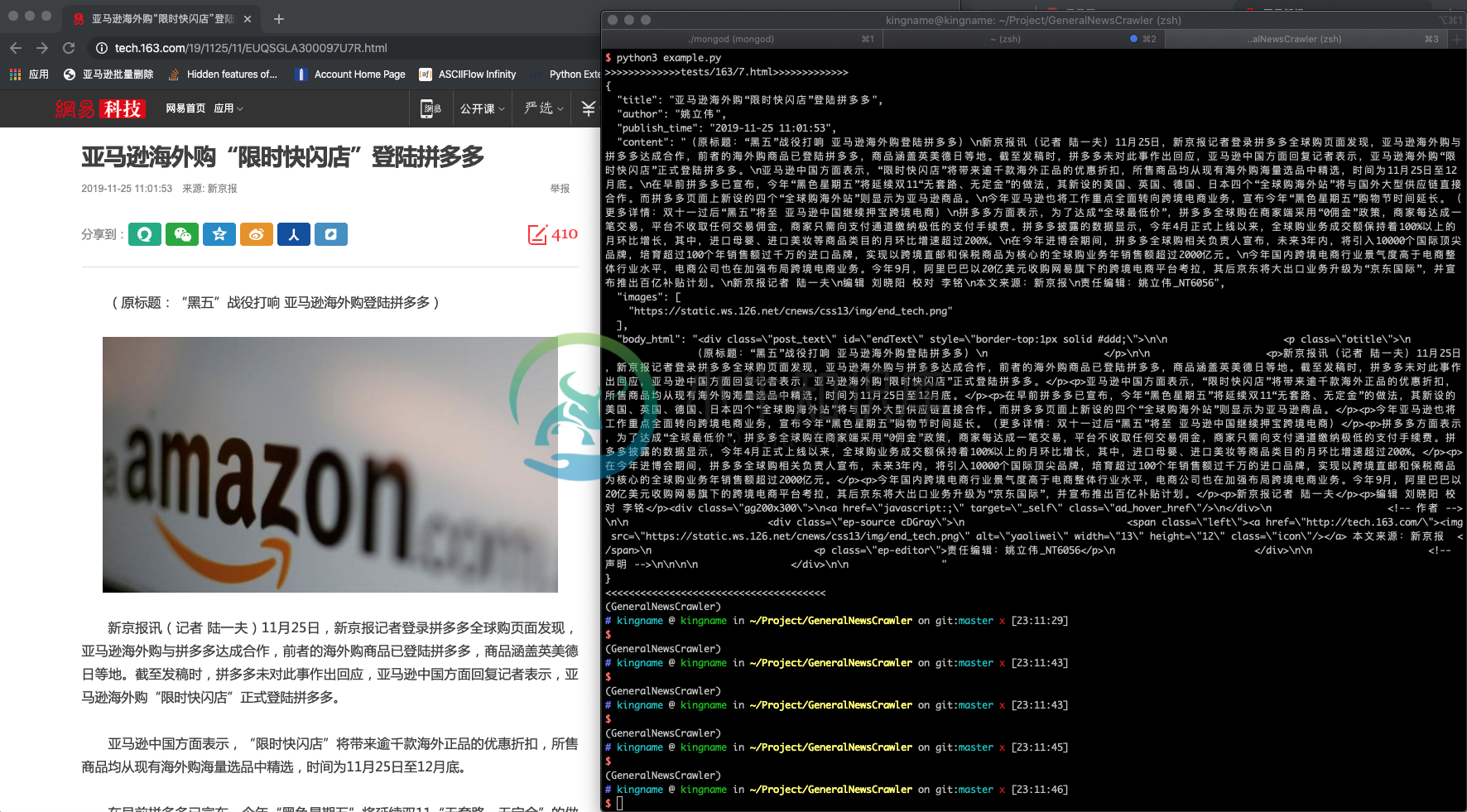
网易新闻
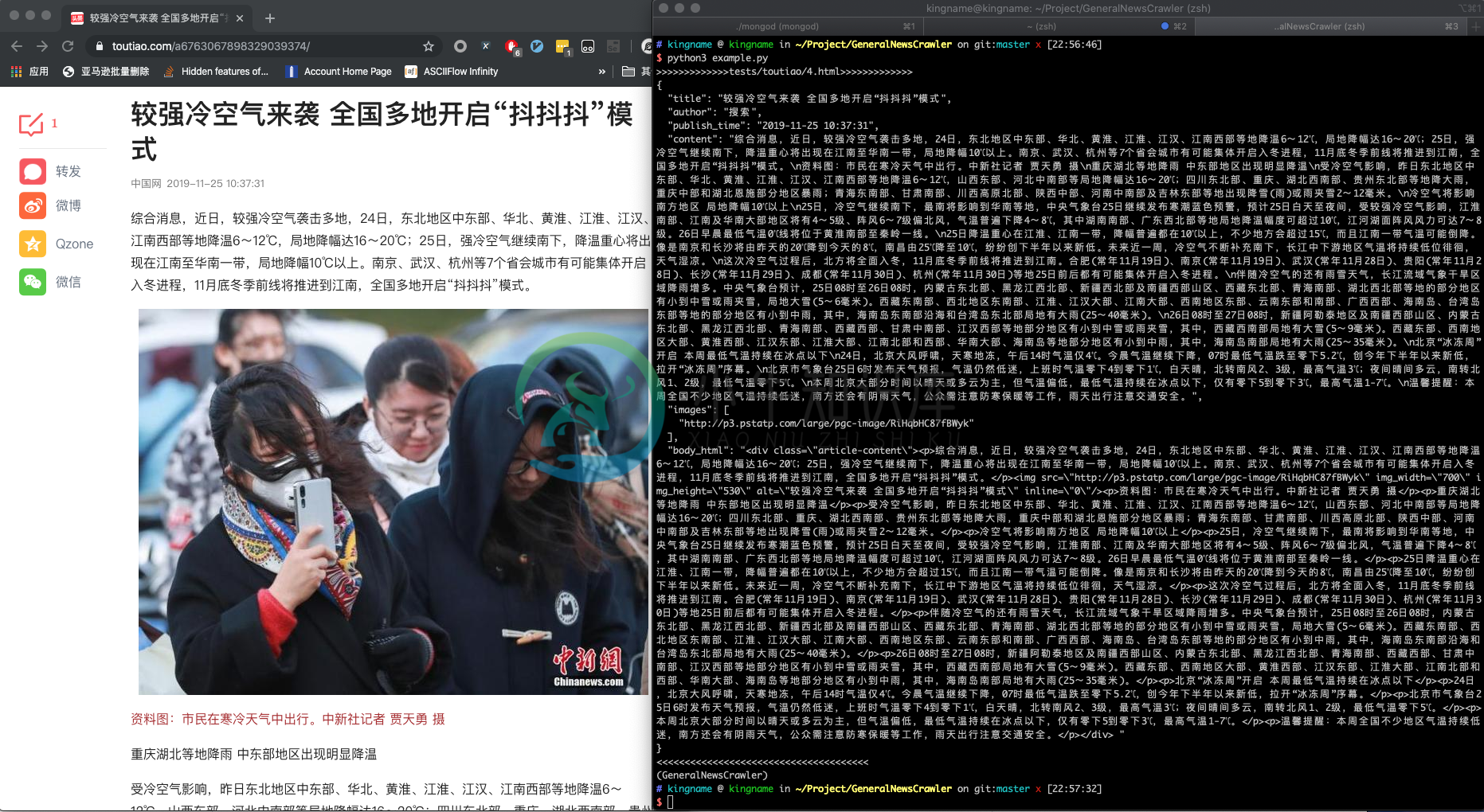
今日头条
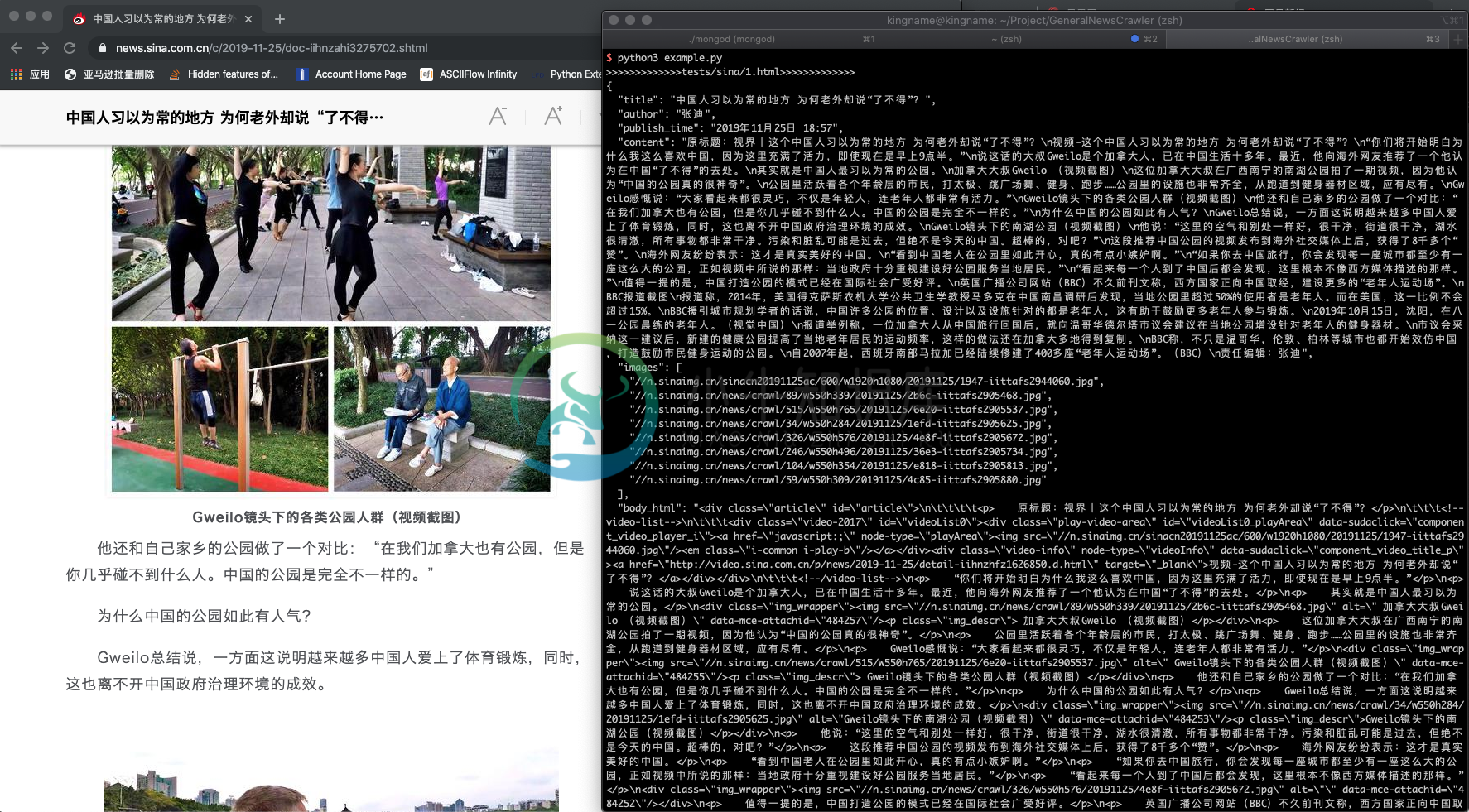
新浪新闻
-
GNE(GeneralNewsExtractor)是一个通用新闻网站正文抽取模块,输入一篇新闻网页的 HTML, 输出正文内容、标题、作者、发布时间、正文中的图片地址和正文所在的标签源代码。GNE 在提取今日头条、网易新闻、游民星空、 观察者网、凤凰网、腾讯新闻、ReadHub、新浪新闻等数百个中文新闻网站上效果非常出色,几乎能够达到 100%的准确率。 如何安装 GNE 直接使用 pip 安装
-
GNE是一个准确率高达99.9%的新闻类网页通用抽取器。有了这个神器,我们不再需要xpath写来写去,这适合通用的新闻资讯类网页正文内容提取。下面我们以南方周末,一个网页例子为说明。 GNE(GeneralNewsExtractor)是一个通用新闻网站正文抽取模块,输入一篇新闻网页的 HTML, 输出正文内容、标题、作者、发布时间、正文中的图片地址。 安装gne: pip install gne
-
本文主要介绍执行该爬虫所需的环境搭建,其他不多赘述。 环境搭建分以下3步,python3运行环境搭建、本地浏览器驱动安装、爬虫依赖包安装。 一、Python3运行环境搭建 Mac系统安装Python推荐使用Homebrew安装,即先安装homebrew,再使用brew命令安装Python。 复制下面的命令,粘贴到Mac的终端命令行执行,安装需要等待一段时间 /bin/bash -c "$(curl
-
GeneralNewsExtractor(GNE)是一个通用新闻网站正文抽取模块,输入一篇新闻网页的 HTML, 输出正文内容、标题、作者、发布时间、正文中的图片地址和正文所在的标签源代码。GNE在提取今日头条、网易新闻、游民星空、 观察者网、凤凰网、腾讯新闻、ReadHub、新浪新闻等数百个中文新闻网站上效果非常出色,几乎能够达到100%的准确率。 安装 # 以下两种方案任选一种即可 # 使用
-
阿里云本地SSD型实例i2gne云服务器配置性能CPU、内存、适用场景、本地SSD型i2gne实例规格族和优惠报价信息,InstanceTypes分享 本地SSD型i2gne实例详解: 本地SSD型i2gne实例规格族特性 I/O优化实例 仅支持SSD云盘和高效云盘 配备高性能(高IOPS、大吞吐、低访问延迟)NVMe SSD本地盘 实例网络带宽最高可达20 Gbit/s 处理器与内存配比为1:4
-
gne——新闻网页的页面解析工具介绍 说明 爬新闻的时候,针对不同的新闻网站要写不一样的解析代码。有一个大神写了一个工具叫gne,下面是这个工具的GitHub地址: gne——Github 先要装一下这个包:pip install --upgrade gne 使用方法 # 导入gne from gne import GeneralNewsExtractor html = '''网页的html代码
-
在上一节中,我们通过如何写出一个包含静态页面的类来了解了一些这个框架的基本概念。我们也根据自定义路由规则重新梳理了URI。现在是时候向大家介绍动态内容和如何使用数据库了。 创建你的数据模型 数据库的运算并不是在控制类中进行的,而是在数据模型中,这样他们就可以在后面很容易地被反复使用。数据模型就是对你的数据库或其他数据存储方式进行取回、插入和更新的地方,它们的功能是展示你的数据(They repre
-
在上一节中,我们通过写出一个包含静态页面的类了解了一些框架的基本概念, 我们也根据自定义路由规则来重定向 URI 。现在是时候向大家介绍动态内容 和如何使用数据库了。 创建你的数据模型 数据库的查询操作应该放在模型里,而不是写在控制器里,这样可以很方便的重用它。 模型正是用于从数据库或者其他存储中获取、新增、更新数据的地方。它就代表你的数据。 打开 application/models/ 目录,新
-
实现类似网易新闻的下拉刷新样式。下拉列表时,会画出一个小圆。代码基于EGOTableViewPullRefresh。 [Code4App.com]
-
问题内容: 我正在从html文件中读取文本并进行一些分析。这些.html文件是新闻文章。 码: 现在,我只想要文章的内容,而不是广告,标题等文本的其余部分。我如何在python中相对准确地做到这一点? 我知道一些工具,例如Jsoup(java API)和bolier,但我想在python中这样做。我可以找到一些使用bs4的技术,但仅限于一种类型的页面。我有来自众多来源的新闻页面。另外,也没有任何示
-
本文向大家介绍Android实现网易新闻客户端首页效果,包括了Android实现网易新闻客户端首页效果的使用技巧和注意事项,需要的朋友参考一下 关于实现网易新闻客户端的界面,以前写过很多博客,请参考: Android实现网易新闻客户端效果 Android实现网易新闻客户端侧滑菜单(一) Android实现网易新闻客户端侧滑菜单(二) 今天用ViewPager + FragmentAdapter +
-
原文 "BRITAIN does not dream of some cosy, isolated existence on the fringes of the European Community," asserted Margaret Thatcher in 1988. Now, increasingly, it does. Opinion polls show that most Brit