
Apache Kudu 简介
为了应对先前发现的这些趋势,有两种不同的方式:持续更新现有的Hadoop工具或者重新设计开发一个新的组件。其目标是:
对数据扫描(scan)和随机访问(random access)同时具有高性能,简化用户复杂的混合架构;
高CPU效率,最大化先进处理器的效能;
高IO性能,充分利用先进永久存储介质;
支持数据的原地更新,避免额外的数据处理、数据移动
我们为了实现这些目标,首先在现有的开源项目上实现原型,但是最终我们得出结论:需要从架构层作出重大改变。而这些改变足以让我们重新开发一个全新的数据存储系统。于是3年前开始开发,直到如今我们终于可以分享多年来的努力成果:Kudu,一个新的数据存储系统。
-
马上过年了,抢了两天的火车票都没抢到。果断叫黄牛了,希望明天能帮我抢到…. apache的kudu是Cloudera开源的存储引擎,可以结合impala做实时的一些查询,小米那边就用了kudu。具体的一些东西,自己去google或者baidu吧。 由于这边后面会用到kudu的一些东西,就看了下它的文档。在网上kudu java api这一部分貌似没看到别人给demo,只有官方的github上面有小
-
数据模型 kudu集群所存储的表,看起来就像是关系型数据库中的表。这个表可以简单的像一个键值对,也可以复杂的像上百个不同类型的属性。 像关系表一样,每张表有一个主键,这个主键可以由一个或者多个列组成。比如可以用用户ID作为单个列的主键,或者(host, metric, timestamp)作为一个组合主键。通过主键,表中的行记录可以被高效的读,更新,删除。 kudu简单的数据模型使其能够轻易的移植
-
1. 表Schema介绍 Kudu的表是一种结构化数据模型,包含3个方面:分区设计、primary key设计、column设计 2. Column设计 2.1 支持的列数据类型 支持的列数据类型如下: boolean 8-bit有符号integer 16-bit有符号integer 32-bit有符号integer 64-bit有符号integer date(32-bit days since
-
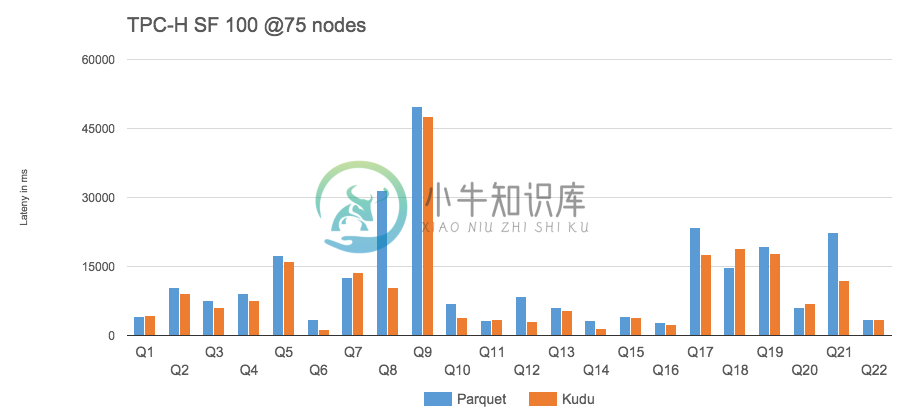
一、背景 HDFS:吞吐能力极强,但是随机读写能力差,适合进行批处理数据分析 HBase:随机读写能力极强,但是吞吐能力差,适合做随机分析处理。 kudu:它是一个介入HDFS 和 Hbase之间的存储引擎。可以同时提供低延迟的随机读写和高效的数据分析能力。 此外,kudu支持水平扩展,并且与 Impala 和 Spark 等当前流行的大数据查询和分析工具结合紧密。 二、kudu架构 与HDFS
-
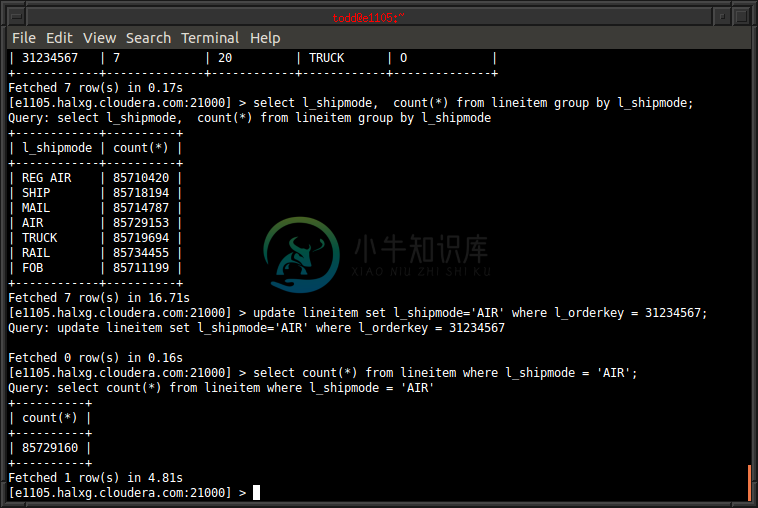
1. 使用Java/Scala API进行表创建、插入数据、alter表、scan表、删除表 1.1 pom.xml 添加如下依赖 <dependency> <groupId>org.apache.kudu</groupId> <artifactId>kudu-client</artifactId> <vers
-
问题内容: 我想将分层的二维科学数据集存储在关系数据库(MySQL或SQLite)中。每个数据集都包含一个数值数据表,其中包含任意数量的列。另外,每个数据集可以具有一个或多个与其表的给定行关联的相同类型的子级。每个数据集通常具有1至100列和1至1.000.000行。数据库应该能够处理许多数据集(> 1000),并且数据的读/写应该相当快。 存储此类数据的最佳数据库模式将是什么?是否有一个“主”表
-
数据存储 Cookie 浏览器中的 Cookie 是指小型文本文件,通常在 4KB 大小左右。(由键值对构成用 ; 隔开)大部分时候是在服务器端对 Cookie 进行设置,在头文件中 Set-Cookie 来对 Cookie 进行设置。 页面可以访问当前页的 Cookie 也可以访问父域的 Cookie。 属性 属性 默认值 作用 Name(必填) 名 Value(必填) 值 Domain 当前文
-
前端数据存储工具 YDN-DB forerunner AlaSQL LokiJS lovefiled Dexie.js localForage pouchdb
-
我在谷歌上搜索过,找不到任何可以在O(1)时间内存储和读取双向数据的DS。例如书籍和作家。有了书的名字,就必须找到作者。有了作者的名字,就必须找到书。 在数据库中,这些关系(如联接表)是如何存储的? 提前谢谢。
-
一个程序免不了要储存数据,对于Chrome扩展也是这样。通常Chrome扩展使用以下三种方法中的一种来储存数据:第一种是使用HTML5的localStorage,这种方法在上一节的内容中已经涉及;第二种是使用Chrome提供的存储API;第三种是使用Web SQL Database。 对于一般的扩展,“设置”这种简单的数据可以优先选择第一种,因为这种方法使用简单,可以看成是特殊的JavaScrip
-
当我扩展CrudRepository接口时,我的子接口中有方法。我可以写 签入我的服务层。
-
问题内容: 如果我的数据是关系型的(出版商-作者-书,协会-团队-玩家),我们可以使用像HBase或MongoDB这样的NoSQL系统来存储数据吗? (我知道这听起来像是一个愚蠢的问题,但我只是在学习:)) 问题答案: 是的,您可以在NoSQL数据存储中存储任何类型的数据。您描述的信息种类对于NoSQL应该是足够的。 但是,请注意,在典型的NoSQL解决方案中,您将交易SQL数据库中某些理所当然的
-
主要内容:创建存储数据表,Pymysql基本使用,修改爬虫程序Python 连接并操作 MySQL 数据库,主要通过 Pymysql 模块实现。本节讲解如何将抓取的数据存储至 MySQL 数据库。 提示:在学习本节知识之前,您已经掌握了 SQL 语言的基本语法。可参考《MySQL教程》 创建存储数据表 首先您应该确定您的计算机上已经安装了 MySQL 数据库,然后再进行如下操作: Pymysql基本使用 1) 连接数据库 参数说明: localhost:本地