
QSQL是以SQL进行单一、混合查询的一款产品。QSQL支持标准SQL语言(SQL-2003);QSQL支持查询关系型数据库、NoSQL式数据库、原生不支持SQL查询的存储(如ES、Druid),及借助中间计算引擎实现混合查询。QSQL最大的特点是独立于计算引擎、存储引擎本身,如此用户只需要关注于QSQL语法以及数据本身,就可完成数据计算、统计以及分析。
架构设计
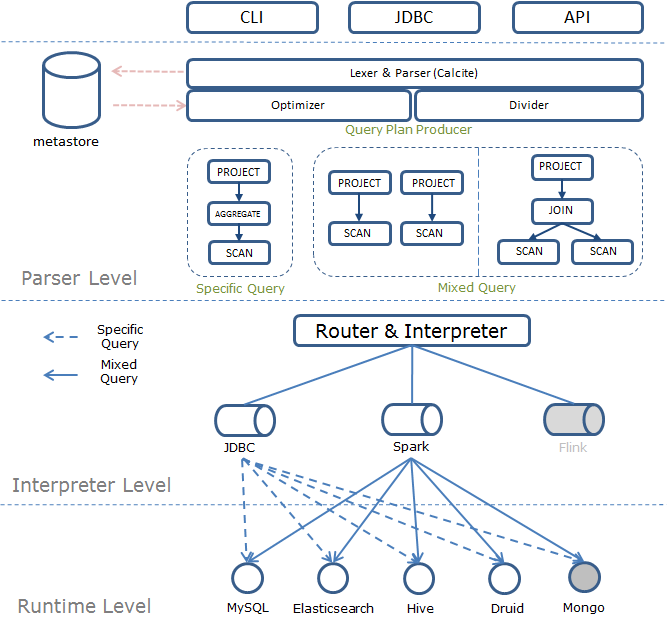
QSQL包含三层结构:
-
语法解析层:负责SQL语句的解析、校验、优化、混算SQL的切分以及最终生成Query Plan;
-
计算引擎层:负责Query Plan路由到具体的执行计划中,将Query Plan解释为具体的执行引擎可识别的语言;
-
数据存储层:负责数据的提取、存储;
编译&部署
1 编译环境依赖
-
java >= 1.8
-
scala >= 2.11
-
maven >= 3.3
2 编译步骤
在源码根目录下,执行:
mvn -DskipTests clean package
编译成功后执行:
ls ./target/
在./target/目录下,会生成发布包 qsql-0.5.tar.gz。
3 部署环境依赖
-
CentOS 6.2
-
java >= 1.8
-
scala >= 2.11
-
spark >= 2.2
-
[可选] 目前QSQL支持的存储引擎MySQL、Elasticsearch、Hive、Druid
4 客户端部署
在客户端解压缩发布包 qsql-0.5.tar.gz
tar -zxvf ./qsql-0.5.tar.gz
建立软链
ln -s qsql-0.5/ qsql
该发布包解压后的主要目录结构如下:
-
bin:脚本目录
-
conf:配置文件
-
data:存放测试数据
-
lib:依赖jar包
-
metastore:元数据管理
在QSQL发布包$QSQL_HOME/conf目录中,分别配置如下文件:
-
base-env.sh:设置相关环境变量,如:
-
JAVA_HOME
-
SPARK_HOME
-
QSQL_CLUSTER_URL
-
QSQL_HDFS_TMP
-
-
qsql-runner.properties:设置系统参数
-
log4j.properties:设置日志级别
运行示例
QSQL Shell
./bin/qsql -e "select 1"
示例程序
QSQL附带了示例目录中的几个示例程序。要运行其中一个,使用./run-example [params]。例如:
内存表数据:
./bin/run-example com.qihoo.qsql.CsvScanExample
Hive join MySQL:
./bin/run-example com.qihoo.qsql.CsvJoinWithEsExample
注意
./run-example <com.qihoo.qsql.CsvJoinWithEsExample>
运行混算,请确保当前客户端存在Spark、Hive、MySQL环境。并且将Hive与MySQL的连接信息添加到元数据管理中。
参数配置
环境变量
| Property Name | Meaning |
|---|---|
| JAVA_HOME | Java的安装路径 |
| SPARK_HOME | Spark的安装路径 |
| QSQL_CLUSTER_URL | Hadoop集群的路径 |
| QSQL_HDFS_TMP | 设置临时目录路径 |
| QSQL_DEFAULT_WORKER_NUM | 设置初始化的Worker数量 |
| QSQL_DEFAULT_WORKER_MEMORY | 设置每个Worker分配的内存 |
| QSQL_DEFAULT_DRIVER_MEMORY | 设置Driver端分配的内存 |
| QSQL_DEFAULT_MASTER | 设置运行时的集群模式 |
| QSQL_DEFAULT_RUNNER | 设置运行时的执行计划 |
参数配置
应用程序参数
| Property Name | Default | Meaning |
|---|---|---|
| spark.sql.hive.metastore.jars | builtin | Spark Sql链接hive需要的jar包 |
| spark.sql.hive.metastore.version | 1.2.1 | Spark Sql链接hive的版本信息 |
| spark.local.dir | /tmp | Spark执行过程中的临时文件存放路径 |
| spark.driver.userClassPathFirst | true | Spark执行过程中,用户jar包优先加载 |
| spark.sql.broadcastTimeout | 300 | Spark广播的超时时间 |
| spark.sql.crossJoin.enabled | true | Spark Sql开启cross join |
| spark.speculation | true | Spark开启任务推测执行 |
| spark.sql.files.maxPartitionBytes | 134217728(128MB) | Spark读取文件时单个分区的最大字节数 |
元数据参数
| Property Name | Default | Meaning |
|---|---|---|
| meta.storage.mode | intern | 元数据存储模式,intern:读取内置sqlite数据库中存储的元数据,extern:读取外部数据库中存储的元数据。 |
| meta.intern.schema.dir | ../metastore/schema.db | 内置数据库的路径 |
| meta.extern.schema.driver | (none) | 外部数据库的驱动 |
| meta.extern.schema.url | (none) | 外部数据库的链接 |
| meta.extern.schema.user | (none) | 外部数据库的用户名 |
| meta.extern.schema.password | (none) | 外部数据库的密码 |
元数据管理
表结构
DBS
| 表字段 | 说明 | 示例数据 |
|---|---|---|
| DB_ID | 数据库ID | 1 |
| DESC | 数据库描述 | es 索引 |
| NAME | 数据库名 | es_profile_index |
| DB_TYPE | 数据库类型 | es、hive、mysql |
DATABASE_PARAMS
| 表字段 | 说明 | 示例数据 |
|---|---|---|
| DB_ID | 数据库ID | 1 |
| PARAM_KEY | 参数名 | UserName |
| PARAM_VALUE | 参数值 | root |
TBLS
| 表字段 | 说明 | 示例数据 |
|---|---|---|
| TBL_ID | 表ID | 101 |
| CREATED_TIME | 创建时间 | 2018-10-22 14:36:10 |
| DB_ID | 数据库ID | 1 |
| TBL_NAME | 表名 | student |
COLUMNS
| 表字段 | 说明 | 示例数据 |
|---|---|---|
| CD_ID | 字段信息ID | 10101 |
| COMMENT | 字段注释 | 学生姓名 |
| COLUMN_NAME | 字段名 | name |
| TYPE_NAME | 字段类型 | varchar |
| INTEGER_IDX | 字段顺序 | 1 |
内置SQLite数据库
在QSQL发布包$QSQL_HOME/metastore目录中,存在如下文件:
-
sqlite3:SQLite命令行工具
-
schema.db:内置元数据数据库
-
./linux-x86/sqldiff:显示SQLite数据库之间的差异的命令行程序
-
./linux-x86/sqlite3_analyzer:用于测量和显示单个表和索引对SQLite数据库文件使用多少空间以及如何有效地使用空间
通过sqlite3连接到schema.db数据库,并操作元数据表
sqlite3 ../schema.db
外部MySQL数据库
修改内嵌的SQLite数据为MySQL数据库
vim metadata.properties > meta.storage.mode=extern > meta.extern.schema.driver = com.mysql.jdbc.Driver > meta.extern.schema.url = jdbc:mysql://ip:port/db?useUnicode=true > meta.extern.schema.user = YourName > meta.extern.schema.password = YourPassword
初始化示例数据到MySQL数据库中
cd $QSQL_HOME/bin/ ./metadata --dbType mysql --action init
-
quicksql是360开源出来的可以跨数据源进行sql操作的计算框架. 底层使用spark/flink实现. 下载 quicksql安装包 https://github.com/Qihoo360/Quicksql/tree/branch-0.7 解压缩安装包 cd /data/qsql/opt tzr -zxvf qsql-0.7.0.tar.gz cd qsql-0.7.0
-
根据官方文档结合自己部署过程整理 配置依赖环境 Quicksql部署非常简单,首先需要确保环境预置完整,依赖的环境有: Java>=1.8 Spark>=2.2(必选,未来作为可选) Flink>=1.9(可选) 当前的Quicksql对Flink的支持并不完善,还需要进行二次开发,部署演示的示例基于Spark-2.4.6进行 配置qsql 下载并解压二进制安装包,下载地址:https://git
-
一、配置双数据源 因为qsql-server会根据runnerType来判断,如果不配置双数据源的话,到时使用到spark时会出现强制转换错误。 switch (runnerType) { case DEFAULT: resultSet = getJDBCResultSet(h, runner, sql
-
一、错误 java.lang.RuntimeException: java.sql.SQLException: path to '///opt/qsql-0.7.0/../metastore/schema.db': '/opt/qsql-0.7.0/../metastore' does not exist at com.qihoo.qsql.metadata.MetadataClient.cre
-
命令: POST /_sql/translate { "query":"select title,content from knowledge where upCount > 0 order by modifiedOn desc", "fetch_size": 10 } 结果如下: { "size" : 10, "query" : { "range"
-
来源:http://www.w3cschool.cc/sql/sql-quickref.html 是什么? SQL 是用于访问和处理数据库的标准的计算机语言。 重点是访问和处理。 SQL快速参考来源:http://www.w3cschool.cc/sql/sql-quickref.html 是什么? SQL,指结构化查询语言,全称是 Structured Query Language。 SQL 让
-
本节将学习如何从SQL Server数据库查询数据。从一个简单的查询开始,查询语句用于从单个或多个表中检索数据。 SQL是一种特殊目的的编程语言,它是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统;同时也是数据库脚本文件的扩展名。SQL语句无论是种类还是数量都是繁多的,很多语句也是经常要用到的,SQL查询语句就是一个典型的例子,无论是高级查询还是低级查询,SQL查询语
-
我有两个查询,它们都是分开工作的,但是当我尝试统一下摆时,我只有问题。 查询1: 查询 2: 如何根据(内部一)统一它们?
-
所有的查询条件不区分调用顺序,但必须在调用Get,Exist, Sum, Find,Count, Iterate, Rows这几个函数之前调用。同时需要注意的一点是,在调用的参数中,如果采用默认的SnakeMapper所有的字符字段名均为映射后的数据库的字段名,而不是field的名字。
-
我使用注释和注释执行查询,并从数据库表中删除记录。 错误: xxx的例外。xxx。xx,原因='javax。坚持不懈TransactionRequiredException:执行更新/删除查询“和异常=”执行更新/删除查询;嵌套的异常是javax。坚持不懈TransactionRequiredException:执行更新/删除查询'
-
问题内容: 我有一个H2数据库,可以在其中运行某些查询,而另一些则抛出。 例如: 产生此错误消息的原因是什么? 问题答案: 该错误信息的原因是 数据库损坏。 我通过使用H2恢复工具解决了该问题。 步骤如下: 创建恢复脚本 删除旧的db文件(当然,首先要制作备份副本;-) 重新创建数据库 在这里,您可以找到有关H2恢复工具的更详细的使用说明
-
我正在尝试为我的网站创建一个最喜欢的系统。我有一个用户表、作业表和一个收藏夹表。当用户将作业添加到他们的收藏夹中时,他们的用户ID和jobsId将保存到favorites表中。当用户想要查看他们的收藏夹时,我一直试图选择favorites表中与当前用户具有相同userId的所有行。然后,我需要从这些行中选择JobID,并选择job表中具有匹配JobID的所有行。 我一直在尝试这个查询的变体,但没有