
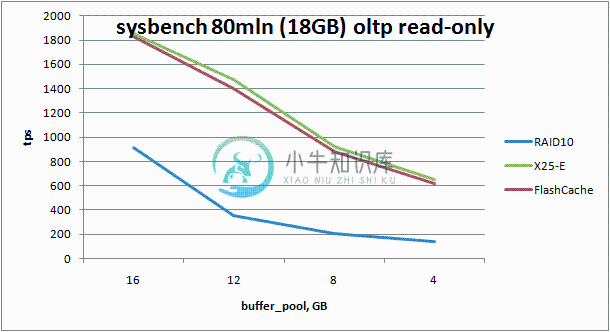
Facebook发布了通过将数据缓存在SSD硬盘加速MySQL的内核模块Flashcache。代码已经放到Github上,目前只测试了Linux kernel版本2.6.18和2.6.20。
Facebook称,Flashcache是其内部开发用于帮助扩展InnoDB/MySQL数据库,但同时Flashcache也是作为一个通用的缓存模块设计的,因此能用在任何搭建在块设备之上的应用程序。对于InnoDB,当工作集不与InnoDB缓冲池一致,由于更多的工作集缓存在快速的媒介如固态硬盘上,将能显著的改进读取延迟。
-
#! /bin/bash # # network Bring up/down fc # # chkconfig: 2345 10 90 # description: Activates/Deactivates all fc # ### BEGIN INIT INFO # Provides: $fc # Should-Start: iptables ip6tables # Short-Descrip
-
可以cache在cell flash cache的对象类型(表 索引 分区 lob字段) SQL> alter table t1 modify lob(blob1) (storage (flash_cache keep)); Table altered. 貌似lob的修改不起作用 SQL> alter table t1 storage(cell_flash_cache none); Tab
-
1 2 3 rpm--import http://elrepo.org/RPM-GPG-KEY-elrepo.org rpm-Uvh http://elrepo.org/elrepo-release-6-5.el6.elrepo.noarch.rpm yum install flashcache-utils kmod-flashcache 2.源码安装 1 2 3 4 5 6 rpm-ivh ht
-
从Oracle 11gR2开始,Oracle终于如大家所预料的那样,开始支持SSD(solid-state disk),该特性允许使用SSD硬盘作为Buffer Cache的二级缓存,以在磁盘和内存之间增加一级缓冲,提升数据访问性能. ●A transparent extension of the database buffer cache using solid-state disk (S
-
exadata的flashcache和flashlog简介 https://blogs.oracle.com/exadatacn/exadata-smart-flash-cache CellCLI> create flashlog all size=512m Flash log slcm05celadm01_FLASHLOG successfully created CellCLI> creat
-
问题描述 我想知道是否有人试图安装和运行使用flashcache或bcache构建的内核进行SSD缓存? 你是怎么做到的? 最佳解决思路 好吧,我们得到了一个bcache答案,但没有flashcache的答案。我之所以选择flashcache是因为我已经有了一个安装,所以bcache是不可能的。对我而言,设置似乎也更容易。我选择了DKMS方法,所以每次进行内核升级时都不会遇到重建模块/工具
-
APPLIES TO: Oracle Exadata Storage Server Software - Version 11.2.3.2.1 and later Information in this document applies to any platform. PURPOSE This document will provide answers to the frequently ask
-
dev.flashcache.fast_remove:删除flashcache卷时不同步脏缓存块。这个选项用来快速删除。 dev.flashcache.zero_stats:统计信息归零。 dev.flashcache.reclaim_policy:缓存回收规则。有两种算法:先进先出FIFO(0),最近最少用LRU(1).默认是FIFO。 dev.flashcache.write_merge:启用
-
flashcache有两种安装方式: 1.普通的编译安装,目前似乎不支持3.x内核 2.动态内核模块编译(DMKS),这种方式相对简单,而且支持3.x高版本内核。 普通编译安装 1.首先安装必要的工具: 编译flashcache的时候需要内核头文件,这里要注意的是: 如果直接使用 yum install kernel-devel 安装的话,可能会导致 内核版本 和 内核头文件 版本不一致,在编
-
flashcache源码详细分析 http://blog.csdn.net/liumangxiong/article/details/11643473 http://blog.csdn.net/liumangxiong/article/details/11681787 http://blog.csdn.net/liumangxiong/article/details/11726651 http:/
-
最近在SuSE Linux Enterprise Server 11 SP3上编译flashcache模块时遇到如下的错误: linux-qzdm:~/facebook-flashcache-9b26cb1 # make KERNEL_TREE=/usr/src/linux-3.0.76-0.11/ fatal: Not a git repository (or any of the paren
-
When users hit the URL of your application they will need to download different assets. CSS, JavaScript, HTML, images and fonts. The great thing about Webpack is that you can stop thinking how you sho
-
ES 内针对不同阶段,设计有不同的缓存。以此提升数据检索时的响应性能。主要包括节点层面的 filter cache 和分片层面的 request cache。下面分别讲述。 filter cache ES 的 query DSL 在 2.0 版本之前分为 query 和 filter 两种,很多检索语法,是同时存在 query 和 filter 里的。比如最常用的 term、prefix、rang
-
我正在使用OpenLayers 3.20开发一个Web应用程序。0,层来自GeoServer,链接到Oracle数据源。此应用程序主要使用ImageWMS层,也使用矢量层进行交互和编辑。问题是地图绘制速度非常慢,绘制了30000多条多段线,我想让这个过程更快:-) 所以我想知道最好的方法是什么。我找到了两种方法: 在ImageWMS层中更改我的矢量层,并仅在选择或编辑时手动加载所需的功能,但它要求
-
我发现CacheService非常快(duh),所以决定创建一个CacheManager来存储所有内容。 JS对象 如果 base64 字符串是 我能够以这种方式在~1.2秒内存储/调用~3MB的原始JSON数据(速度类似于DriveApp API调用) 我尝试搜索可以创建的总缓存对象数的总体限制,但没有找到太多。有没有人知道大量缓存字符串的总体限制或性能下降? 我的“缓存管理器”的源代码 编辑:
-
beego 的 cache 模块是用来做数据缓存的,设计思路来自于 database/sql,目前支持 file、memcache、memory 和 redis 四种引擎,安装方式如下: go get github.com/astaxie/beego/cache 如果你使用memcache 或者 redis 驱动就需要手工安装引入包 go get -u github.com/astaxie/be
-
主要内容:1. 概述,2. Cache,3. CacheKey1. 概述 在优化系统性能时,优化数据库性能是非常重要的一个环节,而添加缓存则是优化数据库时最有效的手段之一。正确、合理地使用缓存可以将一部分数据库请求拦截在缓存这一层。 MyBatis 中提供了一级缓存和二级缓存,而这两级缓存都是依赖于基础支持层中的缓 存模块实现的。这里需要读者注意的是,MyBatis 中自带的这两级缓存与 MyBatis 以及整个应用是运行在同一个 JVM 中的,共享同一块堆
-
在高频的业务场景下,我们可能会频繁的查询数据库获取业务数据,虽然有主键索引的加持,但也不可避免的对数据库性能造成了极大的考验。而对于这种 kv 的查询方式,我们可以很方便的通过使用 模型缓存 来减缓数据库的压力。本组件实现了 Model 数据自动缓存的功能,且当删除和修改模型数据时,自动删除和修改对应的缓存。执行累加、累减操作时,缓存数据自动进行对应累加、累减变更。 模型缓存暂时只支持 Redis
-
本文向大家介绍Android编程使用缓存优化ListView的方法,包括了Android编程使用缓存优化ListView的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Android编程使用缓存优化ListView的方法。分享给大家供大家参考,具体如下: ListView调用Adapter的getView方法获取每一个Item布局,将这些已经获得的Item布局放入缓存,将大大提高获取