
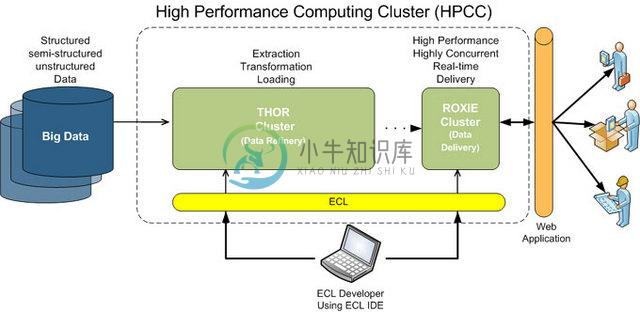
-
原文:http://hpccsystems.com/Why-HPCC/features 翻译:那海蓝蓝,译文请见“ 【】”中的部分 HPCC is a proven and battle-tested platform for manipulating, transforming, querying and data warehousing Big Data. Understand the key
-
我们的新母公司LexisNexis拥有世界上最大的公共记录数据库之一: “…我们从10,000多种不同来源(包括公共,私人,规范和衍生数据)中全面收集了460亿条记录。 您可以获得有关大约2.69亿个人和2.77亿个独立企业的全面信息。” http://www.lexisnexis.com/en-us/products/public-records.page 他们几十年来一直在管理,分析和搜索该数
-
安装运行步骤 下载安装mpich 或者其他MPI实现应该也行,参考网上相关教程,已安装则可以忽略这一步。 下载安装blas wget http://www.netlib.org/blas/blas.tgz tar zxvf blas.tgz cd BLAS-3.8.0/ # sudo apt-get install gfortran 如果没有fortran编译器需要先安装一下gfortran gf
-
HPCC系统需求 System Requirements) HPCC平台需求(HPCC Platform Requirements) 以下需求为社区版HPCC平台与ECL集成开发环境的需求,所有库均基于64位架构(The following system requirements detail what is needed to support the HPCC Platform and ECL
-
CPU Information [xiajing@hostname ~]$ cat /proc/cpuinfo | more processor : 0 vendor_id : GenuineIntel cpu family : 6 model : 45 model name : Intel(R) Xeon(R) CPU E5-2687W 0 @ 3.10GH
-
HPCC 全称 HPC Challenge Benchmark,由一组benchmark组成,共计7个,分别测试了系统7个方面的性能,这7个分别为: stream:测试内存带宽 Random Access:测试内存刷新速率 PTRANS:通过多处理器结构中两两之间的通信,来衡量在整个网络的通信能力 Latency/Bandwidth: 测试延时与带宽 Latency:8 byte 数据从一个节点到
-
搞了快两天,终于在本机上运行了HPCC 性能测试。现在就把HPCC的安装方法给大家分享一下。 1. 改写编译脚本 HPCC 官方给出的运行指导实在是太简单了,根本就没有多大的实用价值。这里还要给大家说一点的就是运行HPCC一定需要MPI,但是没有BLAS也是可以的,或者根据我的经验,使用BLAS反而没法运行HPCC。首先选择一个编译模板,将这个模板改写成我们需要的编译脚本。我选择的编译模板是“Ma
-
HPCC branchmark测试使用 在使用过程中参考了在ubuntu下测试本机的HPCC分数这一篇博文。由于我的环境和这篇文章有所不同,该测试是在学校的超级计算机上完成的,相关配置有所差别。 1. 下载 在HPC Chellenge下载对应的源文件hpcc-1.x.x.tar.gz。将安装包传输到超级计算机对应的个人文件夹下。 使用命令行在合适的位置解压文件 tar xzvf hpcc.1.x
-
问题内容: 在大约2011年3月,我测试了GAE(Java版本)作为大规模并行计算的潜在平台。该日期很重要,因为GAE一直在发展。我发现该应用程序被有效地限制在大约43.2倍的计算吞吐量上。 是否有人成功使用GAE进行大规模并行计算或获得了更高的计算增益? 出于这个问题的目的,我将任意定义大规模并行计算,以表示大于1000倍的计算吞吐量。 我使用了一个桌面客户端,该客户端实例化了多个线程来访问UR
-
问题内容: 我对使用计算机集群运行Python程序感兴趣。过去我一直在使用Python MPI接口,但是由于在编译/安装这些接口时遇到困难,我更喜欢使用内置模块(例如Python的多处理模块)的解决方案。 我真正想做的就是设置一个跨整个计算机集群的实例,并运行一个。这是可能/容易做到的事情吗? 如果这不可能,那么我至少希望能够从中央脚本在每个节点上为每个节点使用不同参数来启动实例。 问题答案: 如
-
校验者: @文谊 翻译者: @ゞFingヤ 对于一些应用程序,需要被处理的样本数量,特征数量(或两者)和/或速度这些对传统的方法而言非常具有挑战性。在这些情况下,scikit-learn 有许多你值得考虑的选项可以使你的系统规模化。 6.1. 使用外核学习实例进行拓展 外核(或者称作 “外部存储器”)学习是一种用于学习那些无法装进计算机主存储(RAM)的数据的技术。 这里描述了一种为了实现这一目的
-
9.3 并行计算* 计算思维是建立在计算机的能力和限制之上的,计算机科学家的任务是尽量发扬计算机 的能力,避开计算机的限制。传统的计算概念是在计算机发明之初形成的,就是由一个处理 器按顺序执行一个程序的所有指令。并行计算则突破了这种限制,试图让多个处理器同时做 事情。并行计算的好处是显然的,想想一个人吃一锅饭与一百个人同时吃一锅饭的差别,就 能理解并行计算的威力。 可以在不同层次上讨论并行。最底层
-
你能回答一下吗?我该怎么解决这个?
-
当我使用Spring批处理管理运行长时间运行的批处理作业的多个实例时,它会在达到jobLauncher线程池任务执行程序池大小后阻止其他作业运行。但是从cron中提取多个工作似乎效果不错。下面是作业启动器配置。 Spring批处理管理员Restful API是否使用不同于xml配置中指定的作业启动器?
-
MXNet后端会自动构建计算图。通过计算图,系统可以知道所有计算的依赖关系,并可以选择将没有依赖关系的多个任务并行执行来获得计算性能的提升。例如“异步计算”一节的第一个例子里依次执行了a = nd.ones((1, 2))和b = nd.ones((1, 2))。这两步计算之间并没有依赖关系,因此系统可以选择并行执行它们。 通常,一个运算符会用到所有CPU或单块GPU上全部的计算资源。例如,dot
-
Java标准库中的大多数集合(如ConcurrentLinkedQueue、Concurrent LinkedDequeue和ConcurrntSkipListSet)的文档都附带以下免责声明: 注意,与大多数集合不同,size方法不是一个恒定时间的操作。由于这些集合的异步性质,确定元素的当前数量需要遍历元素,因此如果在遍历过程中修改了集合,可能会报告不准确的结果。 那是什么意思?为什么他们不能保