
Gor 是用 Go 编写的简单 HTTP 流量复制工具,主要是为了从生产服务器返回流量到开发环境。使用 Gor 可以在实际的用户会话中测试代码。
Gor 基础工作流:
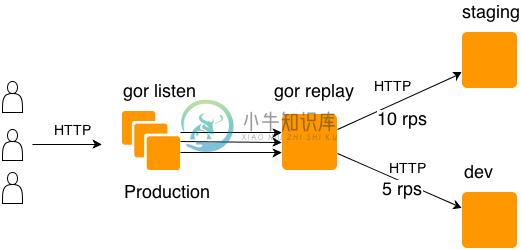
从端口捕获流量:
# Run on servers where you want to catch traffic. You can run it on each `web` machine. sudo gor --input-raw :80 --output-tcp replay.local:28020 # Replay server (replay.local). gor --input-tcp replay.local:28020 --output-http http://staging.com
-
第一次玩go, 准备在linux上搭建个环境, 一起似乎都准备好了, 然后出现: xxxxxx:~> go run me.go FATAL: kernel too old go build command-line-arguments: signal: segmentation fault 晕, 居然嫌弃我linux版本太旧, 我暂时不想升级linux, 也不想再
-
package main import ( "encoding/json" "fmt" "time" "github.com/jinzhu/gorm" _ "github.com/jinzhu/gorm/dialects/mysql" ) var MainDB *gorm.DB func main() { url := "test:123456@tcp(127.0.0.1:33
-
对我来说,这是一项伟大的工程。1年VB,1年C++,最后1年待定。尽管我没有了解过这是否可行,尽管有人可能会笑话我在说大话,但我不在乎。我只按照我的计划踏踏实实尽心尽力地做下去,我觉得这就够了! At least 3 hours for every 7 days and reading book and record to blog.
-
go-metrics介绍 go-metrics — 对Go应用的某个服务做监控、做统计,应用级监控和测量。 源码 : https://github.com/rcrowley/go-metrics 文档:https://pkg.go.dev/github.com/rcrowley/go-metrics Metrics提供5种基本的度量类型:Gauges, Counters, Histograms,
-
一、包管理历史 Golang 的包管理一直被大众所诟病的一个点,但是我们可以看到现在确实是在往好的方向进行发展。下面是官方的包管理工具的发展历史: 在 1.5 版本之前,所有的依赖包都是存放在 GOPATH 下,没有版本控制。这个类似 Google 使用单一仓库来管理代码的方式。这种方式的最大的弊端就是 无法实现包的多版本控制,比如项目 A 和项目 B 依赖于不同版本的 package,如果 pa
-
第一个自己的博客,想过自己做个,但是鉴于技术和时间,一直未能行动,没事常来CSDN逛,那就趋大势吧。 开博第一天。
-
先前在其他的网站也开了几个blog,但是操作起来感觉都不好,现在终于找到了自己心仪的操作界面了,感觉太爽了…… 其实开通blog的本意,并不是为了要写些什么惊天地,泣鬼神的文章来博取高的点击率,用意其实很明确,也很简单——记录下这两年的情感经历,还有平淡而又不平淡的生活故事……
-
大型电商分库分表缓存策略 go的哈希标准库 分库分表模型 shardKey := 1115 // 按店铺搜索就是店铺id, 按什么分表就用什么的id或唯一标识的哈希值 dbMax := 10 // 库数量 tabMax := 100 // 每个库的表数量 // 水平拆分到第middleVal个表 middleVal := shardKey % (dbMax * tabMa
-
GOREPLAY是一个网络流量转发的应用,之前的名字叫GOR,GITHUB上的作者有介绍,更准确说应该是HTTP流量转发,作者的目标应该是WEB型应用在内网的转发,因为HTTP是一个应用广泛的协议,并且是标准的,因此从这个角度出发编写出来的转发应用能够在绝大多数的场景使用。这也会带来一定的问题,假设我们要转发其他的协议类型,这个时候需要自行编码识别协议的边界再做转发。 GOREPLAY使用GO语言
-
1.sql对查询为null的值赋默认值 sqlserver: select isnull(字段,0) from 表名 --这样就是把空值赋值为0 MySQL: select ifnull(字段,0) from 表名 oracle: select nvl(字段,0) from 表名 gorm操作 dsn := "sqlserver://sa:123456@0.0.0.0:1433?dat
-
目录 概述 基于 QPS/并发数的流量控制 基于调用关系的流量控制 概述 流量控制(flow control),其原理是监控应用流量的 QPS 或并发线程数等指标,当达到指定的阈值时对流量进行控制,以避免被瞬时的流量高峰冲垮,从而保障应用的高可用性。 FlowSlot 会根据预设的规则,结合前面 NodeSelectorSlot、ClusterBuilderSlot、StatisticSlot 统
-
缺省情况下,启用了Istio的服务是无法访问外部URL的,这是因为Pod中的iptables把所有外发传输都转向到了Sidecar代理,而这一代理只处理集群内的访问目标。 本节内容会描述如何把外部服务提供给启用了Istio的客户端服务使用,你会学到如何使用Egress规则访问外部服务,或者如何简单的让特定IP范围穿透Istio代理。 开始之前 遵循安装指南设置Istio 启动sleep示例,用于测
-
如控制Egress流量告诉我们可以从服务网格内部应用访问外部(指在Kubernetes外的服务)的 HTTP 和 HTTPS 服务。默认情况下,支持 istio 的应用程序无法直接访问集群外部的 URL 。要启用这种访问,必须先定义 Egress 规则或者配置直接调用外部服务规则。 此任务描述如何配置 Istio 内应用如何访问 Istio 外部的应用。 开始之前 遵循安装指南设置Istio 启动
-
1 背景 在系统访问量较大时,某些库的负载可能非常高,或者因为临时故障或系统bug导致大量异常SQL打到某个库上。为了防止数据库被这些异常流量打垮,需要在数据库访问层上对MySQL进行保护,因此zebra需要提供对某些特定SQL或某个库进行限流的功能。(SQL限流只是用于临时解决问题,事后还需业务方进行优化或扩容) 2 目标 动态限流,可动态配置限流策略与流量大小 支持限制某个数据源上的某些特定的
-
《复制增量》又是一款受到《反物质维度》启发的放置游戏。
-
程序执行流程是指程序语句执行的顺序。 默认情况下,语句会一个接一个地执行。 然而; 很多时候,执行顺序需要从默认顺序改变,以完成任务。 Euphoria有许多flow控制语句,您可以使用它们来安排语句的执行顺序。 exit声明 使用关键字exit退出循环。 这会导致流程立即离开当前循环,并在循环结束后重新开始第一个语句。 语法 (Syntax) exit语句的语法如下 - exit [ "Labe
-
我在处理流时遇到了一些麻烦。本质上,我有一个
-
计算机程序可依据其瓶颈分为磁盘IO瓶颈型,CPU计算瓶颈型,网络带宽瓶颈型,分布式场景下有时候也会外部系统而导致自身瓶颈。 Web系统打交道最多的是网络,无论是接收,解析用户请求,访问存储,还是把响应数据返回给用户,都是要走网络的。在没有epoll/kqueue之类的系统提供的IO多路复用接口之前,多个核心的现代计算机最头痛的是C10k问题,C10k问题会导致计算机没有办法充分利用CPU来处理更多