
DataEase 是人人可用的开源数据可视化分析工具,帮助用户快速分析数据并洞察业务趋势,从而实现业务的改进与优化。DataEase 支持丰富的数据源连接,能够通过拖拉拽方式快速制作图表,并可以方便的与他人分享。
DataEase 的功能:
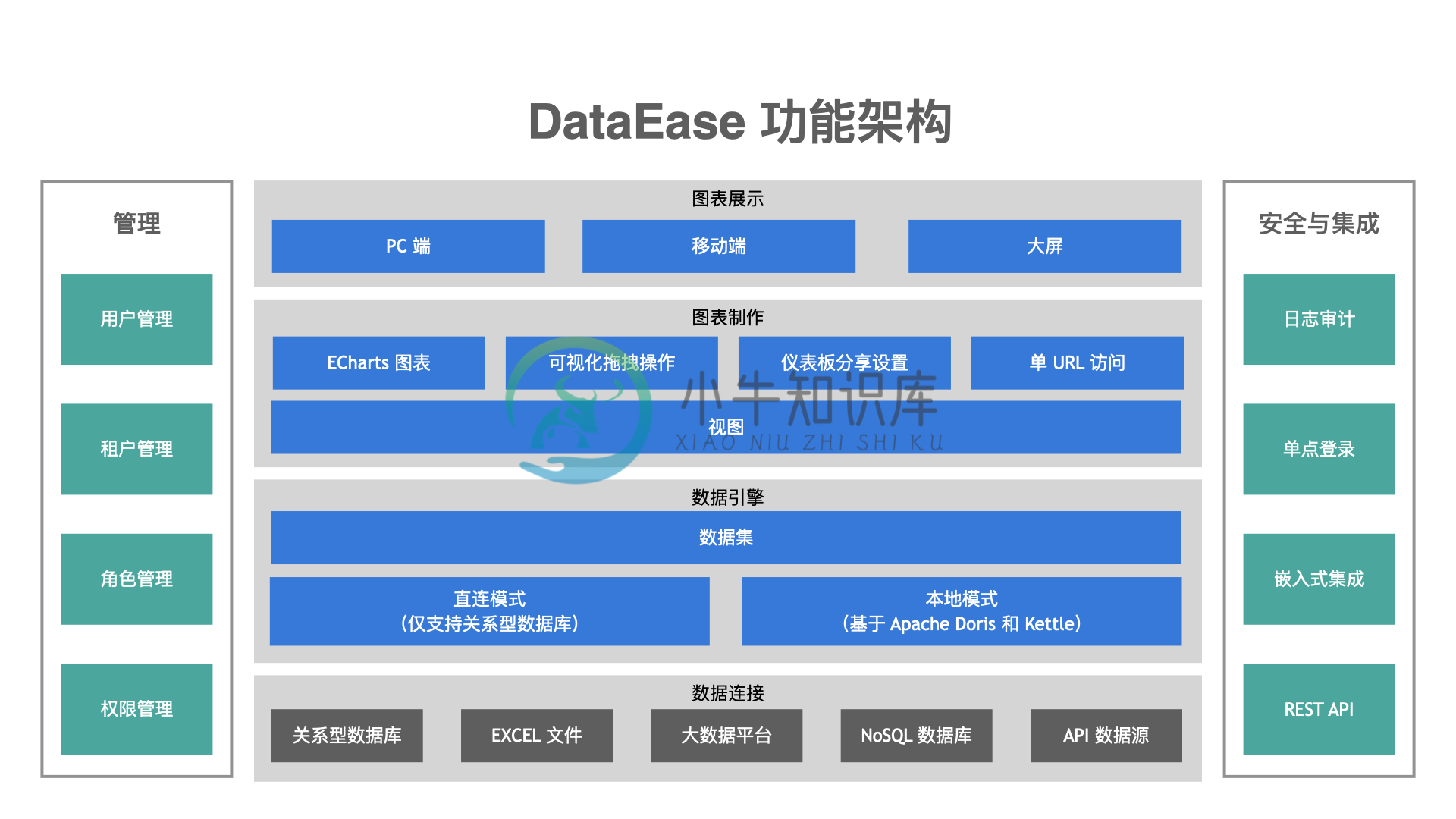
- 图表展示:支持 PC 端、移动端及大屏;
- 图表制作:支持丰富的图表类型(基于 Apache ECharts 实现)、支持拖拉拽方式快速制作仪表板;
- 数据引擎:支持直连模式、本地模式(基于 Apache Doris / Kettle 实现);
- 数据连接:支持关系型数据库、Excel 等文件、Hadoop 等大数据平台、NoSQL 等各种数据源。
DataEase 的优势:
- 开源开放:零门槛,线上快速获取和安装;快速获取用户反馈、按月发布新版本;
- 简单易用:极易上手,通过鼠标点击和拖拽即可完成分析;
- 秒级响应:集成 Apache Doris,超大数据量下秒级查询返回延时;
- 安全分享:支持多种数据分享方式,确保数据安全。
UI 展示
功能架构
在线体验
- 环境地址:https://demo.dataease.io/
- 用户名:demo
- 密码:dataease
快速开始
仅需两步快速安装 DataEase:
- 准备一台不小于 16 G内存的 64位 Linux 主机;
- 以 root 用户执行如下命令一键安装 DataEase。
curl -sSL https://github.com/dataease/dataease/releases/latest/download/quick_start.sh | sh
技术栈
- 后端:Spring Boot
- 前端:Vue.js、Element
- 中间件:MySQL
- 数据处理:Kettle、Apache Doris
- 基础设施:Docker
-
笔者报名参加了DataEase的相关比赛。对于数据可视化来说是一个很不错的产品,且在GitHub上已开源。在配置该产品运行环境时,笔者作为小白遇到了许多问题,目前已解决,记录下来,希望能帮助更多新手顺利使用DataEase。 一、安装教程 1.飞致云知识库:https://kb.fit2cloud.com/archives/macos以非root用户安装dataease 2.知乎相关文章:http
-
近期由于业务需求,需要显示大量明细数据的查询功能,而DataEase目前仅支持客户端分页功能,显示大量明细,一是会导致响应特别慢,二是会导致浏览器内存溢出。为了解决该问题,本人研究了DataEase的源码,并在此基础上增加了服务端分页功能,即少量明细数据显示(1000条)时仍然使用客户端分页功能,全部显示时则使用服务端分页功能。由于本人比较喜欢DataEase v1.8.0的仪表板设
-
1 部署方式 此安装包支持选择部署模式:“精简模式” 和 “集群模式”; 精简模式下仅部署dataease和MySQL,集群模式下将部署dataease、doris-fe、doris-be、kettle、mysql。 在values.yaml中修改: DataEase: enabled: true engine_mode: cluster或simple 2 组件说明 2.1 Doris Do
-
dataease安装 在线安装 curl -sSL https://github.com/dataease/dataease/releases/latest/download/quick_start.sh | sh 配置文件修改 [root@localhost ~]# vim /opt/dataease/.env DE_MYSQL_PASSWORD=Password123@mysql DE_E
-
在处理一组数据时,您通常想做的第一件事就是了解变量的分布情况。本教程的这一章将简要介绍seaborn中用于检查单变量和双变量分布的一些工具。 您可能还需要查看[categorical.html](categorical.html #categical-tutorial)章节中的函数示例,这些函数可以轻松地比较变量在其他变量级别上的分布。 import seaborn as sns import m
-
数据可视化工具 JS 库: d3 sigmajs **部件 & 组件:</h5> Chart.js C3.js Google Charts chartist-jsj amCharts [$] Highcharts [Non-commercial free to $] FusionCharts [$] ZingChart [free to $] Epoch 服务: Datawrapper infog
-
在侧边导航栏点击 Visualize 开始视化您的数据。 Visualize 工具能让您通过多种方式浏览您的数据。例如:我们使用饼图这个重要的可视化控件来查看银行账户样本数据中的账户余额。点击屏幕中间的 Create a visualization 蓝色按钮开始。 有很多种可视化控件可供选择。我们点击其中一个名为 Pie 的。 您可以为已保存的搜索建立可视化效果,或者输入新的搜索条件。使用后者时,
-
本文向大家介绍Highcharts+NodeJS搭建数据可视化平台示例,包括了Highcharts+NodeJS搭建数据可视化平台示例的使用技巧和注意事项,需要的朋友参考一下 前一段时间完成了一个数据可视化项目,由后台NodeJS+Highcharts框架进行搭建。下面分享一下整个开发过程的流程,以及使用Highcharts框架的经验。 一、数据的读取 由于数据库使用的是MySQL数据库,在Nod
-
在现实世界中,我们经常遇到大量原始数据,这些数据不适合机器学习算法。 我们需要在将原始数据输入各种机器学习算法之前对其进行预处理。 本章讨论在Python机器学习中预处理数据的各种技术。 数据预处理 在本节中,让我们了解如何在Python中预处理数据。 最初,在文本编辑器(如记事本)中打开扩展名为.py文件,例如prefoo.py文件。 然后,将以下代码添加到此文件中 - import numpy
-
数据可视化主要旨在借助于图形化手段,清晰有效地传达与沟通信息。 热力图 散点图 动画要素图 高效率点图层 ECharts Mapv OSM Buildings
-
在我们开始的我们的可视化的之旅之前,需要简单的介绍一些数据分析工具,我们的数据可视化的任务也是建立在数据分析的基础之上。Python 的主要数据分析工具如下所示: Numpy:这个是数据计算的工具,主要用来进行矩阵的运算,矢量运算等等。 Scipy:科学计算函数库,主要用在学术领域,主要包含线性代数模块,信号与图像处理模块,统计学模块等等。 Sympy:数学符号计算库 Pandas:包含了 num
-
问题内容: 当我创建一个新会话并告诉可视化分析器启动 python/pycuda脚本我得到以下错误消息: 以下是我的偏好: 启动: 工作目录: 参数: 我在ubuntu10.10下使用cuda4.0。64位。分析编译的示例是有效的。 p、 我知道这个问题[如何在 Linux系统?](https://stackoverflow.com/questions/5317691/how-to-profile