
BeetlSQL的目标是提供开发高效,维护高效,运行高效的数据库访问框架,在一个系统多个库的情况下,提供一致的编写代码方式。支持如下数据平台
- 传统数据库:MySQL (包括支持MySQL协议的各种数据库), MariaDB ,Oralce ,Postgres (包括支持 Postgres 协议的各种数据库), DB2 , SQL Server ,H2 , SQLite , Derby ,神通,达梦,华为高斯,人大金仓,PolarDB,GBase8s,GreatSQL 等
- 大数据:HBase,ClickHouse,Cassandar,Hive
- 物联网时序数据库:Machbase,TD-Engine,IotDB
- SQL查询引擎:Drill,Presto,Druid
- 内存数据库:ignite,CouchBase
BeetlSQL 不仅仅是简单的类似MyBatis或者是Hibernate,或者是俩着的综合,BeetlSQL目的是对标甚至超越Spring Data,是实现数据访问统一的框架,无论是传统数据库,还是大数据,还是查询引擎或者时序库,内存数据库。
BeetlSQL3 性能测试
测试维度是ops/ms,每毫秒的调用次数
Benchmark Mode Cnt Score Error Units
JMHMain.beetlsqlComplexMapping thrpt 5 212.378 ± 26.222 ops/ms
JMHMain.beetlsqlExecuteJdbc thrpt 5 428.713 ± 66.192 ops/ms
JMHMain.beetlsqlExecuteTemplate thrpt 5 374.943 ± 20.214 ops/ms
JMHMain.beetlsqlFile thrpt 5 433.001 ± 65.448 ops/ms
JMHMain.beetlsqlInsert thrpt 5 236.244 ± 112.102 ops/ms
JMHMain.beetlsqlLambdaQuery thrpt 5 247.289 ± 19.310 ops/ms
JMHMain.beetlsqlOne2Many thrpt 5 108.132 ± 10.934 ops/ms
JMHMain.beetlsqlPageQuery thrpt 5 203.751 ± 9.395 ops/ms
JMHMain.beetlsqlSelectById thrpt 5 393.437 ± 15.685 ops/ms
JMHMain.jdbcExecuteJdbc thrpt 5 1083.310 ± 80.947 ops/ms
JMHMain.jdbcInsert thrpt 5 308.341 ± 231.163 ops/ms
JMHMain.jdbcSelectById thrpt 5 1019.370 ± 92.946 ops/ms
JMHMain.jpaExecuteJdbc thrpt 5 94.600 ± 15.624 ops/ms
JMHMain.jpaExecuteTemplate thrpt 5 133.017 ± 12.954 ops/ms
JMHMain.jpaInsert thrpt 5 81.232 ± 26.971 ops/ms
JMHMain.jpaOne2Many thrpt 5 101.506 ± 11.301 ops/ms
JMHMain.jpaPageQuery thrpt 5 117.748 ± 4.512 ops/ms
JMHMain.jpaSelectById thrpt 5 335.945 ± 27.186 ops/ms
JMHMain.mybatisComplexMapping thrpt 5 102.402 ± 11.129 ops/ms
JMHMain.mybatisExecuteTemplate thrpt 5 202.619 ± 16.978 ops/ms
JMHMain.mybatisFile thrpt 5 151.151 ± 4.251 ops/ms
JMHMain.mybatisInsert thrpt 5 141.469 ± 43.092 ops/ms
JMHMain.mybatisLambdaQuery thrpt 5 15.558 ± 1.481 ops/ms
JMHMain.mybatisPageQuery thrpt 5 63.705 ± 7.592 ops/ms
JMHMain.mybatisSelectById thrpt 5 197.130 ± 19.461 ops/ms
JMHMain.weedExecuteJdbc thrpt 5 416.941 ± 22.256 ops/ms
JMHMain.weedExecuteTemplate thrpt 5 439.266 ± 57.130 ops/ms
JMHMain.weedFile thrpt 5 477.561 ± 37.926 ops/ms
JMHMain.weedInsert thrpt 5 231.444 ± 92.598 ops/ms
JMHMain.weedLambdaQuery thrpt 5 422.707 ± 64.716 ops/ms
JMHMain.weedPageQuery thrpt 5 246.018 ± 18.724 ops/ms
JMHMain.weedSelectById thrpt 5 380.348 ± 20.968 ops/ms
代码示例
例子1,内置方法,无需写SQL完成常用操作
UserEntity user = sqlManager.unique(UserEntity.class,1);
user.setName("ok123");
sqlManager.updateById(user);
UserEntity newUser = new UserEntity();
newUser.setName("newUser");
newUser.setDepartmentId(1);
sqlManager.insert(newUser);
输出日志友好,可反向定位到调用的代码
┏━━━━━ Debug [user.selectUserAndDepartment] ━━━
┣ SQL: select * from user where 1 = 1 and id=?
┣ 参数: [1]
┣ 位置: org.beetl.sql.test.QuickTest.main(QuickTest.java:47)
┣ 时间: 23ms
┣ 结果: [1]
┗━━━━━ Debug [user.selectUserAndDepartment] ━━━
例子2 使用SQL
String sql = "select * from user where id=?";
Integer id = 1;
SQLReady sqlReady = new SQLReady(sql,new Object[id]);
List<UserEntity> userEntities = sqlManager.execute(sqlReady,UserEntity.class);
//Map 也可以作为输入输出参数
List<Map> listMap = sqlManager.execute(sqlReady,Map.class);
例子3 使用模板SQL
String sql = "select * from user where department_id=#{id} and name=#{name}";
UserEntity paras = new UserEntity();
paras.setDepartmentId(1);
paras.setName("lijz");
List<UserEntity> list = sqlManager.execute(sql,UserEntity.class,paras);
String sql = "select * from user where id in ( #{join(ids)} )";
List list = Arrays.asList(1,2,3,4,5); Map paras = new HashMap();
paras.put("ids", list);
List<UserEntity> users = sqlManager.execute(sql, UserEntity.class, paras);
例子4 使用Query类
支持重构
LambdaQuery<UserEntity> query = sqlManager.lambdaQuery(UserEntity.class);
List<UserEntity> entities = query.andEq(UserEntity::getDepartmentId,1)
.andIsNotNull(UserEntity::getName).select();
例子5 把数十行SQL放到sql文件里维护
//访问user.md#select
SqlId id = SqlId.of("user","select");
Map map = new HashMap();
map.put("name","n");
List<UserEntity> list = sqlManager.select(id,UserEntity.class,map);
例子6 复杂映射支持
支持像mybatis那样复杂的映射
- 自动映射
@Data
@ResultProvider(AutoJsonMapper.class)
public static class MyUserView {
Integer id;
String name;
DepartmentEntity dept;
}
- 配置映射,比MyBatis更容易理解,报错信息更详细
{
"id": "id",
"name": "name",
"dept": {
"id": "dept_id",
"name": "dept_name"
},
"roles": {
"id": "r_id",
"name": "r_name"
}
}
例子7 最好使用mapper来作为数据库访问类
@SqlResource("user") /*sql文件在user.md里*/
public interface UserMapper extends BaseMapper<UserEntity> {
@Sql("select * from user where id = ?")
UserEntity queryUserById(Integer id);
@Sql("update user set name=? where id = ?")
@Update
int updateName(String name,Integer id);
@Template("select * from user where id = #{id}")
UserEntity getUserById(Integer id);
@SpringData/*Spring Data风格*/
List<UserEntity> queryByNameOrderById(String name);
/**
* 可以定义一个default接口
* @return
*/
default List<DepartmentEntity> findAllDepartment(){
Map paras = new HashMap();
paras.put("exlcudeId",1);
List<DepartmentEntity> list = getSQLManager().execute("select * from department where id != #{exlcudeId}",DepartmentEntity.class,paras);
return list;
}
/**
* 调用sql文件user.md#select,方法名即markdown片段名字
* @param name
* @return
*/
List<UserEntity> select(String name);
/**
* 翻页查询,调用user.md#pageQuery
* @param deptId
* @param pageRequest
* @return
*/
PageResult<UserEntity> pageQuery(Integer deptId, PageRequest pageRequest);
@SqlProvider(provider= S01MapperSelectSample.SelectUserProvider.class)
List<UserEntity> queryUserByCondition(String name);
@SqlTemplateProvider(provider= S01MapperSelectSample.SelectUs
List<UserEntity> queryUserByTemplateCondition(String name);
@Matcher /*自己定义个Matcher注解也很容易*/
List<UserEntity> query(Condition condition,String name);
}
你看到的这些用在Mapper上注解都是可以自定义,自己扩展的
例子8 使用Fetch 注解
可以在查询后根据Fetch注解再次获取相关对象,实际上@FetchOne和 @FetchMany是自定义的,用户可自行扩展
@Data
@Table(name="user")
@Fetch
public static class UserData {
@Auto
private Integer id;
private String name;
private Integer departmentId;
@FetchOne("departmentId")
private DepartmentData dept;
}
/**
* 部门数据使用"b" sqlmanager
*/
@Data
@Table(name="department")
@Fetch
public static class DepartmentData {
@Auto
private Integer id;
private String name;
@FetchMany("departmentId")
private List<UserData> users;
}
例子9 不同数据库切换
可以自行扩展ConditionalSQLManager的decide方法,来决定使用哪个SQLManager
SQLManager a = SampleHelper.init();
SQLManager b = SampleHelper.init();
Map<String, SQLManager> map = new HashMap<>();
map.put("a", a);
map.put("b", b);
SQLManager sqlManager = new ConditionalSQLManager(a, map);
//不同对象,用不同sqlManager操作,存入不同的数据库
UserData user = new UserData();
user.setName("hello");
user.setDepartmentId(2);
sqlManager.insert(user);
DepartmentData dept = new DepartmentData();
dept.setName("dept");
sqlManager.insert(dept);
使用注解 @TargetSQLManager来决定使用哪个SQLManger
@Data
@Table(name = "department")
@TargetSQLManager("b")
public static class DepartmentData {
@Auto
private Integer id;
private String name;
}
例子10 如果想给每个sql语句增加一个sqlId标识
这样好处是方便数据库DBA与程序员沟通
public static class SqlIdAppendInterceptor implements Interceptor{
@Override
public void before(InterceptorContext ctx) {
ExecuteContext context = ctx.getExecuteContext();
String jdbcSql = context.sqlResult.jdbcSql;
String info = context.sqlId.toString();
//为发送到数据库的sql增加一个注释说明,方便数据库dba能与开发人员沟通
jdbcSql = "/*"+info+"*/\n"+jdbcSql;
context.sqlResult.jdbcSql = jdbcSql;
}
}
例子11 代码生成框架
可以使用内置的代码生成框架生成代码何文档,也可以自定义的,用户可自行扩展SourceBuilder类
List<SourceBuilder> sourceBuilder = new ArrayList<>();
SourceBuilder entityBuilder = new EntitySourceBuilder();
SourceBuilder mapperBuilder = new MapperSourceBuilder();
SourceBuilder mdBuilder = new MDSourceBuilder();
//数据库markdown文档
SourceBuilder docBuilder = new MDDocBuilder();
sourceBuilder.add(entityBuilder);
sourceBuilder.add(mapperBuilder);
sourceBuilder.add(mdBuilder);
sourceBuilder.add(docBuilder);
SourceConfig config = new SourceConfig(sqlManager,sourceBuilder);
//只输出到控制台
ConsoleOnlyProject project = new ConsoleOnlyProject();
String tableName = "USER";
config.gen(tableName,project);
例子13 定义一个Beetl函数
GroupTemplate groupTemplate = groupTemplate();
groupTemplate.registerFunction("nextDay",new NextDayFunction());
Map map = new HashMap();
map.put("date",new Date());
String sql = "select * from user where create_time is not null and create_time<#{nextDay(date)}";
List<UserEntity> count = sqlManager.execute(sql,UserEntity.class,map);
nextDay函数是一个Beetl函数,非常容易定义,非常容易在sql模板语句里使用
public static class NextDayFunction implements Function {
@Override
public Object call(Object[] paras, Context ctx) {
Date date = (Date) paras[0];
Calendar c = Calendar.getInstance();
c.setTime(date);
c.add(Calendar.DAY_OF_YEAR, 1); // 今天+1天
return c.getTime();
}
}
例子14 更多可扩展的例子
根据ID或者上下文自动分表,toTable是定义的一个Beetl函数,
static final String USER_TABLE="${toTable('user',id)}";
@Data
@Table(name = USER_TABLE)
public static class MyUser {
@AssignID
private Integer id;
private String name;
}
定义一个Jackson注解,@Builder是注解的注解,表示用Builder指示的类来解释执行,可以看到BeetlSQL的注解可扩展性就是来源于@Build注解
@Retention(RetentionPolicy.RUNTIME)
@Target(value = {ElementType.METHOD, ElementType.FIELD})
@Builder(JacksonConvert.class)
public @interface Jackson {
}
定义一个@Tenant 放在POJO上,BeetlSQL执行时候会给SQL添加额外参数,这里同样使用了@Build注解
/**
* 组合注解,给相关操作添加额外的租户信息,从而实现根据租户分表或者分库
*/
@Retention(RetentionPolicy.RUNTIM@
@Target(value = {ElementType.TYPE})
@Builder(TenantContext.class)
public @interface Tenant {
}
使用XML而不是JSON作为映射
@Retention(RetentionPolicy.RUNTIME)
@Target(value = {ElementType.TYPE})
@Builder(ProviderConfig.class)
public @interface XmlMapping {
String path() default "";
}
参考源码例子 PluginAnnotationSample了解如何定义自定的注解,实际上BeetlSQL有一半的注解都是通过核心注解扩展出来的
BeetlSQL的架构
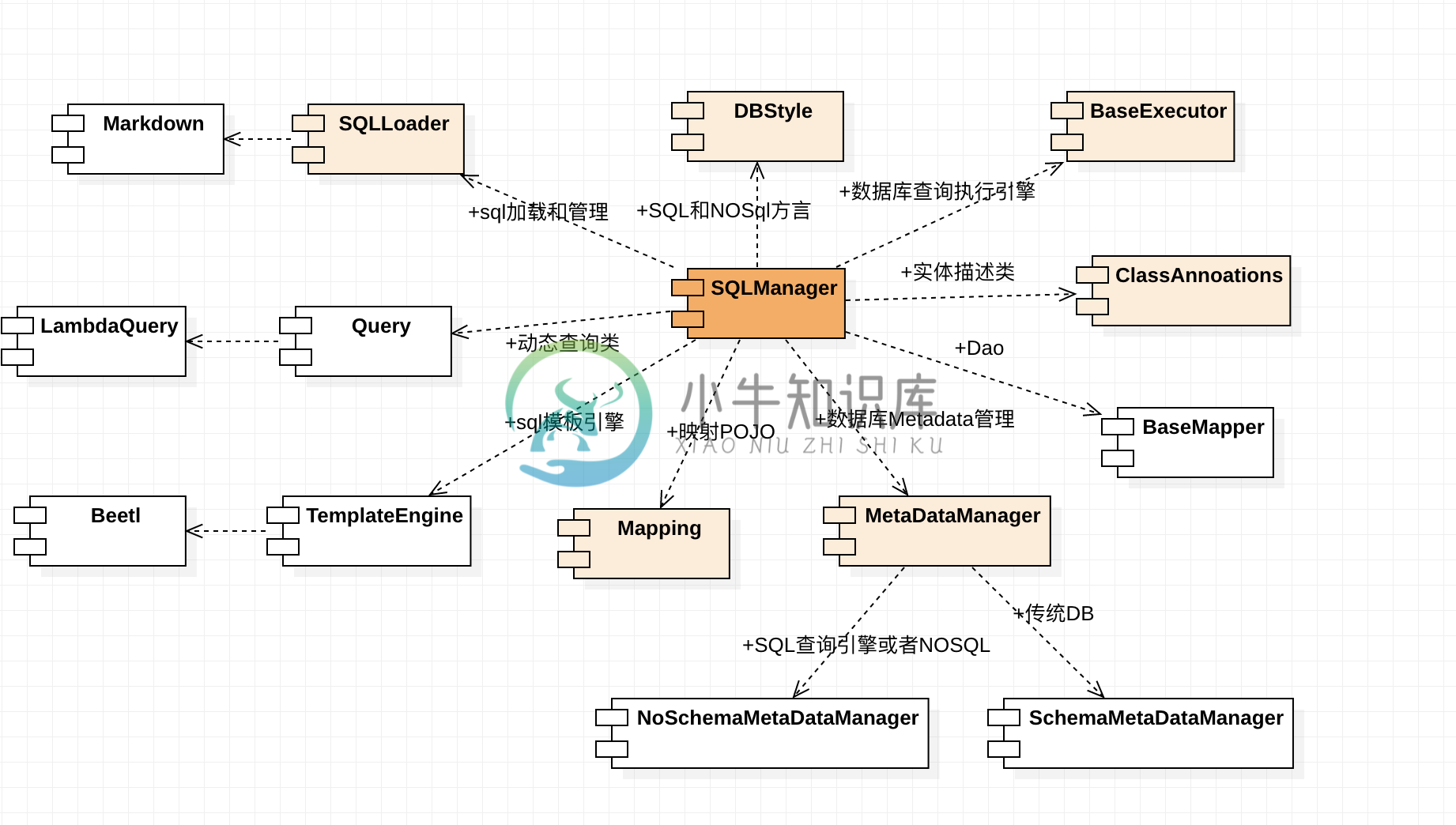
除了SQLManager和ClassAnnoations,任何一部分都可以扩展
-
转载自 Beetlsql自学笔记_我“爱”java的博客-CSDN博客_beetlsql 自用为主,beetlsql是现在实习公司里用的,官网的文档有点乱。。然后找到了个比较好的文档,大部分来源于那篇文档,不过这里也加入了一些我自己的理解 1、简介 BeetlSql是一个数据访问框架,目标是提供开发敏捷,维护边界,运行告诉的数据库访问框架,目标是代替传统的JPA、Mybatis、Hibernate
-
前言 因本人项目需要接触了一下国内一款ORM框架,感觉用着很爽,项目易于管理,特此介绍一下。详情请点解下方官网: BeetlSql官网 BeetlSql是什么 BeetlSQL 是一个全功能 DAO 工具,同时具有 Hibernate 优点 & Mybatis 优点功能,适用于承认以 SQL 为中心,同时又需求工具能自动能生成大量常用的 SQL 的应用。 BeetlSql优点 BeetSql是一个
-
package beetlsql; import java.io.InputStream; import java.util.Date; import java.util.List; import java.util.Properties; import org.beetl.sql.core.ClasspathLoader; import org.beetl.sql.core.Connecti
-
## SpringBoot-整合Beetlsql及多数据源整理 1.引入Beetlsql包 <dependency> <groupId>com.ibeetl</groupId> <artifactId>beetl-framework-starter-</artifactId> <version>1.2.30.RELEASE</version> </dependency> 2
-
本文转载自CSDN博主「象在舞」的博文BeetlSql中的Mapper BeetlSql中的Mapper 本文参考BeetlSql官方网站,官网网站请点击这里~ 一、使用Mapper BeetlSql支持Mapper,它可以将sql文件映射到一个interface接口。接口的方法名与sql文件的sqlid一一对应。接口必须实现BaseMapper接口(后面可以自定义一个Base接口),它提供内置的
-
1.beetlsql案例 delete from a where a.org_id_ = #orgId# and index_id_ in ( @for(id in indexIds){ #id# #text(idLP.last?"":",")# @} ) sql中orgId为一个普通变量,indexIds为一个数据集合 @for(id in indexIds){
-
我正在Eclipse Neon中使用Hibernate工具(JBoss tools 4.4.0.Final)。现在,我想将数据库表反向工程为POJO对象和Hibernate映射文件。 我遵循了一些关于如何设置Eclipse来生成POJO对象的教程。在我运行配置之前,一切看起来都很好。什么都没发生,也没有抛出错误。有人能帮我吗?数据库是一个微软SQL服务器2014。 我的逆向工程配置文件看起来像:
-
龙虎牛熊多头合约池 接口名称 long_pool 接口描述 龙虎牛熊多头合约池接口 请求参数 参数名 说明 举例 date 查询日期 2018-08-08 返回参数 参数名 类型 说明 symbol string 品种编码 code string 合约代号 示例代码 from akshare import pro_api pro = pro_api(token="在此处输入您的token,可以通过
-
工具 客户端 客户端分为三种:完整客户端、轻量级客户端和在线客户端。 完整客户端:存储所有的交易历史记录,功能完备; 轻量级客户端:不保存交易副本,交易需要向别人查询; 在线客户端:通过网页模式来浏览第三方服务器提供的服务。 钱包 矿机 专门为“挖矿”设计的硬件,包括基于 GPU 和 ASIC 的芯片。 脚本 比特币交易支持一种比较简单的脚本语言(类 Forth 的栈脚本语言),可以写入 UTXO
-
工具 以下的一些工具可以帮助你自动检查项目中的 Ruby 代码是否符合这份指南。 RuboCop [RuboCop][] 是一个基于本指南的 Ruby 代码风格检查工具。RuboCop 涵盖了本指南相当大的部分,其同时支持 MRI 1.9 和 MRI 2.0,且与 Emacs 整合良好。 RubyMine RubyMine 的代码检查部分基于本指南。
-
10.7. 工具 本章剩下的部分将讨论Go语言工具箱的具体功能,包括如何下载、格式化、构建、测试和安装Go语言编写的程序。 Go语言的工具箱集合了一系列的功能的命令集。它可以看作是一个包管理器(类似于Linux中的apt和rpm工具),用于包的查询、计算包的依赖关系、从远程版本控制系统下载它们等任务。它也是一个构建系统,计算文件的依赖关系,然后调用编译器、汇编器和链接器构建程序,虽然它故意被设计成
-
vse命令行工具 yocode扩展生成器 范例
-
提供各种支付需要的配置生成方法。 配置 <?php use EasyWeChat\Pay\Application; $config = [...]; $app = new Application($config); $utils = $app->getUtils(); 注意 生成支付 JS 配置 有四种发起支付的方式:WeixinJSBridge, JSSDK, 小程序支付, APP We
-
CoreOS 内置了 服务发现,容器管理 工具。 服务发现 CoreOS 的第一个重要组件就是使用 etcd 来实现的服务发现。在 CoreOS 中 etcd 默认以 rkt 容器方式运行。 etcd 使用方法请查看 etcd 章节。 容器管理 第二个组件就是 Docker,它用来运行你的代码和应用。CoreOS 内置 Docker,具体使用请参考本书其他章节。