
keras.utils.to_categorical和one hot格式解析

keras.utils.to_categorical这个方法,源码中,它是这样写的:
Converts a class vector (integers) to binary class matrix.
E.g. for use with categorical_crossentropy.
也就是说它是对于一个类型的容器(整型)的转化为二元类型矩阵。比如用来计算多类别交叉熵来使用的。
其参数也很简单:
def to_categorical(y, num_classes=None): Arguments y: class vector to be converted into a matrix (integers from 0 to num_classes). num_classes: total number of classes.
说的很明白了,y就是待转换容器(其类型为从0到类型数目),而num_classes则是类型的总数。
这样这一句就比较容易理解了:
先通过np生成一个1000*1维的其值为0-9的矩阵,然后再通过keras.utils.to_categorical方法获取成一个1000*10维的二元矩阵。
y_train = keras.utils.to_categorical(np.random.randint(10, size=(1000, 1)), num_classes=10)
说了这么多,其实就是使用onehot对类型标签进行编码。下面的也都是这样解释。
one hot编码是将类别变量转换为机器学习算法易于利用的一种形式的过程。
通过例子可能更容易理解这个概念。
假设我们有一个迷你数据集:
公司名 类别值 价格
VW 1 20000
Acura 2 10011
Honda 3 50000
Honda 3 10000
其中,类别值是分配给数据集中条目的数值编号。比如,如果我们在数据集中新加入一个公司,那么我们会给这家公司一个新类别值4。当独特的条目增加时,类别值将成比例增加。
在上面的表格中,类别值从1开始,更符合日常生活中的习惯。实际项目中,类别值从0开始(因为大多数计算机系统计数),所以,如果有N个类别,类别值为0至N-1.
sklear的LabelEncoder可以帮我们完成这一类别值分配工作。
现在让我们继续讨论one hot编码,将以上数据集one hot编码后,我们得到的表示如下:
VW Acura Honda 价格
1 0 0 20000
0 1 0 10011
0 0 1 50000
0 0 1 10000
简单来说:**keras.utils.to_categorical函数是把类别标签转换为onehot编码(categorical就是类别标签的意思,表示现实世界中你分类的各类别),
而onehot编码是一种方便计算机处理的二元编码。**
补充知识:序列预处理:序列填充之pad_sequences()和one-hot转化之keras.utils.to_categorical()
tensorflow文本处理中,经常会将 padding 和 one-hot 操作共同出现,所以以下两种方法为有效且常用的方法:
一、keras.preprocessing.sequence.pad_sequences()
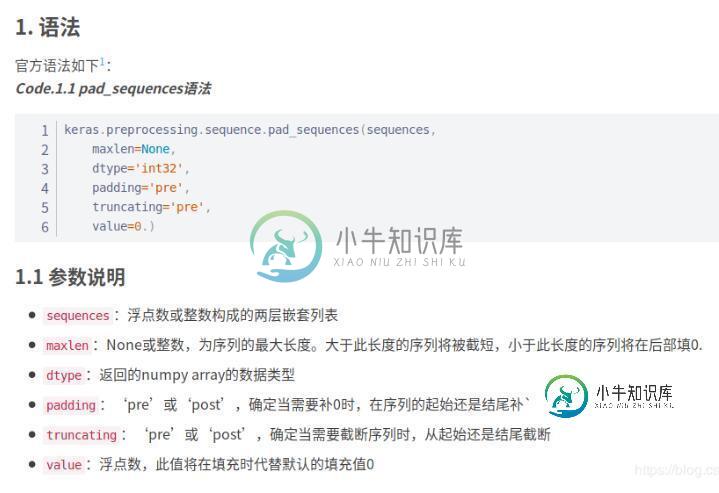
实例:
>>>list_1 = [[2,3,4]] >>>keras.preprocessing.sequence.pad_sequences(list_1, maxlen=10) array([[0, 0, 0, 0, 0, 0, 0, 2, 3, 4]], dtype=int32) >>>list_2 = [[1,2,3,4,5]] >>>keras.preprocessing.sequence.pad_sequences(list_2, maxlen=10) array([[0, 0, 0, 0, 0, 1, 2, 3, 4, 5]], dtype=int32)
二、keras.utils.to_categorical()
to_categorical(y, num_classes=None, dtype='float32')
将整型标签转为onehot。y为int数组,num_classes为标签类别总数,大于max(y)(标签从0开始的)。
返回:如果num_classes=None,返回len(y) * [max(y)+1](维度,m*n表示m行n列矩阵,下同),否则为len(y) * num_classes。说出来显得复杂,请看下面实例。
import keras ohl=keras.utils.to_categorical([1,3]) # ohl=keras.utils.to_categorical([[1],[3]]) print(ohl) """ [[0. 1. 0. 0.] [0. 0. 0. 1.]] """ ohl=keras.utils.to_categorical([1,3],num_classes=5) print(ohl) """ [[0. 1. 0. 0. 0.] [0. 0. 0. 1. 0.]] """
以上这篇keras.utils.to_categorical和one hot格式解析就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持小牛知识库。
-
此代码 导致 Java语言时间总体安排DateTimeParseException:无法分析文本“2020-11-27 01:00”:无法从TemporalAccessor获取OffsetDateTime:{OffsetSeconds=3600},ISO解析为java类型的2020-11-27。时间总体安排已解析 这不管用吗?
-
Go使用模式匹配的方式来支持日期格式化和解析。 package main import "fmt" import "time" func main() { p := fmt.Println // 这里有一个根据RFC3339来格式化日期的例子 t := time.Now() p(t.Format("2006-01-02T15:04:05Z07:00")) /
-
问题内容: 我以不同的形式发布了相同的问题,但没有人回答。我没有清楚了解angular js中Formatter和Parsers的功能。 根据定义,格式化程序和解析器都与我相似。也许我错了,因为我是这个angularjs的新手。 格式化程序定义 每当模型值更改时,作为管道执行的函数数组。 依次调用每个函数,将值传递给下一个。用于格式化/转换值以在控件和验证中显示。 解析器定义 每当控件从DOM读取
-
跨平台的INI解析器:SimpleINI,支持section,读、写、各种value,遍历等。代码有注释. [Code4App.com]
-
我正在尝试将DatePicker日期格式化为简单的数据格式(“yyyy-MM-dd HH: mm: ss Z”)。有人告诉我,我需要使用简单的数据格式将其解析为日期对象-简单的数据格式(“yyyy-MM-dd”),然后将其格式化为我需要的内容,如下所示。但是,我在尝试捕捉块中收到错误“重复局部变量eDate”。任何专家都可以查看我的代码并提出建议吗? 已更新
-
本文向大家介绍浅谈keras中的keras.utils.to_categorical用法,包括了浅谈keras中的keras.utils.to_categorical用法的使用技巧和注意事项,需要的朋友参考一下 如下所示: to_categorical(y, num_classes=None, dtype='float32') 将整型标签转为onehot。y为int数组,num_classes为标