
介绍PostgreSQL中的Lateral类型

PostgreSQL 9.3 用了一种新的联合类型! Lateral联合的推出比较低调,但它实现了之前需要使用编写程序才能获得的强大的新查询. 在本文中, 我将会介绍一个在 PostgreSQL 9.2 不可能被实现的渠道转换分析.
什么是 LATERAL 联合?
对此的最佳描述在文档中 可选 FROM 语句清单 的底部:
LATERAL 关键词可以在前缀一个 SELECT FROM 子项. 这能让 SELECT 子项在FROM项出现之前就引用到FROM项中的列. (没有 LATERAL 的话, 每一个 SELECT 子项彼此都是独立的,因此不能够对其它的 FROM 项进行交叉引用.)
…
当一个 FROM 项包含 LATERAL 交叉引用的时候,查询的计算过程如下: 对于FROM像提供给交叉引用列的每一行,或者多个FROM像提供给引用列的行的集合, LATERAL 项都会使用行或者行的集合的列值来进行计算. 计算出来的结果集像往常一样被加入到联合查询之中. 这一过程会在列的来源表的行或者行的集合上重复进行.
这种计算有一点密集。你可以比较松散的将 LATERAL 联合理解作一个 SQL 的foreach 选择, 在这个循环中 PostgreSQL 将循环一个结果集中的每一行,并将那一行作为参数来执行一次子查询的计算.
我们可以用这个来干些什么?
看看下面这个用来记录点击事件的表结构:
CREATE TABLE event ( user_id BIGINT, event_id BIGINT, time BIGINT NOT NULL, data JSON NOT NULL, PRIMARY KEY (user_id, event_id) )
每一个事件都关联了一个用户,拥有一个ID,一个时间戳,还有一个带有事件属性的JSON blob. 在堆中,这些属性可能包含一次点击的DOM层级, 窗口的标题,会话引用等等信息.
加入我们要优化我们的登录页面以增加注册. 第一步就是要计算看看我们的哪个渠道转换上正在丢失用户.
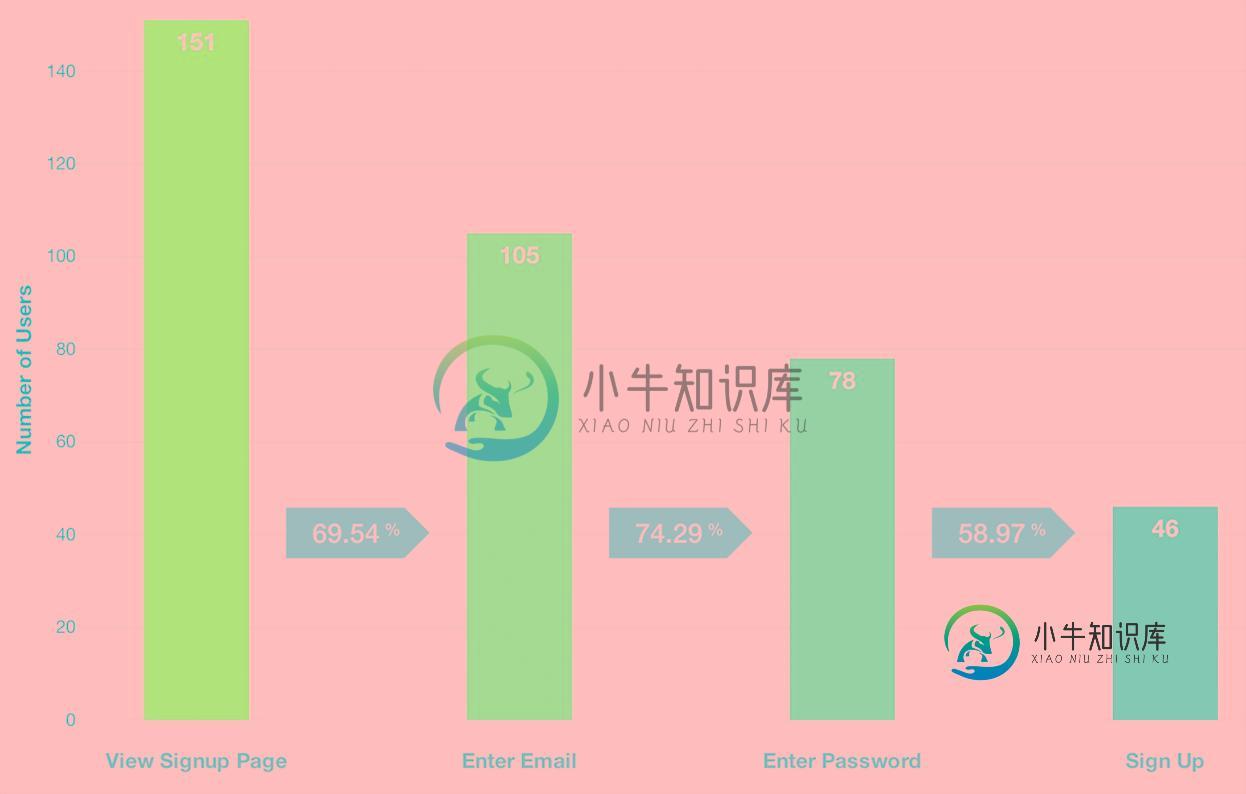
示例:一个注册流程的个步骤之间的渠道转换率.
假设我们已经在前端配备的装置,来沿着这一流程来记录事件日志,所有的数据都会保存到上述的事件数据表中.[1] 最开始的问题是,我们要计算有多少人查看了我们的主页,而他们之中有百分之多少在那次查看了主页之后的两个星期之内输入了验证信息. 如果我们使用 PostgreSQL 较老的版本, 我们可能需要使用PL/pgSQL这一PostgreSQL内置的过程语言 来编写一些定制的函数. 而在 9.3 中, 我们就可以使用一个 lateral 联合,只用一个搞笑的查询就能计算出结果,不需要任何扩展或者 PL/pgSQL.
SELECT user_id, view_homepage, view_homepage_time, enter_credit_card, enter_credit_card_time FROM ( -- Get the first time each user viewed the homepage. SELECT user_id, 1 AS view_homepage, min(time) AS view_homepage_time FROM event WHERE data->>'type' = 'view_homepage' GROUP BY user_id ) e1 LEFT JOIN LATERAL ( -- For each row, get the first time the user_id did the enter_credit_card -- event, if one exists within two weeks of view_homepage_time. SELECT 1 AS enter_credit_card, time AS enter_credit_card_time FROM event WHERE user_id = e1.user_id AND data->>'type' = 'enter_credit_card' AND time BETWEEN view_homepage_time AND (view_homepage_time + 1000*60*60*24*14) ORDER BY time LIMIT 1 ) e2 ON true
没有人会喜欢30多行的SQL查询,所以让我们将这些SQL分成片段来分析。第一块是一段普通的 SQL:
SELECT user_id, 1 AS view_homepage, min(time) AS view_homepage_time FROM event WHERE data->>'type' = 'view_homepage' GROUP BY user_id
也就是要获取到每个用户最开始触发 view_homepage 事件的时间. 然后我们的 lateral 联合就可以让我们迭代结果集的每一行,并会在接下来执行一次参数化的子查询. 这就等同于针对结果集的每一行都要执行一边下面的这个查询:
SELECT 1 AS enter_credit_card, time AS enter_credit_card_time FROM event WHERE user_id = e1.user_id AND data->>'type' = 'enter_credit_card' AND time BETWEEN view_homepage_time AND (view_homepage_time + 1000*60*60*24*14) ORDER BY time LIMIT 1
例如,对于每一个用户,要获取他们在触发 view_homepage_time 事件后的两星期内触发 enter_credit_card 事件的时间. 因为这是一个lateral联合,我们的子查询就可以从之前的子查询出引用到 view_homepage_time 结果集. 否则,子查询就只能单独执行,而没办法访问到另外一个子查询所计算出来的结果集.
之后哦我们整个封装成一个select,它会返回像下面这样的东西:
user_id | view_homepage | view_homepage_time | enter_credit_card | enter_credit_card_time ---------+---------------+--------------------+-------------------+------------------------ 567 | 1 | 5234567890 | 1 | 5839367890 234 | 1 | 2234567890 | | 345 | 1 | 3234567890 | | 456 | 1 | 4234567890 | | 678 | 1 | 6234567890 | | 123 | 1 | 1234567890 | | ...
因为这是一个左联合,所以查询结果集中会有不匹配 enter_credit_card 事件的行,只要有 view_homepage 事件就行. 如果我们汇总所有的数值列,就会得到渠道转换的一个清晰汇总:
SELECT sum(view_homepage) AS viewed_homepage, sum(enter_credit_card) AS entered_credit_card FROM ( -- Get the first time each user viewed the homepage. SELECT user_id, 1 AS view_homepage, min(time) AS view_homepage_time FROM event WHERE data->>'type' = 'view_homepage' GROUP BY user_id ) e1 LEFT JOIN LATERAL ( -- For each (user_id, view_homepage_time) tuple, get the first time that -- user did the enter_credit_card event, if one exists within two weeks. SELECT 1 AS enter_credit_card, time AS enter_credit_card_time FROM event WHERE user_id = e1.user_id AND data->>'type' = 'enter_credit_card' AND time BETWEEN view_homepage_time AND (view_homepage_time + 1000*60*60*24*14) ORDER BY time LIMIT 1 ) e2 ON true
… 它会输出:
viewed_homepage | entered_credit_card -----------------+--------------------- 827 | 10
我们可以向这个渠道中填入带有更多lateral联合的中间步骤,来得到流程中我们需要重点改进的部分. 让我们在查看主页和输入验证信息之间加入对使用示例步骤的查询.
SELECT sum(view_homepage) AS viewed_homepage, sum(use_demo) AS use_demo, sum(enter_credit_card) AS entered_credit_card FROM ( -- Get the first time each user viewed the homepage. SELECT user_id, 1 AS view_homepage, min(time) AS view_homepage_time FROM event WHERE data->>'type' = 'view_homepage' GROUP BY user_id ) e1 LEFT JOIN LATERAL ( -- For each row, get the first time the user_id did the use_demo -- event, if one exists within one week of view_homepage_time. SELECT user_id, 1 AS use_demo, time AS use_demo_time FROM event WHERE user_id = e1.user_id AND data->>'type' = 'use_demo' AND time BETWEEN view_homepage_time AND (view_homepage_time + 1000*60*60*24*7) ORDER BY time LIMIT 1 ) e2 ON true LEFT JOIN LATERAL ( -- For each row, get the first time the user_id did the enter_credit_card -- event, if one exists within one week of use_demo_time. SELECT 1 AS enter_credit_card, time AS enter_credit_card_time FROM event WHERE user_id = e2.user_id AND data->>'type' = 'enter_credit_card' AND time BETWEEN use_demo_time AND (use_demo_time + 1000*60*60*24*7) ORDER BY time LIMIT 1 ) e3 ON true
这样就会输出:
viewed_homepage | use_demo | entered_credit_card -----------------+----------+--------------------- 827 | 220 | 86
从查看主页到一周之内使用demo,再到一周以内向其输入信用卡信息,这就向我们提供了三个步骤的通道转换. 从此,功能强大的 PostgreSQL 使得我们可以深入分析这些数据结果集,并对我们的网站性能进行整体的分析. 接着我们可能会有下面这些问题要解决:
- 使用demo是否能增加注册的可能性?
- 通过广告找到我们主页的用户是否同来自其他渠道的用户拥有相同的转换率?
- 转换率会跟随不同的 A/B 测试变量发生怎样的变化?
这些问题的答案会直接影响到产品的改进,它们可以从 PostgreSQL 数据库中找到答案,因为现在它支持 lateral 联合.
没有 lateral 联合,我们就只能借助 PL/pgSQL 来做这些分析。或者,如果我们的数据集很小,我们可能就不会碰这些复杂、低效的查询. 在一项探索性数据研究使用场景下,你可能只是将数据从 PostgreSQL 里面抽取出来,并使用你所选择的脚本语言来对其进行分析。但是其实还存在更强大的理由来用SQL表述这些问题, 特别是如果你正想要把整个全封装到一套易于理解的UI中,并向非技术型用户发布功能 的时候.
注意这些查询可以被优化,以变得更加高效. 在本例中,如果我们在 (user_id, (data->>'type'), time)上创建一个btree索引, 我们只用一次索引查找就能针对每一个用户计算每一个渠道步骤. 如果你使用的是SSD,在上面做查找花费是很小的,那这就足够了。而如果不是,你就可能需要用稍微不同的手段来图示化你的数据,详细的内容我会留到另外一篇文章之中进行介绍.
-
本文向大家介绍介绍PostgreSQL中的jsonb数据类型,包括了介绍PostgreSQL中的jsonb数据类型的使用技巧和注意事项,需要的朋友参考一下 PostgreSQL 9.4 正在加载一项新功能叫jsonb,是一种新型资料,可以储存支援GIN索引的JSON 资料。换言之,此功能,在即将来临的更新中最重要的是,如果连这都不重要的话,那就把Postgres 置于文件为本数据库系统的推荐位置吧
-
问题内容: 自从Postgres具备进行连接的能力以来,我一直在阅读它,因为我目前为团队执行复杂的数据转储,其中包含许多效率低下的子查询,这些查询使整个查询花费了四分钟或更长时间。 我知道联接可能会为我提供帮助,但是即使从Heap Analytics中阅读了类似这样的文章,我仍然不太了解。 联接的用例是什么?联接和子查询之间有什么区别? 问题答案: 什么 是 一个加入? 该功能是PostgreSQ
-
本文向大家介绍PHP中的类型约束介绍,包括了PHP中的类型约束介绍的使用技巧和注意事项,需要的朋友参考一下 PHP的类方法和函数中可实现类型约束,但参数只能指定类、数组、接口、callable 四种类型,参数可默认为NULL,PHP并不能约束标量类型或其它类型。 如下示例: 那么对于标量类型如何约束呢? PECL扩展库中提供了SPL Types扩展实现interger、float、bool、enu
-
本文向大家介绍PowerShell中的强类型数组介绍,包括了PowerShell中的强类型数组介绍的使用技巧和注意事项,需要的朋友参考一下 在PowerShell中,当我们将一串强类型的值赋给一个变量时,这个变量就成了强类型数组。如果在一个强类型的数组中增加一个非强类型的数组元素(使用“+=”操作符),这时该数组将又变回普通数组。 看看这个例子: 之所以数组又变回为一个普通数组,这是因为要往数组中
-
本文向大家介绍JavaScript中的值类型详细介绍,包括了JavaScript中的值类型详细介绍的使用技巧和注意事项,需要的朋友参考一下 计算机程序的实质很大程度上可以说是机器对各种信息(值)的操作与读写。在JavaScript中,存在多种类型的值,这些值分成两大类:Primitive(基本类型)和Object(对象)。 Primitive JavaScript中Primitive有5种类型:
-
va异常的基类为java.lang.Throwable,java.lang.Error和java.lang.Exception继承 Throwable,RuntimeException和其它的Exception等继承Exception