
python 数据清洗之数据合并、转换、过滤、排序

前面我们用pandas做了一些基本的操作,接下来进一步了解数据的操作,
数据清洗一直是数据分析中极为重要的一个环节。
数据合并
在pandas中可以通过merge对数据进行合并操作。
import numpy as np
import pandas as pd
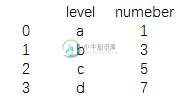
data1 = pd.DataFrame({'level':['a','b','c','d'],
'numeber':[1,3,5,7]})
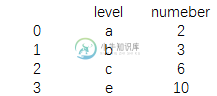
data2=pd.DataFrame({'level':['a','b','c','e'],
'numeber':[2,3,6,10]})
print(data1)
结果为:
print(data2)
结果为:
print(pd.merge(data1,data2))
结果为:
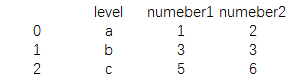
可以看到data1和data2中用于相同标签的字段显示,而其他字段则被舍弃,这相当于SQL中做inner join连接操作。
此外还有outer,ringt,left等连接方式,用关键词how的进行表示。
data3 = pd.DataFrame({'level1':['a','b','c','d'],
'numeber1':[1,3,5,7]})
data4=pd.DataFrame({'level2':['a','b','c','e'],
'numeber2':[2,3,6,10]})
print(pd.merge(data3,data4,left_on='level1',right_on='level2'))
结果为:

两个数据框中如果列名不同的情况下,我们可以通过指定letf_on 和right_on两个参数把数据连接在一起
print(pd.merge(data3,data4,left_on='level1',right_on='level2',how='left'))
结果为:

其他详细参数说明

重叠数据合并
有时候我们会遇到重叠数据需要进行合并处理,此时可以用comebine_first函数。
data3 = pd.DataFrame({'level':['a','b','c','d'],
'numeber1':[1,3,5,np.nan]})
data4=pd.DataFrame({'level':['a','b','c','e'],
'numeber2':[2,np.nan,6,10]})
print(data3.combine_first(data4))
结果为:
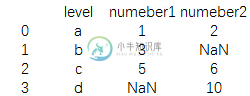
可以看到相同标签下的内容优先显示data3的内容,如果一个数据框中的某一个数据是缺失的,此时另外一个数据框中的元素就会补上
这里的用法类似于np.where(isnull(a),b,a)
数据重塑和轴向旋转
这个内容我们在上一篇pandas文章有提到过。数据重塑主要使用reshape函数,旋转主要使用unstack和stack两个函数。
data=pd.DataFrame(np.arange(12).reshape(3,4),
columns=['a','b','c','d'],
index=['wang','li','zhang'])
print(data)
结果为:

print(data.unstack())
结果为:

数据转换
删除重复行数据
data=pd.DataFrame({'a':[1,3,3,4],
'b':[1,3,3,5]})
print(data)
结果为:

print(data.duplicated())
结果为:

可以看出第三行是重复第二行的数据所以,显示结果为True
另外用drop_duplicates方法可以去除重复行
print(data.drop_duplicates())
结果为:

替换值
除了使用我们上一篇文章中提到的fillna的方法外,还可以用replace方法,而且更简单快捷
data=pd.DataFrame({'a':[1,3,3,4],
'b':[1,3,3,5]})
print(data.replace(1,2))
结果为:
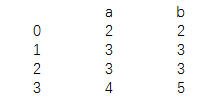
多个数据一起换
print(data.replace([1,4],np.nan))

数据分段
data=[11,15,18,20,25,26,27,24] bins=[15,20,25] print(data) print(pd.cut(data,bins))
结果为:
[11, 15, 18, 20, 25, 26, 27, 24][NaN, NaN, (15, 20], (15, 20], (20, 25], NaN, NaN, (20, 25]]
Categories (2, object): [(15, 20] < (20, 25]]
可以看出分段后的结果,不在分段内的数据显示为na值,其他则显示数据所在的分段。
print(pd.cut(data,bins).labels)
结果为:
[-1 -1 0 0 1 -1 -1 1]
显示所在分段排序标签
print(pd.cut(data,bins).levels)
结果为:
Index([‘(15, 20]', ‘(20, 25]'], dtype='object')
显示所以分段标签
print(value_counts(pd.cut(data,bins)))
结果为:

显示每个分段值得个数
此外还有一个qcut的函数可以对数据进行4分位切割,用法和cut类似。
排列和采样
我们知道排序的方法有好几个,比如sort,order,rank等函数都能对数据进行排序
现在要说的这个是对数据进行随机排序(permutation)
data=np.random.permutation(5) print(data)
结果为:
[1 0 4 2 3]
这里的peemutation函数对0-4的数据进行随机排序的结果。
也可以对数据进行采样
df=pd.DataFrame(np.arange(12).reshape(4,3)) samp=np.random.permutation(3) print(df)
结果为:
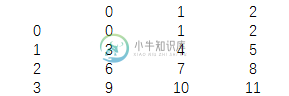
print(samp)
结果为:
[1 0 2]
print(df.take(samp))
结果为:

这里使用take的结果是,按照samp的顺序从df中提取样本。
-
理想中,我们获取的数据都是一样的格式,可是现实中,会有许多脏数据,有时候是数据太冗余,有时候是数据缺失,有时候是同一种类数据拥有不同的数据格式。比如生日,有的人使用阿拉伯数字,有的人使用英文简写,有的人则是加入了中文字符。 如果只是简单的某一列数据问题,我们可以写一个脚本进行处理,可是,当数据太复杂,数据量太大,我们自己编写脚步就太浪费时间和精力了。有没有什么可视化工具,可以像操作Excel表格很
-
本文向大家介绍python数据清洗系列之字符串处理详解,包括了python数据清洗系列之字符串处理详解的使用技巧和注意事项,需要的朋友参考一下 前言 数据清洗是一项复杂且繁琐(kubi)的工作,同时也是整个数据分析过程中最为重要的环节。有人说一个分析项目80%的时间都是在清洗数据,这听起来有些匪夷所思,但在实际的工作中确实如此。数据清洗的目的有两个,第一是通过清洗让数据可用。第二是让数据变的更适合
-
永远不要信任外部输入。请在使用外部输入前进行过滤和验证。filter_var()和 filter_input() 函数可以过滤文本并对格式进行校验(例如 email 地址)。 外部输入可以是任何东西:$_GET 和 $_POST 等表单输入数据,$_SERVER 超全局变量中的某些值,还有通过 fopen('php://input', 'r') 得到的 HTTP 请求体。记住,外部输入的定义并不局
-
本文向大家介绍8段用于数据清洗Python代码(小结),包括了8段用于数据清洗Python代码(小结)的使用技巧和注意事项,需要的朋友参考一下 最近,大数据工程师Kin Lim Lee在Medium上发表了一篇文章,介绍了8个用于数据清洗的Python代码。 数据清洗,是进行数据分析和使用数据训练模型的必经之路,也是最耗费数据科学家/程序员精力的地方。 这些用于数据清洗的代码有两个优点:一是由函数
-
我有一个返回一组文档(100)的查询。我想对这些应用一个聚合,因为这些是最相关的。当我尝试聚合时,它返回所有结果的聚合,而不是前100个结果的聚合。
-
主要内容:限制第一个和最后一个,其他过滤器Firebase提供了多种方式来过滤数据。 限制第一个和最后一个 下面我们来了解第一个和最后一个数据限制是什么。 方法返回从第一个开始向前的指定数量的项目。 方法返回从最后一个开始向前的指定数量的项目。 下面这个例子是展示如何工作的。 由于在数据库中只有三个运动员数据,这里将限制查询返回一个运动员数据。 示例 现在,参考下面的例子 - 控制台会记录第一个查询得到前两个运动员数据,第二个查询得到最后