
java实战CPU占用过高问题的排查及解决

最近一段时间 某台服务器上的一个应用总是隔一段时间就自己挂掉 用top看了看 从重新部署应用开始没有多长时间CPU占用上升得很快
排查步骤
1.使用top 定位到占用CPU高的进程PID
top
2.通过ps aux | grep PID命令
获取线程信息,并找到占用CPU高的线程
ps -mp pid -o THREAD,tid,time | sort -rn
3.将需要的线程ID转换为16进制格式
printf "%x\n" tid
4.打印线程的堆栈信息 到了这一步具体看堆栈的日志来定位问题了
jstack pid |grep tid -A 30
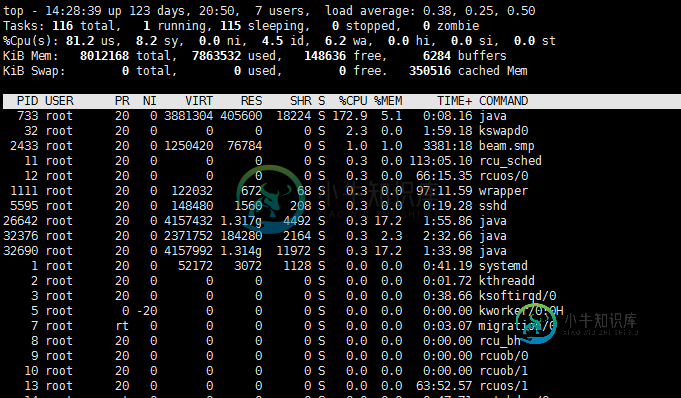
top 可以看出PID 733进程 的占用CPU 172%
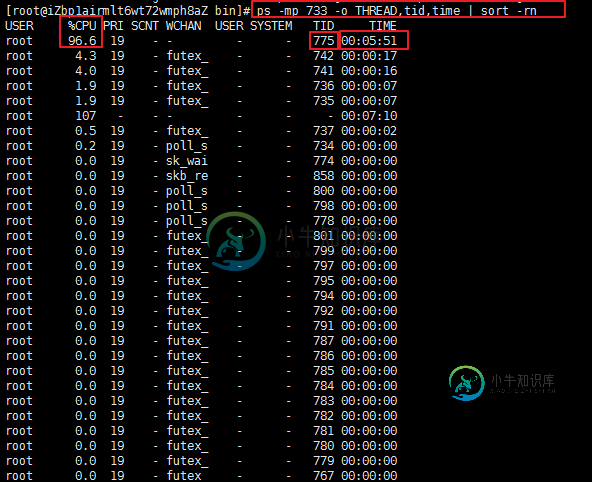
查找进程733下的线程 可以看到TID 线程775占用了96%且持有了很长时间 其实到这一步基本上能猜测到应该是 肯定是那段代码发生了死循环
ps -mp 733 -o THREAD,tid,time | sort -rn
线程ID转换为16进制格式
printf "%x\n" 775

查看java 的堆栈信息
jstack 733 |grep 307 -A 30
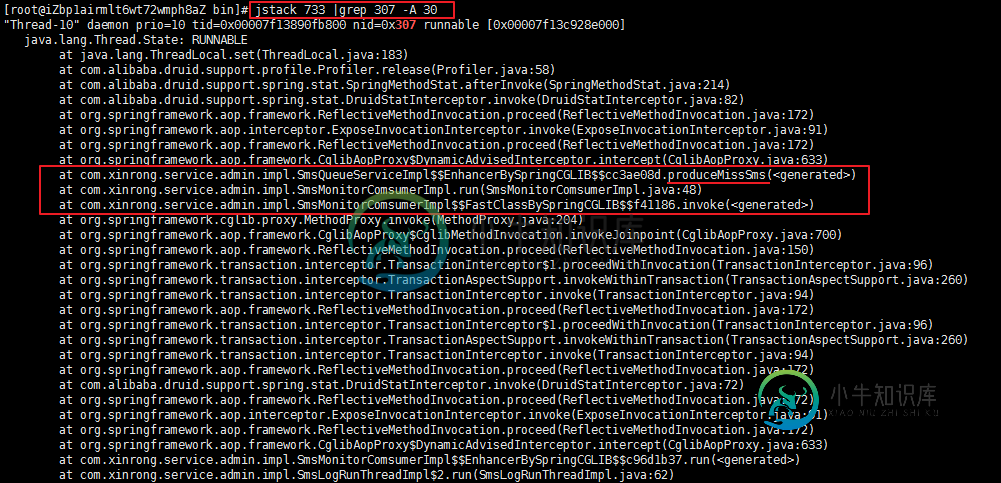
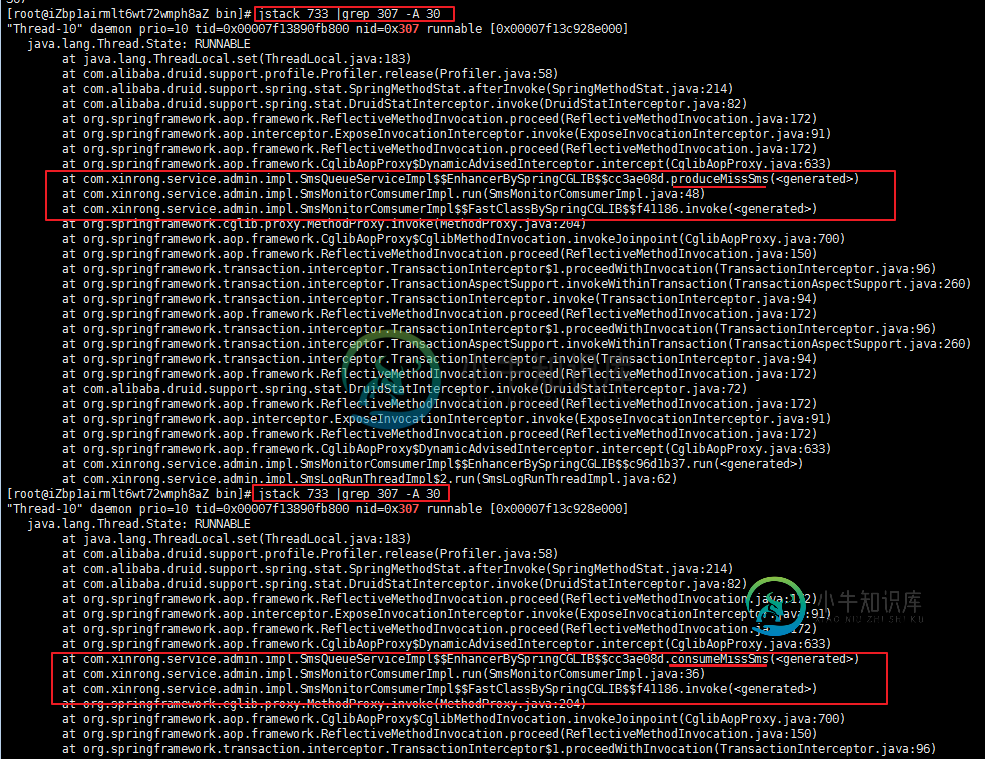
显然是 SmsQueueServiceImpl 中的produceMissSms 和 consumeMissSms 方法有问题
一下为精简的部分代码
/** * Created by dongxc on 2015/7/7. 通知消息队列 */
@Service("smsQueueService")
public class SmsQueueServiceImpl {
// 生产异常队列方法
public void produceMissSms(SmsLogDo smsLogDo) {
/*
* try{ String key = EnumRedisPrefix.SMS_QUEUE_MISS_DEAL.getValue(); boolean result = redisService.lpush(key,
* smsLogDo, 0); if(result==false){ logger.error("通知消息异常队列生产消息返回失败!"+smsLogDo.getId()); } }catch(Exception e){
* logger.error("通知消息异常队列生产消息失败!", e); }
*/
}
// 消费异常队列方法
public SmsLogDo consumeMissSms() {
try {
String destKey = EnumRedisPrefix.SMS_QUEUE_MISS_DEAL.getValue();
SmsLogDo smsLogDo = new SmsLogDo();
Object obj = null;
if (obj == null) {
return null;
} else {
smsLogDo = (SmsLogDo) obj;
}
return smsLogDo;
} catch (Exception e) {
logger.error("通知消息队列消费方法失败!", e);
return null;
}
}
}
从很有年代感的垃圾代码来看 这两个方法并没有什么问题 继续往调用这两个方法的上层排查
/**
* Created by dongxc on 2015/7/7.
* 消息通知监控线程
*/
@Service("smsMonitorComsumer")
public class SmsMonitorComsumerImpl {
@Autowired
private SmsQueueServiceImpl smsQueueService;
//取队列里的任务消费
@Transactional(propagation= Propagation.NOT_SUPPORTED)
public void run() {
while (true) {
try {
SmsLogDo smsLogDo = smsQueueService.consumeMissSms();
Boolean result = false;
if(smsLogDo!=null){
long diff = (new Date()).getTime() - smsLogDo.getSendtime().getTime() ;
long min = diff%(1000*24*60*60)%(1000*60*60)/(1000*60);//计算差多少分钟
if(min>5){
result = true;
}
}
if(result){
smsQueueService.produceSms(smsLogDo);
}else{
smsQueueService.produceMissSms(smsLogDo);
}
} catch (Exception ex) {
try{
Thread.sleep(3000);
}catch(Exception e){
//logger.error("发送站内信息短信时线程执行失败2!", e);
}
}
}
}
}
很显然 这里有一个while(true) 基本定位到问题了 while里面完全是没有用的代码

继续往上层看谁来调用
/**
* Created by dongxc on 2015/7/7.
* 通知消息队列
*/
@Service("smsLogRunThread")
public class SmsLogRunThreadImpl {
public int flag;
@Autowired
private SmsLogConsumerImpl smsLogConsumer;
@Autowired
private SmsMonitorComsumerImpl smsMonitorComsumer;
@PostConstruct
public void init() {
if(ip!=""&&host!=""&&ip.equals(host)){
Thread thread = new Thread(){
public void run() {
smsLogConsumer.run();
}
};
thread.start();
Thread thread1 = new Thread(){
public void run() {
smsMonitorComsumer.run();
}
};
thread1.start();
}
}
}
在应用一启动的时候 spring初始化的就会执行这一段处理丢失消息的代码 然后这段死循环代码 没有任何作用
解决方法 即 注释掉whlie(true)这一段代码
案例一下,其实之前也遇到过CPU占用很高的问题, 但是那次是 频繁的GC导致的
其实排查问题 的过程中也是在不断的学习的过程
-
通过top命令查看到一个占用CPU资源>100%的进程,直接kill掉的话,过几个小时又重启了,查看注册服务也没看到跟这个进程相关的服务,通过lsof -p命令可以看到一下信息: 通过pstree命令可以看到一下信息: 另外,本地仅启动了一个java服务和一个nginx服务。大家可以给出什么建议和方向吗?
-
本文向大家介绍记一次tomcat进程cpu占用过高的问题排查记录,包括了记一次tomcat进程cpu占用过高的问题排查记录的使用技巧和注意事项,需要的朋友参考一下 本文主要记录一次tomcat进程,因TCP连接过多导致CPU占用过高的问题排查记录。 问题描述 linux系统下,一个tomcat web服务的cpu占用率非常高,top显示结果超过200%。请求无法响应。反复重启依然同一个现象。 问题
-
使用的是 2 核的腾讯云轻量服务器,这个 zapppp 进程几乎占用了所有 CPU 资源,有可能是一个挖矿程序,使用常规的方法都无法终结这个进程。前几天收到邮件说服务器的 22 端口存在攻击行为,我怀疑是攻击者通过破解 ssh 登录密码登录到服务器然后植入恶意程序。 请问一下如何完整地修复这个问题?
-
nuxt3构建的项目,开多个网页之后,一开始没事,然后停留一段时间,发现占用CPU过高,然后使用性能录制了占用过高一段时间的记录,如下两张图,发现定时器在很短的时间零点几毫秒的间隔就执行了,但是程序中并未设置这么短的时间
-
我安装了WSL2与WSLg(能够成功启动gimp), 然后开启了我的工程项目(一生一芯), 其中有一部分是启动一个图形化程序,在使用top命令观察后, 发现其CPU占用达100%, 内存占用倒不是很大 1.有同学在WSL2中使用该程序, 运行流畅没有问题 2.电脑配置为i7-12700KF+3060Ti 3.运行gimp时CPU占用大概12%左右 4.WSL2的配置主要是针对Memory和Swap
-
本文向大家介绍PyTorch 随机数生成占用 CPU 过高的解决方法,包括了PyTorch 随机数生成占用 CPU 过高的解决方法的使用技巧和注意事项,需要的朋友参考一下 PyTorch 随机数生成占用 CPU 过高的问题 今天在使用 pytorch 的过程中,发现 CPU 占用率过高。经过检查,发现是因为先在 CPU 中生成了随机数,然后再调用.to(device)传到 GPU,这样导致效率变得