
在OpenCV里使用特征匹配和单映射变换的代码详解

前面已经学习特征查找和对应匹配,接着下来在特征匹配之后,再使用findHomography函数来找出对应图像的投影矩阵。首先使用一个查询图片,然后在另外一张图片里找到目标对象,其实就是想在图片里查找所需要目标的一部分区域。为了实现这样的功能,需要使用calib3d库里的一个函数cv.findHomography(),把从两张图片里找到的特征点当作参数,传送给这个函数,然后这个函数返回一个投影变换矩阵,我们就可以使用 cv.perspectiveTransform()函数来对查找的目标进行投影,这样就可以在复杂图片里标记出相应的目标位置。
我们已经看到,在匹配时可能会有一些错误,这可能会影响结果。为了解决这个问题,需要使用RANSAC 或 LEAST_MEDIAN算法。所以提供正确估计的良好匹配称为内聚,其余的称为外联。cv.findHomography()函数返回一个值表示内聚还是外联的点。
在例子里,先使用ORB来寻找两个图片的特征点,接着根据设置条件为10个匹配特征,如果满足就会计算投影变换矩阵,一旦获得3x3的矩阵,就可以把寻找的目标对象在图片里标记出来。最后在复杂的图片里用白色线条标记出来。

参数详解:
srcPoints 源平面中点的坐标矩阵,可以是CV_32FC2类型,也可以是vector<Point2f>类型
dstPoints 目标平面中点的坐标矩阵,可以是CV_32FC2类型,也可以是vector<Point2f>类型
method 计算单应矩阵所使用的方法。不同的方法对应不同的参数,具体如下:
0 - 利用所有点的常规方法
RANSAC - RANSAC-基于RANSAC的鲁棒算法
LMEDS - 最小中值鲁棒算法
RHO - PROSAC-基于PROSAC的鲁棒算法
ransacReprojThreshold
将点对视为内点的最大允许重投影错误阈值(仅用于RANSAC和RHO方法)。如果
则点被认为是个外点(即错误匹配点对)。若srcPoints和dstPoints是以像素为单位的,则该参数通常设置在1到10的范围内。
mask
可选输出掩码矩阵,通常由鲁棒算法(RANSAC或LMEDS)设置。 请注意,输入掩码矩阵是不需要设置的。
maxIters RANSAC算法的最大迭代次数,默认值为2000。
confidence 可信度值,取值范围为0到1.
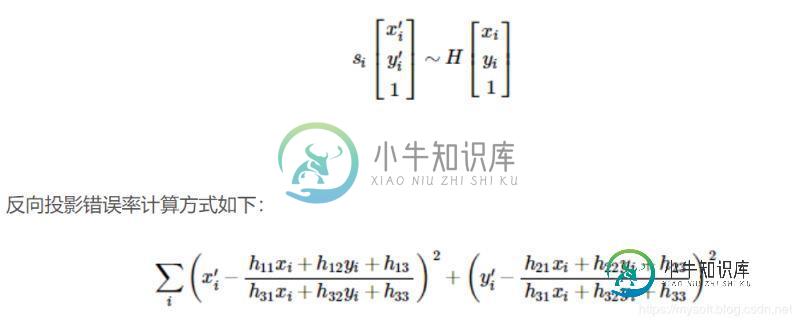
该函数能够找到并返回源平面和目标平面之间的转换矩阵H,以便于反向投影错误率达到最小。
演示使用的例子如下:
#python 3.7.4,opencv4.1 #蔡军生 https://blog.csdn.net/caimouse/article/details/51749579 # import numpy as np import cv2 from matplotlib import pyplot as plt MIN_MATCH_COUNT = 10 #读取文件 img1 = cv2.imread('rmb3.png') img2 = cv2.imread('rmb4.png') #初始化ORB检测器 orb = cv2.ORB_create() #用ORB查找关键点 kp1, des1 = orb.detectAndCompute(img1,None) kp2, des2 = orb.detectAndCompute(img2,None) # FLANN参数 FLANN_INDEX_LSH = 6 index_params = dict(algorithm = FLANN_INDEX_LSH, table_number = 6, key_size = 12, multi_probe_level = 1) search_params = dict(checks=50) #或者使用一个空的字典 flann = cv2.FlannBasedMatcher(index_params,search_params) matches = flann.knnMatch(des1,des2,k=2) # 比率 good = [] for m,n in matches: if m.distance < 0.7*n.distance: good.append(m) if len(good)>MIN_MATCH_COUNT: src_pts = np.float32([ kp1[m.queryIdx].pt for m in good ]).reshape(-1,1,2) dst_pts = np.float32([ kp2[m.trainIdx].pt for m in good ]).reshape(-1,1,2) #找到投影变换矩阵 M, mask = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC,5.0) matchesMask = mask.ravel().tolist() #进行投影变换 h,w,d = img1.shape pts = np.float32([ [0,0],[0,h-1],[w-1,h-1],[w-1,0] ]).reshape(-1,1,2) dst = cv2.perspectiveTransform(pts,M) #画变换后的外形 img2 = cv2.polylines(img2,[np.int32(dst)],True,(255,255,255),3, cv2.LINE_AA) else: print( "Not enough matches are found - {}/{}".format(len(good), MIN_MATCH_COUNT) ) matchesMask = Non draw_params = dict(matchColor = (0,255,0), # draw matches in green color singlePointColor = None, matchesMask = matchesMask, # draw only inliers flags = 2) img3 = cv2.drawMatches(img1,kp1,img2,kp2,good,None,**draw_params) #显示图片 cv2.imshow('img3',img3) cv2.waitKey(0) cv2.destroyAllWindows()
结果输出如下:

总结
以上所述是小编给大家介绍的在OpenCV里使用特征匹配和单映射变换的代码详解,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对小牛知识库网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
-
目标 在这一章中,我们将混合特征匹配和来自 calib3d 的单应性匹配来从一个复杂的图像中寻找已知的物体。 基础 我们在上节课做了什么?我们使用了一个 queryImage,在其中找到了一些特征点,我们又拿了一个 trainImage,在那个图像中也找到了这些特征,并且找到了它们之间最好的匹配。 总之,我们在另一个混乱的图像中发现了一个物体某些部分的位置。这些信息足以在 trainImage 上
-
目标 在这一章中, 我们将看到如何将一个图片上的特征和其他图片上的特征匹配起来。 我们将使用 OpenCV 中的蛮力匹配器和 FLANN 匹配器。 蛮力匹配器基础 蛮力匹配器很简单。 它采用第一组中的一个特征的描述符并且使用一些距离计算与第二组中的所有其他特征匹配。 返回最接近的一个。 对于BF匹配器,首先我们必须使用 cv2.BFMatcher() 来创建 BFMatcher 对象。 它需要两个
-
目标 在本章中, 我们将看到如何将一个图像中的特征与其他图像进行匹配。 我们将在OpenCV中使用Brute-Force匹配器和FLANN匹配器 Brute-Force匹配器的基础 蛮力匹配器很简单。它使用第一组中一个特征的描述符,并使用一些距离计算将其与第二组中的所有其他特征匹配。并返回最接近的一个。 对于BF匹配器,首先我们必须使用cv.BFMatcher()创建BFMatcher对象。 它需
-
规则化器缩放单个样本让其拥有单位$L^{p}$范数。这是文本分类和聚类常用的操作。例如,两个$L^{2}$规则化的TFIDF向量的点乘就是两个向量的cosine相似度。 Normalizer实现VectorTransformer,将一个向量规则化为转换的向量,或者将一个RDD规则化为另一个RDD。下面是一个规则化的例子。 import org.apache.spark.SparkConte
-
我在解决泛型问题时遇到了一些麻烦。我有一个“猫”对象列表和一个“狗”对象列表,我需要将它们传递到同一个方法中。该方法的返回类型是一个“字符串”和“动物列表”的映射,我试图找出一种方法来将带有动物列表的映射转换为带有猫或狗列表的映射。 这工作很好,如果我有一个单独的方法猫和狗,但我正在寻找一个更灵活的解决方案。 标题中出现错误的行: 注意:这是一个简化的例子,我必须能够使用地图中的列表作为“猫”或“
-
我正在使用卷积自动编码器。我的autoenoder配置有一个带stride(2,2)或avg pooling和relu激活的卷积层和一个带stride(2,2)或avg Unmooling和relu激活的反卷积层。 我用MNIST数据集训练自动编码器。 当我在第一个卷积层(20个过滤器,过滤器大小为3)后查看特征图时,我得到了一些黑色特征图,而学习到的过滤器不是黑色的。如果更改过滤器数量或过滤器大