
JVM系列之String.intern的性能解析

String对象有个特殊的StringTable字符串常量池,为了减少Heap中生成的字符串的数量,推荐尽量直接使用String Table中的字符串常量池中的元素。
那么String.intern的性能怎么样呢?我们一起来看一下。
String.intern和G1字符串去重的区别
之前我们提到了,String.intern方法会返回字符串常量池中的字符串对象的引用。
而G1垃圾回收器的字符串去重的功能其实和String.intern有点不一样,G1是让两个字符串的底层指向同一个byte[]数组。
有图为证:
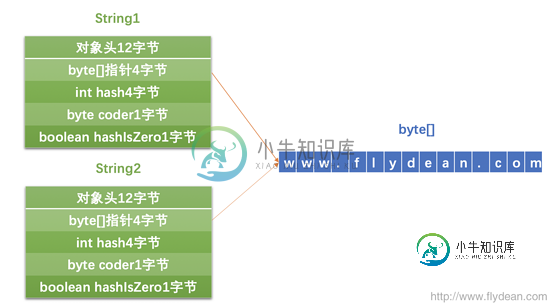
上图中的String1和String2指向的是同一个byte[]数组。
String.intern的性能
我们看下intern方法的定义:
public native String intern();
大家可以看到这是一个native的方法。native底层肯定是C++实现的。
那么是不是native方法一定会比java方法快呢?
其实native方法有这样几个耗时点:
- native方法需要调用JDK-JVM接口,实际上是会浪费时间的。
- 性能会受到native方法中HashTable实现方法的制约,如果在高并发的情况下,native的HashTable的实现可能成为性能的制约因素。
举个例子
还是用JMH工具来进行性能分析,我们使用String.intern,HashMap,和ConcurrentHashMap来对比分析,分别调用1次,100次,10000次和1000000。
代码如下:
@State(Scope.Benchmark)
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
@Fork(value = 1, jvmArgsPrepend = "-XX:+PrintStringTableStatistics")
@Warmup(iterations = 5)
@Measurement(iterations = 5)
public class StringInternBenchMark {
@Param({"1", "100", "10000", "1000000"})
private int size;
private StringInterner str;
private ConcurrentHashMapInterner chm;
private HashMapInterner hm;
@Setup
public void setup() {
str = new StringInterner();
chm = new ConcurrentHashMapInterner();
hm = new HashMapInterner();
}
public static class StringInterner {
public String intern(String s) {
return s.intern();
}
}
@Benchmark
public void useIntern(Blackhole bh) {
for (int c = 0; c < size; c++) {
bh.consume(str.intern("doit" + c));
}
}
public static class ConcurrentHashMapInterner {
private final Map<String, String> map;
public ConcurrentHashMapInterner() {
map = new ConcurrentHashMap<>();
}
public String intern(String s) {
String exist = map.putIfAbsent(s, s);
return (exist == null) ? s : exist;
}
}
@Benchmark
public void useCurrentHashMap(Blackhole bh) {
for (int c = 0; c < size; c++) {
bh.consume(chm.intern("doit" + c));
}
}
public static class HashMapInterner {
private final Map<String, String> map;
public HashMapInterner() {
map = new HashMap<>();
}
public String intern(String s) {
String exist = map.putIfAbsent(s, s);
return (exist == null) ? s : exist;
}
}
@Benchmark
public void useHashMap(Blackhole bh) {
for (int c = 0; c < size; c++++++) {
bh.consume(hm.intern("doit" + c));
}
}
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder()
.include(StringInternBenchMark.class.getSimpleName())
.build();
new Runner(opt).run();
}
}
输出结果:
Benchmark (size) Mode Cnt Score Error Units
StringInternBenchMark.useCurrentHashMap 1 avgt 5 34.259 ± 7.191 ns/op
StringInternBenchMark.useCurrentHashMap 100 avgt 5 3623.834 ± 499.806 ns/op
StringInternBenchMark.useCurrentHashMap 10000 avgt 5 421010.654 ± 53760.218 ns/op
StringInternBenchMark.useCurrentHashMap 1000000 avgt 5 88403817.753 ± 12719402.380 ns/op
StringInternBenchMark.useHashMap 1 avgt 5 36.927 ± 6.751 ns/op
StringInternBenchMark.useHashMap 100 avgt 5 3329.498 ± 595.923 ns/op
StringInternBenchMark.useHashMap 10000 avgt 5 417959.200 ± 62853.828 ns/op
StringInternBenchMark.useHashMap 1000000 avgt 5 79347127.709 ± 9378196.176 ns/op
StringInternBenchMark.useIntern 1 avgt 5 161.598 ± 9.128 ns/op
StringInternBenchMark.useIntern 100 avgt 5 17211.037 ± 188.929 ns/op
StringInternBenchMark.useIntern 10000 avgt 5 1934203.794 ± 272954.183 ns/op
StringInternBenchMark.useIntern 1000000 avgt 5 418729928.200 ± 86876278.365 ns/op
从结果我们可以看到,intern要比其他的两个要慢。
所以native方法不一定快。intern的用处不是在于速度,而是在于节约Heap中的内存使用。
到此这篇关于JVM系列之String.intern的性能解析的文章就介绍到这了,更多相关String.intern的性能内容请搜索小牛知识库以前的文章或继续浏览下面的相关文章希望大家以后多多支持小牛知识库!
-
我在玩jmh,在关于循环的部分,他们说 您可能会注意到重复次数越多,被测量操作的“感知”成本就越低。到目前为止,我们每次添加都使用1/20 ns,远远超出了硬件的实际能力。发生这种情况是因为循环被大量展开/流水线化,并且要测量的操作是从循环中提升的。士气:不要过度使用循环,依靠JMH来获得正确的测量。 我自己也试过了 并得到以下结果: 它确实显示了MyBenchmark。MeasureError\
-
考虑: 我弄不明白为什么返回的字符串值会产生不同的结果。intern(),上面写着: 调用intern方法时,如果池中已经包含一个由equals(Object)方法确定的等于此String对象的字符串,则返回池中的字符串。否则,将此String对象添加到池中并返回对此String对象的引用。 特别是在这两次测试之后: 我曾经读过一篇帖子,其中谈到了一些在其他事情之前实习的特殊字符串,但现在真的很模
-
Android 应用性能优化系列 原文链接分别为 : https://www.youtube.com/playlist?list=PLWz5rJ2EKKc9CBxr3BVjPTPoDPLdPIFCE https://www.udacity.com/course/ud825 译者 : 胡凯 Android性能优化典范 Android性能优化之渲染篇 Android性能优化之运算篇 Android性能
-
本文向大家介绍spring系列笔记之常用注解,包括了spring系列笔记之常用注解的使用技巧和注意事项,需要的朋友参考一下 前言 Spring的一个核心功能是IOC,就是将Bean初始化加载到容器中,Bean是如何加载到容器的,可以使用Spring注解方式或者Spring XML配置方式。 Spring注解方式减少了配置文件内容,更加便于管理,并且使用注解可以大大提高了开发效率! 该篇文章主要做下
-
本文向大家介绍Spring Boot系列教程之死信队列详解,包括了Spring Boot系列教程之死信队列详解的使用技巧和注意事项,需要的朋友参考一下 前言 在说死信队列之前,我们先介绍下为什么需要用死信队列。 如果想直接了解死信对接,直接跳入下文的"死信队列"部分即可。 ack机制和requeue-rejected属性 我们还是基于上篇《Spring Boot系列——7步集成RabbitMQ》的
-
问题内容: 我听到有人说“ JVM一定是Java解释器,但Java解释器不一定是JVM”。真的吗? 我的意思是Java解释器和JVM之间有区别吗? 问题答案: 是,有一点不同。 Java虚拟机: 一种软件“执行引擎”,可安全,兼容地执行微处理器(无论是计算机还是其他电子设备中)的Java类文件中的字节码。 Java解释器: 交替解码并执行某些代码体中的每个语句的模块。Java解释器解码并执行Jav
-
【粒子系统性能】页面主要展示项目运行过程中粒子系统更新和渲染的CPU占用情况,主要包括以下几个部分: 数据汇总 该项主要展示项目运行过程中的“ParticleSystem.Update CPU峰值”、“ParticleSystem.Update CPU均值”、“ParticleSystem 渲染峰值”和“ParticleSystem 渲染均值”。 粒子系统更新耗时 该项主要展示项目运行过程中的粒子
-
问题内容: 有没有办法在JVM上运行纯C代码? 不通过JNI连接运行,就像您可以通过JRuby运行ruby代码或通过Rhino运行javascript。 如果目前没有解决方案,您会建议我怎么做? 显然,我想使用尽可能多的局部解决方案来实现它。 ANTLR似乎是一个不错的起点,它具有完整的“ ANSI C”语法实现… 我应该使用ANTLR生成的代码在JVM上构建“玩具” VM吗? 问题答案: 201