
Java算法之堆排序代码示例

堆是一种特殊的完全二叉树,其特点是所有父节点都比子节点要小,或者所有父节点都比字节点要大。前一种称为最小堆,后一种称为最大堆。
比如下面这两个:
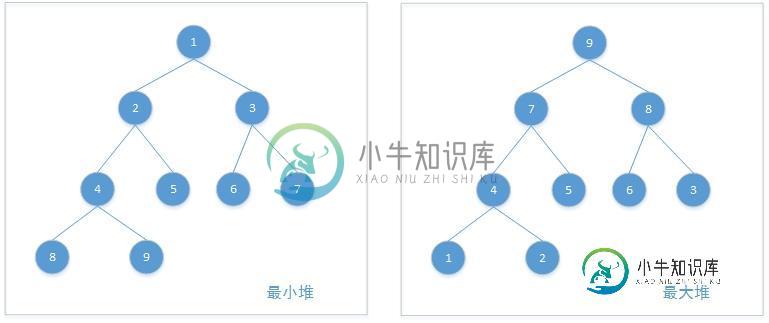
那么这个特性有什么作用?既然题目是堆排序,那么肯定能用来排序。想要用堆排序首先要创建一个堆,如果对4 3 6 2 7 1 5这七个数字做从小到大排序,需要用这七个数创建一个最大堆,来看代码:
public class HeapSort {
private int[] numbers;
private int length;
public HeapSort(int[] numbers) {
this.numbers = numbers;
this.length = numbers.length;
}
/**
* 调整二叉树
* 如果父节点编号为x, 那么左子节点的编号是2x, 右子节点的编号是2x+1
* 节点编号从1开始, 对应数组中的索引是编号-1
* @param nodeId 节点编号, 从1开始
*/
public void adjust(int nodeId) {
int swapId;
int flag = 0; //是否需要继续向下调整
while(nodeId * 2 <= this.length && flag == 0) {
//首先判断它和左子节点的关系, 并用swapId记录值较小的节点编号(最大堆是记录较大的)
int index = nodeId - 1; //节点对应数组中数字的索引
int leftChild = nodeId * 2 - 1; //左子节点对应数组中数字的索引
int rightChild = nodeId * 2; //右子节点对应数组中数字的索引
if(numbers[index] < numbers[leftChild]) {
swapId = nodeId * 2;
} else {
swapId = nodeId;
}
//如果有右子节点, 再与右子节点比较
if(nodeId * 2 + 1 <= this.length) {
if(numbers[swapId - 1] < numbers[rightChild])
swapId = nodeId * 2 + 1;
}
//如果最小的节点编号不是自己, 说明子节点中有比父节点更小的
if(swapId != nodeId) {
swap(swapId, nodeId);
nodeId = swapId;
} else {
flag = 1;
}
}
}
/**
* 交换两个节点的值
* @param nodeId1
* @param nodeId2
*/
public void swap(int nodeId1, int nodeId2) {
int t = numbers[nodeId1 - 1];
numbers[nodeId1 - 1] = numbers[nodeId2 - 1];
numbers[nodeId2 - 1] = t;
}
/**
* 创建最大堆
*/
public void createMaxHeap() {
//从最后一个非叶节点到第一个节点依次向上调整
for(int i = this.length / 2; i >= 1; i--) {
adjust(i);
}
}
public static void main(String[] args) {
int[] numbers = new int[] { 4, 3, 6, 2, 7, 1, 5 };
for(int x = 0; x < numbers.length; x++) {
System.out.print(numbers[x] + " ");
}
System.out.println();
HeapSort heap = new HeapSort(numbers);
heap.createMaxHeap();
}
}
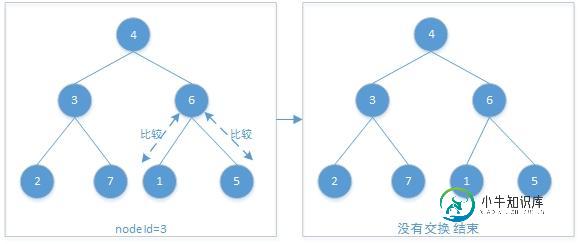
对本例中的数列,从this.length / 2到1,共执行了三轮循环。
第一轮:
第二轮:
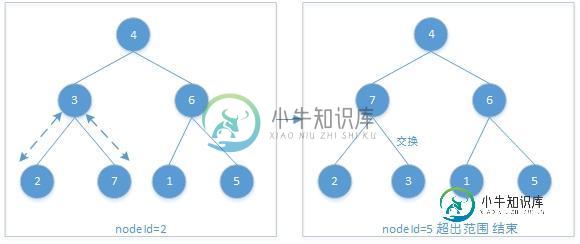
第三轮:
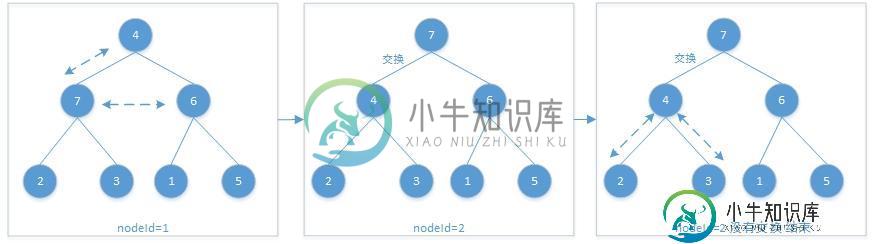
调整完成后,当前的二叉树已经符合最大堆的特性,可以用来从小到大排序。堆排序的原理是,交换堆顶和最后一个节点的数字,即把最大的数字放到数组最后,然后对除了最大数的前n-1个数从新执行调整过程,使其符合最大堆特性。重复以上过程直到堆中只剩下一个数字。
public void sort() {
while(this.length > 1) {
swap(1, this.length);
this.length--;
adjust(1);
}
for(int x = 0; x < numbers.length; x++) {
System.out.print(numbers[x] + " ");
}
}
堆排序的时间复杂度和快速排序的平均时间复杂度一样,是O(nlogn)。
总结
以上就是本文关于Java算法之堆排序代码示例的全部内容,希望对大家有所帮助。感兴趣的朋友可以继续参阅本站:java实现的各种排序算法代码示例、Java遗传算法之冲出迷宫等,有什么问题可以随时留言,小编会及时回复大家的。感谢朋友们对本站的支持!
-
本文向大家介绍C#排序算法之堆排序,包括了C#排序算法之堆排序的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了C#实现堆排序的具体代码,供大家参考,具体内容如下 代码: 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持呐喊教程。
-
本文向大家介绍java 基本算法之归并排序实例代码,包括了java 基本算法之归并排序实例代码的使用技巧和注意事项,需要的朋友参考一下 java 基本算法之归并排序实例代码 原理:归并(Merge)排序法是将两个(或两个以上)有序表合并成一个新的有序表, * 即把待排序序列分为若干个子序列,每个子序列是有序的。 * 然后再把有序子序列合并为整体有序序列。 实例代码: 感谢阅读,
-
给定一个堆栈,任务是对它进行排序,使堆栈的顶部具有最大的元素。 示例1: 输入:堆栈:3 2 1输出:3 2 1示例2: 输入:堆栈:11 2 32 3 41输出:41 32 11 3 2 您的任务: 预期时间复杂度:O(N*N)预期辅助空间:O(N)递归。 约束:1
-
示例数据 # heapq_heapdata.py # This data was generated with the random module. data = [19, 9, 4, 10, 11] # heapq_showtree.py import math from io import StringIO def show_tree(tree, total_width=36, fil
-
本文向大家介绍Java语言字典序排序算法解析及代码示例,包括了Java语言字典序排序算法解析及代码示例的使用技巧和注意事项,需要的朋友参考一下 字典序法就是按照字典排序的思想逐一产生所有排列。 在数学中,字典或词典顺序(也称为词汇顺序,字典顺序,字母顺序或词典顺序)是基于字母顺序排列的单词按字母顺序排列的方法。 这种泛化主要在于定义有序完全有序集合(通常称为字母表)的元素的序列(通常称为计算机科学
-
本文向大家介绍Python实现的堆排序算法示例,包括了Python实现的堆排序算法示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python实现的堆排序算法。分享给大家供大家参考,具体如下: 堆排序的思想: 堆是一种数据结构,可以将堆看作一棵完全二叉树,这棵二叉树满足,任何一个非叶节点的值都不大于(或不小于)其左右孩子节点的值。 将一个无序序列调整为一个堆,就可以找出这个序列的最大值
-
本文向大家介绍JAVA堆排序算法的讲解,包括了JAVA堆排序算法的讲解的使用技巧和注意事项,需要的朋友参考一下 预备知识 堆排序 堆排序是利用堆这种数据结构而设计的一种排序算法,堆排序是一种选择排序,它的最坏,最好,平均时间复杂度均为O(nlogn),它也是不稳定排序。首先简单了解下堆结构。 堆 堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆;或者每个
-
本文向大家介绍Python排序算法实例代码,包括了Python排序算法实例代码的使用技巧和注意事项,需要的朋友参考一下 排序算法,下面算法均是使用Python实现: 插入排序 原理:循环一次就移动一次元素到数组中正确的位置,通常使用在长度较小的数组的情况以及作为其它复杂排序算法的一部分,比如mergesort或quicksort。时间复杂度为 O(n2) 。 选择排序 原理:每一趟都选择最小的值和