
Fiddler如何抓取手机APP数据包

Fiddler,这个是所有软件开发者必备神器!这款工具不仅可以抓取PC上开发web时候的数据包,而且可以抓取移动端(Android,Iphone,WindowPhone等都可以)。
第一步:下载神器Fiddler,下载链接:
http://w.x.baidu.com/alading/anquan_soft_down_ub/10963
下载完成之后,傻瓜式的安装一下了!
第二步:设置Fiddler
打开Fiddler, Tools-> Fiddler Options (配置完后记得要重启Fiddler)
选中"Decrpt HTTPS traffic", Fiddler就可以截获HTTPS请求
选中"Allow remote computers to connect". 是允许别的机器把HTTP/HTTPS请求发送到Fiddler上来
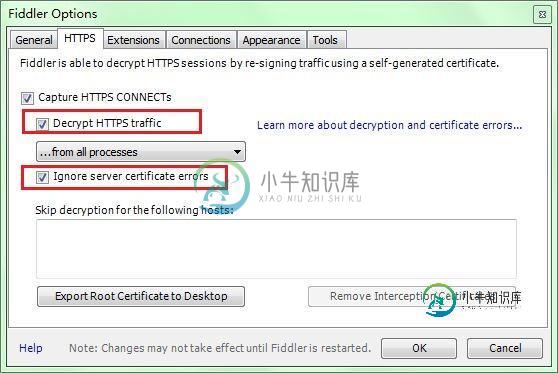
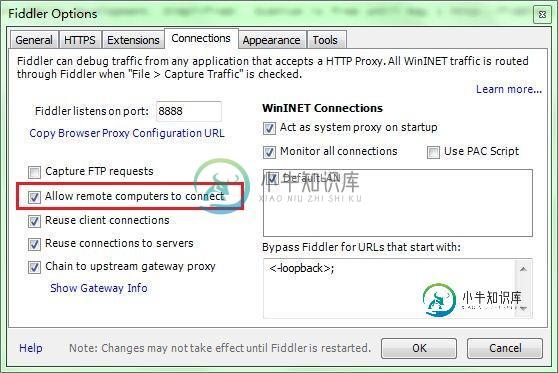
记住这个端口号是:8888
第三步:设置Android手机
首先获取PC的ip地址:命令行中输入:ipconfig,获取ip地址
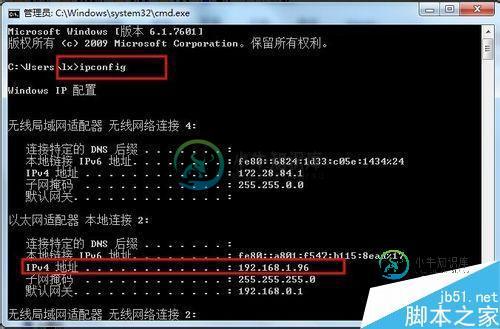
好吧,这时候我就拿到了IP地址和端口号了
下面来对Android手机进行代理设置
确定一下手机和PC是连接在同一个局域网中
进入手机的设置->点击进入WLAN设置->选择连接到的无线网,长按弹出选项框:如图所示:
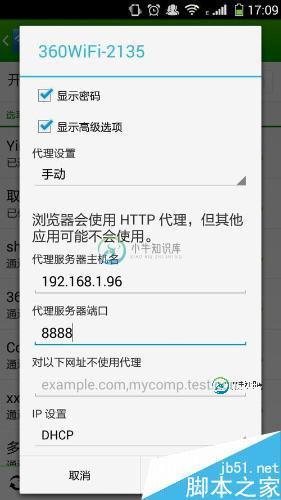
将代理设置成手动,将上面获取到的ip地址和端口号填入,点击保存。这样就将我们的手机设置成功了。
第四步:下载Fiddler的安全证书
使用Android手机的浏览器打开:http://192.168.1.96:8888, 点"FiddlerRoot certificate" 然后安装证书,如图:
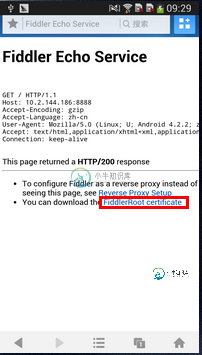
到这里我们就设置好所有的值,下面就来测试一下,打开手机的超级课程表APP
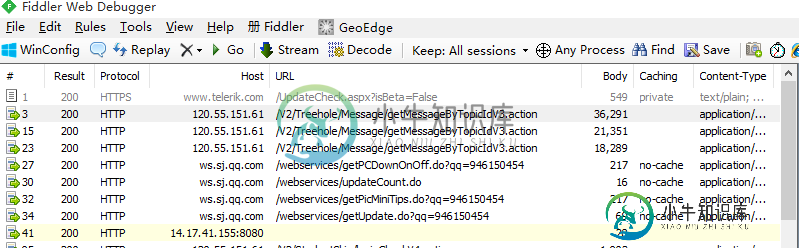
这样就抓取Android移动端的数据包成功了,这个对于我们后面进行网络数据请求的调试有很大的帮助,我们可以通过这个方法来判断我们请求网络是否成功!
-
Fiddler可以只抓取get请求方法的数据包吗?如何抓取呢? 希望知道的小伙伴回答解答一下,十分感谢!!!
-
1. Fiddler抓包工具: Fiddler(中文名称:小提琴)是一个HTTP的调试代理,以代理服务器的方式,监听系统的Http网络数据流动 Fiddler是一个http协议调试代理工具,它能够记录并检查所有你的电脑和互联网之间的http通讯,设置断点,查看所有的“进出”Fiddler的数据(指cookie,html,js,css等文件,这些都可以让你胡乱修改的意思)。 Fiddler 要比其他
-
主要内容:编写程序流程分析,确定Xpath表达式,编写程序代码本节使用 Python 爬虫库完成链家二手房( https://bj.lianjia.com/ershoufang/rs/)房源信息抓取,包括楼层、区域、总价、单价等信息。在编写此程序的过程中,您将体会到 lxml 解析库的实际应用。 编写程序流程分析 打开链家网站后,第一步,确定网站是否为静态网站,通过在网页源码内搜索关键字的方法,可以确定其为静态网站;第二步,确定要抓取页面的 URL 规律,第
-
随着物联网的发展,连接到互联网的设备数量呈指数增长,物联网信息安全越来越重要。 因此,TLS逐渐成为物联网通讯的标配。但是TLS是加密传输,这给调试增加了一定的难度。 笔者最近工作中一直用到HTTPS,但是苦于wireshark只能抓取HTTP的明文数据包,无法抓取HTTPS的数据包,于是就有了这篇文章,使用wireshark抓取HTTPS的数据包. 简单介绍TLS1.2握手和协商过程 clien
-
随着物联网的发展,连接到互联网的设备数量呈指数增长,物联网信息安全越来越重要。 因此,TLS逐渐成为物联网通讯的标配。但是TLS是加密传输,这给调试增加了一定的难度。 笔者最近工作中一直用到HTTPS,但是苦于wireshark只能抓取HTTP的明文数据包,无法抓取HTTPS的数据包,于是就有了这篇文章,使用wireshark抓取HTTPS的数据包. 简单介绍TLS1.2握手和协商过程 clien
-
如题,求指教
-
问题内容: 我正在做一个项目,我需要做很多屏幕抓取工作,以尽可能快地获取大量数据。我想知道是否有人知道任何好的API或资源来帮助我。 顺便说一下,我正在使用Java。 到目前为止,这是我的工作流程: 连接到网站(使用来自Apache的HTTPComponents) 网站包含一个带有一堆我需要访问的链接的部分(使用内置的Java HTML解析器来弄清楚我需要访问的所有链接是什么,这很烦人且凌乱的代码
-
在我的硕士论文中,我正在探索通过web自动化从网站中提取数据的可能性。步骤如下: 登录网站(https://www.metal.com/Copper/201102250376) 输入用户名和密码 单击登录 将日期更改为2020年1月1日 刮取生成的表格数据,然后将其保存到csv文件中 用我电脑上的特定名称保存到特定文件夹 运行相同的序列,在同一浏览器窗口的新选项卡中下载其他材料的其他历史价格数据