
爬取网页内容的利器--Jsoup用法详解

Jsoup介绍
Jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
Jsoup新手教程:https://www.xnip.cn/jiaocheng/jsoup/
主要功能
1. 从一个URL,文件或字符串中解析HTML;
2. 使用DOM或CSS选择器来查找、取出数据;
3. 可操作HTML元素、属性、文本;
jsoup是基于MIT协议发布的,可放心使用于商业项目。
Jsoup可以帮助我们爬取网站的数据。
有时候我们想爬取一些网站的数据 ,方便业务信息的采集等,Jsoup给我们提供了很多方便的方法,轻轻松松解析html代码片段,然后拿到自己想要的数据。
Jsoup是一款Java的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
下面是关于Jsoup提供的功能方法目录参考链接:
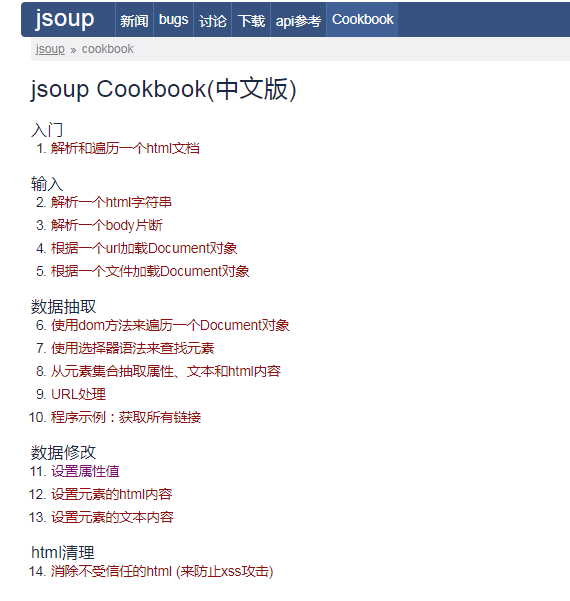
可以看出Jsoup的主要功能: (1)从一个URL,文件或字符串中解析HTML (2)使用DOM或CSS选择器来查找、取出数据 (3)可操作HTML元素、属性、文本
使用方法:
一:下载Jsoup依赖的三方jar包,下载地址,将下载好的jar包放入WEB-INF——>lib目录下
二:爬取网页的源码: 当我们不知道jsoup时,我们想获取百度首页的body内容,我们可能会这样写:
public static void catchHtmlCode(String getUrl){
BufferedReader buffreader;
try {
URL u = new URL(getUrl);
URLConnection connection = u.openConnection();
InputStream inputStream = connection.getInputStream();
buffreader = new BufferedReader(new InputStreamReader(inputStream, "utf-8"));
StringBuffer buff = new StringBuffer();
String line;
while (null != (line = buffreader.readLine())) {
buff.append(line);
}
String html = buff.toString();
/*解析html字符串*/
Document doc = Jsoup.parse(html);
Element body = doc.body();
System.out.println("code:"+body.html());
}catch (Exception e) {
e.printStackTrace();
}
}这样看起来很麻烦,用jsoup一行代码便能达到异曲同工的效果:
public static void catchHtmlCode(String getUrl){
try {
Document doc = Jsoup.connect(getUrl).get();
Element body = doc.body();
System.out.println("code:"+body.html());
}catch (Exception e) {
e.printStackTrace();
}
}三:查看爬取的结果:
public static void main(String[] args) {
catchHtmlCode("http://www.baidu.com");
}
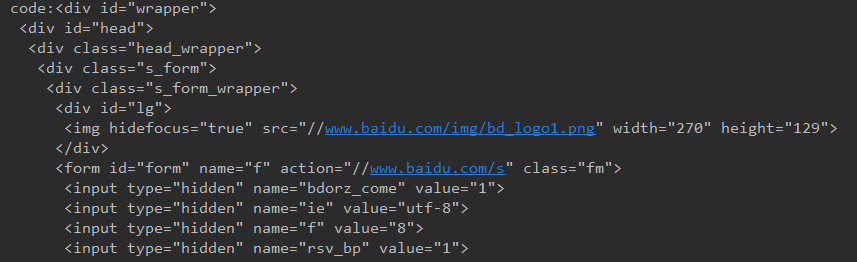
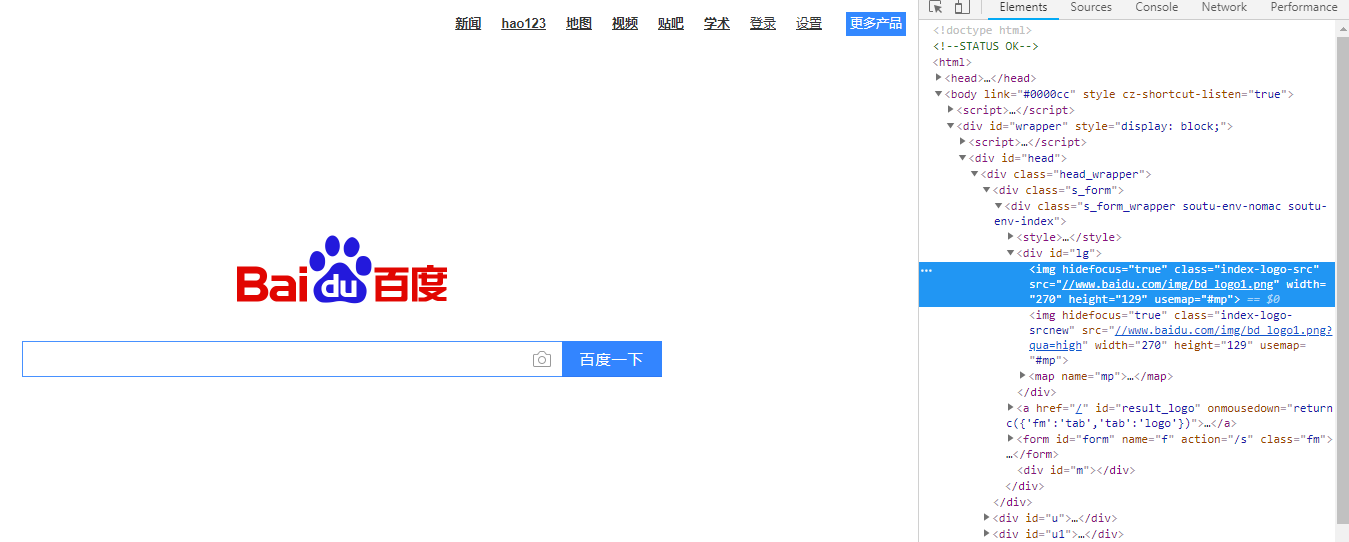
可以看到爬取的结果和百度首页的源码一致。
Document查找元素常用的方法:
body():能够获取文档body元素的所有子元素,与 getElementsByTag("body")相同getElementById():通过id来获取元素,和javascript写法相同getElementsByClass():通过class类名来获取元素getElementsByTag():通过标签名称来获取元素
Document获取元素数据常用的方法:
text():获取标签的文本内容,和jquery用法相似html():获取标签的HTML内容,包含标签title():获取html<title>标签的内容
Document操作元素常用的方法
append():在调用元素的最后面添加html片段appendText():在调用元素的最后面添加文本内容prepend():在调用元素的最前面添加html片段prependText():在调用元素的最前面添加文本内容。
-
本文向大家介绍易语言爬取网页内容方法,包括了易语言爬取网页内容方法的使用技巧和注意事项,需要的朋友参考一下 写个辅助工具的时候需要提取网页里面的某些内容,我这里便把方法告诉大家,希望对大家有所帮助,记得投票给我哦! 1、在新建的windos窗口程序中画: 两个编辑框、一个按钮。 再添加模块如图中三步! 我们来实现,在一个编辑框中输入网址后,点击按钮,然后取到指定内容到编辑框2中。 2、比如我们来取
-
本文向大家介绍Python下使用Scrapy爬取网页内容的实例,包括了Python下使用Scrapy爬取网页内容的实例的使用技巧和注意事项,需要的朋友参考一下 上周用了一周的时间学习了Python和Scrapy,实现了从0到1完整的网页爬虫实现。研究的时候很痛苦,但是很享受,做技术的嘛。 首先,安装Python,坑太多了,一个个爬。由于我是windows环境,没钱买mac, 在安装的时候遇到各种各
-
本文向大家介绍Python使用爬虫爬取静态网页图片的方法详解,包括了Python使用爬虫爬取静态网页图片的方法详解的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python使用爬虫爬取静态网页图片的方法。分享给大家供大家参考,具体如下: 爬虫理论基础 其实爬虫没有大家想象的那么复杂,有时候也就是几行代码的事儿,千万不要把自己吓倒了。这篇就清晰地讲解一下利用Python爬虫的理论基础。 首
-
我正在尝试用JSOUP从以下页面获取内容:
-
本文向大家介绍python根据用户需求输入想爬取的内容及页数爬取图片方法详解,包括了python根据用户需求输入想爬取的内容及页数爬取图片方法详解的使用技巧和注意事项,需要的朋友参考一下 本次小编向大家介绍的是根据用户的需求输入想爬取的内容及页数。 主要步骤: 1.提示用户输入爬取的内容及页码。 2.根据用户输入,获取网址列表。 3.模拟浏览器向服务器发送请求,获取响应。 4.利用xpath方法找
-
本文向大家介绍SpringBoot中使用Jsoup爬取网站数据的方法,包括了SpringBoot中使用Jsoup爬取网站数据的方法的使用技巧和注意事项,需要的朋友参考一下 爬取数据 导入jar包 新建实体类 编写爬虫工具类 可以看到内容、图片、价格系数爬取 到此这篇关于SpringBoot中使用Jsoup爬取网站数据的方法的文章就介绍到这了,更多相关SpringBoot Jsoup爬取内容请搜索呐
-
本文向大家介绍利用node.js爬取指定排名网站的JS引用库详解,包括了利用node.js爬取指定排名网站的JS引用库详解的使用技巧和注意事项,需要的朋友参考一下 前言 本文给大家介绍的爬虫将从网站爬取排名前几的网站,具体前几名可以具体设置,并分别爬取他们的主页,检查是否引用特定库。下面话不多说了,来一起看看详细的介绍: 所用到的node主要模块 express 不用多说 request http
-
问题内容: 我正在使用Python 3.1,如果有帮助的话。 无论如何,我正在尝试获取此网页的内容。我用Google搜索了一下,尝试了不同的方法,但是它们没有用。我猜想这应该是一件容易的事,但是…我做不到。:/。 urllib,urllib2的结果: 谢谢杰森。:D。 问题答案: 由于您使用的是Python 3.1,因此需要使用新的Python 3.1 API 。 尝试: 或者,看起来您正在使用P