
在SQL SERVER中导致索引查找变成索引扫描的问题分析

SQL Server 中什么情况会导致其执行计划从索引查找(Index Seek)变成索引扫描(Index Scan)呢? 下面从几个方面结合上下文具体场景做了下测试、总结、归纳。
1:隐式转换会导致执行计划从索引查找(Index Seek)变为索引扫描(Index Scan)
Implicit Conversion will cause index scan instead of index seek. While implicit conversions occur in SQL Server to allow data evaluations against different data types, they can introduce performance problems for specific data type conversions that result in an index scan occurring during the execution. Good design practices and code reviews can easily prevent implicit conversion issues from ever occurring in your design or workload.
如下示例,AdventureWorks2014数据库的HumanResources.Employee表,由于NationalIDNumber字段类型为NVARCHAR,下面SQL发生了隐式转换,导致其走索引扫描(Index Scan)
SELECT NationalIDNumber, LoginID FROM HumanResources.Employee WHERE NationalIDNumber = 112457891

我们可以通过两种方式避免SQL做隐式转换:
1:确保比较的两者具有相同的数据类型。
2:使用强制转换(explicit conversion)方式。
我们通过确保比较的两者数据类型相同后,就可以让SQL走索引查找(Index Seek),如下所示
SELECT nationalidnumber,
loginid
FROM humanresources.employee
WHERE nationalidnumber = N'112457891'

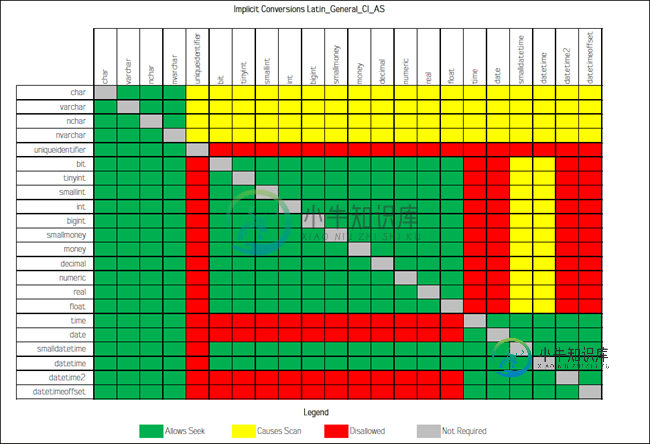
注意:并不是所有的隐式转换都会导致索引查找(Index Seek)变成索引扫描(Index Scan),Implicit Conversions that cause Index Scans 博客里面介绍了那些数据类型之间的隐式转换才会导致索引扫描(Index Scan)。如下图所示,在此不做过多介绍。

避免隐式转换的一些措施与方法
1:良好的设计和代码规范(前期)
2:对发布脚本进行Rreview(中期)
3:通过脚本查询隐式转换的SQL(后期)
下面是在数据库从执行计划中搜索隐式转换的SQL语句
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
DECLARE @dbname SYSNAME
SET @dbname = QUOTENAME(DB_NAME());
WITH XMLNAMESPACES
(DEFAULT 'http://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT
stmt.value('(@StatementText)[1]', 'varchar(max)'),
t.value('(ScalarOperator/Identifier/ColumnReference/@Schema)[1]', 'varchar(128)'),
t.value('(ScalarOperator/Identifier/ColumnReference/@Table)[1]', 'varchar(128)'),
t.value('(ScalarOperator/Identifier/ColumnReference/@Column)[1]', 'varchar(128)'),
ic.DATA_TYPE AS ConvertFrom,
ic.CHARACTER_MAXIMUM_LENGTH AS ConvertFromLength,
t.value('(@DataType)[1]', 'varchar(128)') AS ConvertTo,
t.value('(@Length)[1]', 'int') AS ConvertToLength,
query_plan
FROM sys.dm_exec_cached_plans AS cp
CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp
CROSS APPLY query_plan.nodes('/ShowPlanXML/BatchSequence/Batch/Statements/StmtSimple') AS batch(stmt)
CROSS APPLY stmt.nodes('.//Convert[@Implicit="1"]') AS n(t)
JOIN INFORMATION_SCHEMA.COLUMNS AS ic
ON QUOTENAME(ic.TABLE_SCHEMA) = t.value('(ScalarOperator/Identifier/ColumnReference/@Schema)[1]', 'varchar(128)')
AND QUOTENAME(ic.TABLE_NAME) = t.value('(ScalarOperator/Identifier/ColumnReference/@Table)[1]', 'varchar(128)')
AND ic.COLUMN_NAME = t.value('(ScalarOperator/Identifier/ColumnReference/@Column)[1]', 'varchar(128)')
WHERE t.exist('ScalarOperator/Identifier/ColumnReference[@Database=sql:variable("@dbname")][@Schema!="[sys]"]') = 1
2:非SARG谓词会导致执行计划从索引查找(Index Seek)变为索引扫描(Index Scan)
SARG(Searchable Arguments)又叫查询参数, 它的定义:用于限制搜索的一个操作,因为它通常是指一个特定的匹配,一个值的范围内的匹配或者两个以上条件的AND连接。不满足SARG形式的语句最典型的情况就是包括非操作符的语句,如:NOT、!=、<>;、!<;、!>;NOT EXISTS、NOT IN、NOT LIKE等,另外还有像在谓词使用函数、谓词进行运算等。
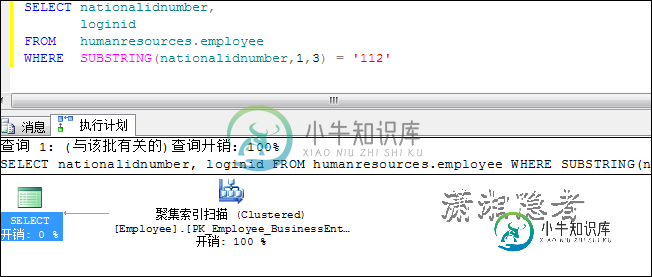
2.1:索引字段使用函数会导致索引扫描(Index Scan)
SELECT nationalidnumber,
loginid
FROM humanresources.employee
WHERE SUBSTRING(nationalidnumber,1,3) = '112'
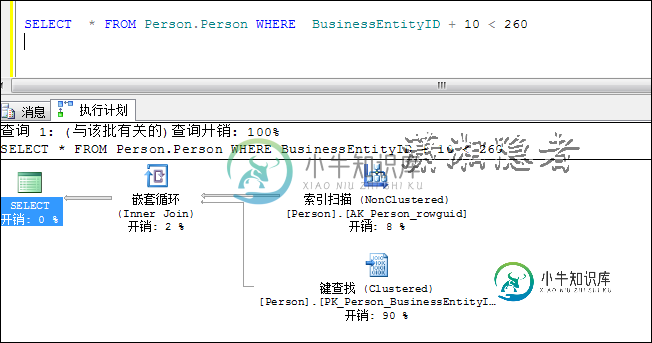
2.2索引字段进行运算会导致索引扫描(Index Scan)
对索引字段字段进行运算会导致执行计划从索引查找(Index Seek)变成索引扫描(Index Scan):
SELECT * FROM Person.Person WHERE BusinessEntityID + 10 < 260
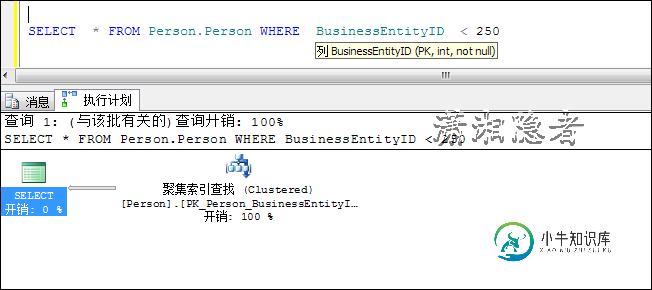
一般要尽量避免这种情况出现,如果可以的话,尽量对SQL进行逻辑转换(如下所示)。虽然这个例子看起来很简单,但是在实际中,还是见过许多这样的案例,就像很多人知道抽烟有害健康,但是就是戒不掉!很多人可能了解这个,但是在实际操作中还是一直会犯这个错误。道理就是如此!
SELECT * FROM Person.Person WHERE BusinessEntityID < 250
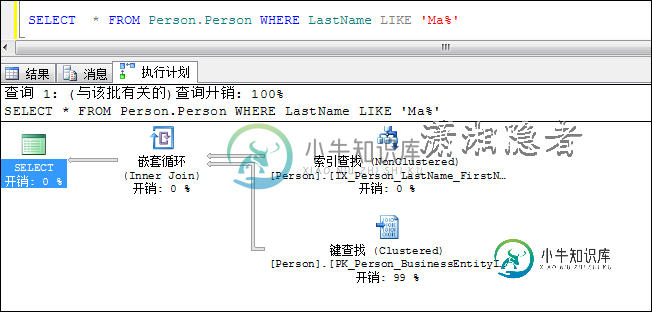
2.3 LIKE模糊查询回导致索引扫描(Index Scan)
Like语句是否属于SARG取决于所使用的通配符的类型, LIKE 'Condition%' 就属于SARG、LIKE '%Condition'就属于非SARG谓词操作
SELECT * FROM Person.Person WHERE LastName LIKE 'Ma%'
SELECT * FROM Person.Person WHERE LastName LIKE '%Ma%'
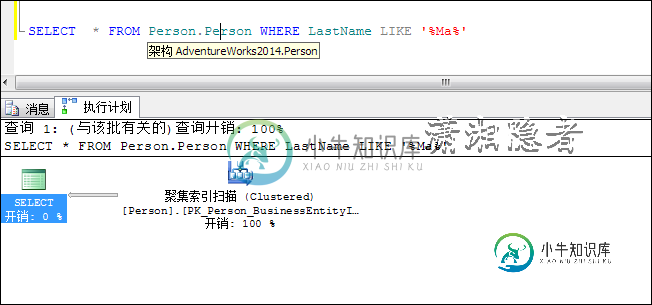
3:SQL查询返回数据页(Pages)达到了临界点(Tipping Point)会导致索引扫描(Index Scan)或表扫描(Table Scan)
What is the tipping point? It's the point where the number of rows returned is "no longer selective enough". SQL Server chooses NOT to use the nonclustered index to look up the corresponding data rows and instead performs a table scan.
关于临界点(Tipping Point),我们下面先不纠结概念了,先从一个鲜活的例子开始吧:
SET NOCOUNT ON; DROP TABLE TEST CREATE TABLE TEST (OBJECT_ID INT, NAME VARCHAR(8)); CREATE INDEX PK_TEST ON TEST(OBJECT_ID) DECLARE @Index INT =1; WHILE @Index <= 10000 BEGIN INSERT INTO TEST SELECT @Index, 'kerry'; SET @Index = @Index +1; END UPDATE STATISTICS TEST WITH FULLSCAN; SELECT * FROM TEST WHERE OBJECT_ID= 1
如上所示,当我们查询OBJECT_ID=1的数据时,优化器使用索引查找(Index Seek)

上面OBJECT_ID=1的数据只有一条,如果OBJECT_ID=1的数据达到全表总数据量的20%会怎么样? 我们可以手工更新2001条数据。此时SQL的执行计划变成全表扫描(Table Scan)了。
UPDATE TEST SET OBJECT_ID =1 WHERE OBJECT_ID<=2000; UPDATE STATISTICS TEST WITH FULLSCAN; SELECT * FROM TEST WHERE OBJECT_ID= 1


临界点决定了SQL Server是使用书签查找还是全表/索引扫描。这也意味着临界点只与非覆盖、非聚集索引有关(重点)。
Why is the tipping point interesting?
It shows that narrow (non-covering) nonclustered indexes have fewer uses than often expected (just because a query has a column in the WHERE clause doesn't mean that SQL Server's going to use that index)
It happens at a point that's typically MUCH earlier than expected… and, in fact, sometimes this is a VERY bad thing!
Only nonclustered indexes that do not cover a query have a tipping point. Covering indexes don't have this same issue (which further proves why they're so important for performance tuning)
You might find larger tables/queries performing table scans when in fact, it might be better to use a nonclustered index. How do you know, how do you test, how do you hint and/or force… and, is that a good thing?
4:统计信息缺失或不正确会导致索引扫描(Index Scan)
统计信息缺失或不正确,很容易导致索引查找(Index Seek)变成索引扫描(Index Scan)。 这个倒是很容易理解,但是构造这样的案例比较难,一时没有想到,在此略过。
5:谓词不是联合索引的第一列会导致索引扫描(Index Scan)
SELECT * INTO Sales.SalesOrderDetail_Tmp FROM Sales.SalesOrderDetail;
CREATE INDEX PK_SalesOrderDetail_Tmp ON Sales.SalesOrderDetail_Tmp(SalesOrderID, SalesOrderDetailID);
UPDATE STATISTICS Sales.SalesOrderDetail_Tmp WITH FULLSCAN;
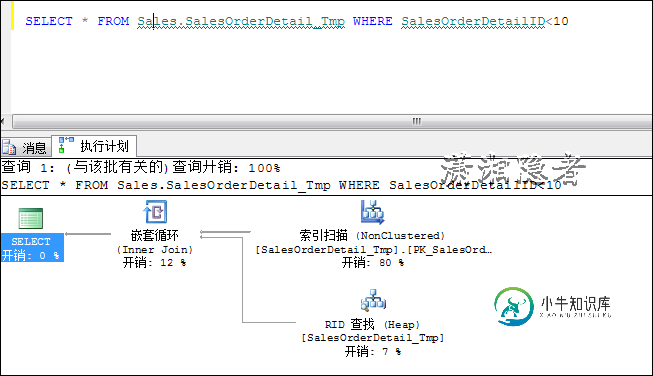
下面这个SQL语句得到的结果是一致的,但是第二个SQL语句由于谓词不是联合索引第一列,导致索引扫描
SELECT * FROM Sales.SalesOrderDetail_Tmp WHERE SalesOrderID=43659 AND SalesOrderDetailID<10

SELECT * FROM Sales.SalesOrderDetail_Tmp WHERE SalesOrderDetailID<10
-
问题内容: 据我所知,堆表是没有聚簇索引并且没有物理顺序的表。我有一个具有12万行的堆表“扫描”,并且正在使用以下选择: 如果为“ id”列创建非聚集索引,则将获得 223次物理读取 。如果删除非聚集索引并更改表以使“ id”成为主键(以及聚集索引),则将获得 515次物理读取 。 如果聚集索引表如下图所示: 为什么聚簇索引扫描的工作方式类似于表扫描?(或者在检索所有行的情况下更糟)。为什么不使用
-
问题内容: 我知道索引 查找 比索引 扫描 更好,但是在SQL Server解释计划中它更可取:索引查找或键查找(在SQL Server 2000中为书签)? 请告诉我,他们没有再次更改SQL Server 2008的名称… 问题答案: 每次索引检索。 查找非常昂贵,因此它涵盖了索引,尤其是添加了INCLUDE子句以使索引更好。 举例来说,假设您只希望一行,那么在查找后进行查找可能比尝试覆盖查询要
-
本文向大家介绍详解sqlserver查询表索引,包括了详解sqlserver查询表索引的使用技巧和注意事项,需要的朋友参考一下 SELECT 索引名称=a.name ,表名=c.name ,索引字段名=d.name ,索引字段位置=d.colid 需创建索引 例如: 根据某列判断是否有重复记录,如果该列为非主键,则创建索引 根据经常查询的列,创建索引 无须创建索引 字段内容大部分一样,
-
问题内容: 我有以下查询 当我运行它并检查实际的执行计划时,我可以看到最昂贵的运算符是聚集索引扫描(索引位于a.pred上) 但是,如果我按以下方式更改查询 消除了索引扫描,并使用了索引查找。 有人可以解释为什么吗?在我看来,这与以下事实有关:变量中的值可以是任何值,因此SQL不知道如何计划执行。 有什么办法可以消除表扫描但仍然可以使用变量?(PS,它将转换为以@StartDate和@EndDat
-
问题内容: 我已经隔离了IE7 错误的一个小测试用例,但是不知道如何解决它。我整天都在玩。 IE7有什么问题? 测试CSS: 测试HTML: 问题答案: Z索引不是绝对测量。 只要z-index:1000的元素位于 不同的 堆叠上下文中 ,则z-index:1000的元素可能位于z- index:1 的元素之后。 当您指定z-index时,您是相对于同一堆叠上下文中的其他元素指定它的,尽管CSS规
-
本文向大家介绍SQLSERVER中忽略索引提示,包括了SQLSERVER中忽略索引提示的使用技巧和注意事项,需要的朋友参考一下 当我们想让某条查询语句利用某个索引的时候,我们一般会在查询语句里加索引提示,就像这样 当在生产环境里面,由于这个索引提示的原因,优化器一般不会再去考虑其他的索引,那有时候这个索引提示可能会导致查询变慢 经过你的测试,发现确实是因为这个索引提示的关系导致查询变慢,但是SQL