
golang中定时器cpu使用率高的现象详析

前言:
废话少说,上线一个用golang写的高频的任务派发系统,上线跑着很稳定,但有个缺点就是当没有任务的时候,cpu的消耗也在几个百分点。 平均值在3%左右的cpu使用率。你没有任务的时候,cpu还跑到3%,这个说不过去呀。通过查看进程pidstat捕获得知,system系统的cpu消耗也不少。
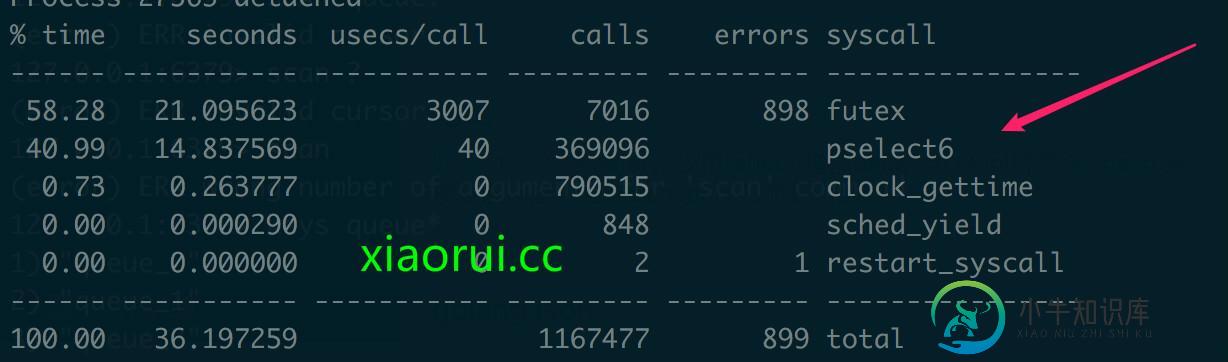
sys的cpu占用率高一般是由于大量的syscall系统调用引起的….
下面的截图是用strace统计出来的系统调用…. 我们发现 futex 和 pselect6 的syscall非常的多…. futex 是锁的调用,pselect6可以理解为select的加强版,除了我们不关心的信号掩码外,他是支持纳秒级别的定时器。
那我们知道,在golang里很多的锁操作,比如sync.Mutex 已经被抽象成 标志位及waitQueue,加runtime调度的模式。这也是所有协程框架会做的事情,抽象锁的操作,避免陷入内核上下文切换,使用协程内置的调度器,golang是通过runtime来做使这些Goroutine排队的唤醒和拿锁。 我们用户层除了cgo之外,是不容易调用futex syscall….
有人说了,channel是有锁的,对的,channel的底层数据结构是有锁对象的,但是他的锁操作正如我上面说的那样,已经被抽象成atomic cas了, 不可能这么多futex的。
下面是火焰图的表现.

那我们先放弃futex的追查,先来排查下 pselect6为毛这么多? 整个系统里看起来会用到超时逻辑的只有select了。 为了避免channel读写长时间阻塞,我们通常都会加一个定时器,比如使用 time.After, time.NewTicker, time.NewTimer ….
测试定时器与futex及pselect6的关系
既然确定是 定时器的问题,那么我们来做测试下各种的组合,把协程数和定时器时间的精度提高来看。

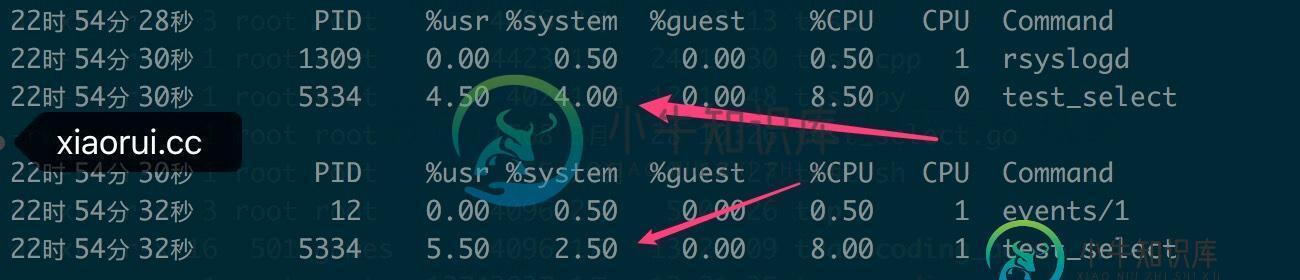
下面是 300个协程,sleep 100ms 的cpu占用比.

下面是 800个协程,sleep 100ms的cpu占用比 .

下面是800个协程,sleep加长到1s 之后的cpu表现.
通过测试来看,只要把定时器的时间精度放到1秒,cpu占用率还是降低了不少…. 所以说,有用 …
那么回到问题,前面说的 futex 怎么一回事? 跟定时器是否有联系? 答案是有联系的 . 定时器精度小的时候,futex锁操作次数相对应的变高。 反之,定时器提升到大几秒,futex边的更少了…
那么问题又来了,定时器为什么会产生锁? 定时器不外乎就那几个方法,小顶堆呀,红黑树呀…. golang使用堆来构建全局定时器,既然是堆,那么肯定就要有锁,开了几百个协程,如果有N个P,那么几百个协程会分派在不同的P上。 协程需要跑在线程上,那么这么多的线程去操作heap堆,自然就会有更多的锁冲突,锁操作了。
先前的cpu占用率高的代码样例:
# xiaorui.cc
var ticker = time.NewTicker(100 * time.Millisecond)
defer ticker.Stop()
var counter = 0
for {
select {
case <-serverDone:
return
case <-ticker.C:
counter += 1
}
}
}
如何解决上面说的问题?
要么就不要用定时器
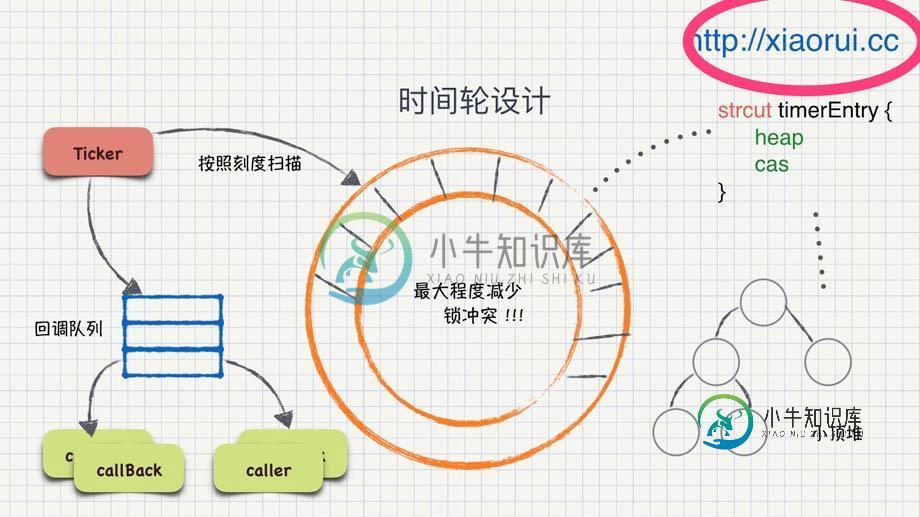
如果非要使用,可以把时间精度放大,或者 自定义定时器,比如开发一个时间轮,时间轮的刻度可以配置成一毫秒,这样可以收敛很多的定时任务。 时间轮也是各大公司推荐的方案。
可以参考下面时间轮的实现…
END
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对小牛知识库的支持。
-
问题内容: 关闭。 这个问题是题外话。它当前不接受答案。 想改善这个问题吗? 更新问题,使其成为Stack Overflow 的主题。 7年前关闭。 最近,我的服务器CPU性能一直很高。 CPU平均负载为13.91(1分钟)11.72(5分钟)8.01(15分钟),而我的站点的流量仅略有增加。 运行完最高命令后,我看到MySQL使用的CPU是160%! 最近,我一直在优化表,并切换到持久连接。这会
-
我对wowza中的cpu使用有问题。 这是可疑的线程。这个线程被占用了高CPU。 这个线程占用了大量cpu。这是jdk bug还是其他? 这是我的环境。 CentOS 5.4版(最终版) WowzaMediaServer-3.1.2 java版本1.6.0_23 java(TM)SE Runtime Environment(构建1.6.0_23-b05)java HotSpot(TM)64位服务器
-
我正在使用mod安全规则https://github.com/SpiderLabs/owasp-modsecurity-crs清理用户输入数据。在将用户输入与mod security rule正则表达式匹配时,我面临着cpu激增和延迟。总的来说,它包含500个正则表达式来检查不同类型的攻击(xss、badrobots、generic和sql)。对于每个请求,我检查所有参数并对照所有这500个正则表
-
问题内容: 我的目标是使我们的Redis服务器在生产中达到约80%的CPU利用率。通过确保我们不会利用CPU不足,同时为增长和高峰留出一些空间,这将有益于后端服务器设计。 使用Redis自己的基准测试工具时,很容易达到100%的CPU使用率: 在此基准上,我们分配了50个客户端以将1,000,000个请求推送到我们的Redis服务器。 但是在使用其他客户端工具(例如redis-lua或webdis
-
我们正在使用带有 5 个代理的 Apache Kafka 2.2 版本。我们每天收到 50 数百万个事件,但我们达到了高 kafka CPU 使用率。我们使用默认的生产者/消费者/代理设置。 我对表演有一些疑问; 我们有不同的kafka流应用程序,它们进行聚合或连接操作以携带丰富的消息。我们所有的kafka-流应用程序都包含以下设置: < li >恰好一次:true < li >最小同步副本:3
-
我有: a)1台服务器(4vcpu,8GB)运行hazelcast节点, b)1台(4vcpu,8MB)运行tomcat 7上的hazelcash性能中心。 两台服务器都在同一个本地网络中。 我已经测试了2个场景:< br >场景1)我已经开始了a)和b)。没有传输数据。a)上的cpu使用率为0-10%。< br >情景2)我已经开始了a)和b)。我已经将大量数据转移到a)上进行处理,并一直等到它