
Tensorflow 训练自己的数据集将数据直接导入到内存

制作自己的训练集
下图是我们数据的存放格式,在data目录下有验证集与测试集分别对应iris_test, iris_train
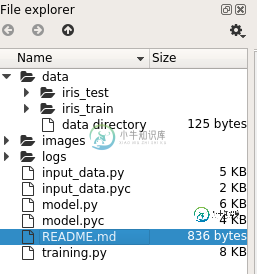
为了向伟大的MNIST致敬,我们采用的数据名称格式和MNIST类似
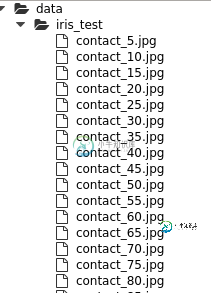
classification_index.jpg
图像的index都是5的整数倍是因为我们选择测试集的原则是每5个样本,选择一个样本作为测试集,其余的作为训练集和验证集
生成这样数据的过程相对简单,如果有需要python代码的,可以给我发邮件,或者在我的github下载
至此,我们的训练集,测试集,验证集就生成成功了,之所以我们的文件夹只有训练集和测试集是因为我们在后续的训练过程中,会在训练集中分出一部分作为验证集,所以两者暂时合称为训练集
将数据集写入到Tensorflow中
1. 直接写入到队列中
import tensorflow as tf import numpy as np import os train_dir = '/home/ruyiwei/data/iris_train/'#your data directory def get_files(file_dir): ''' Args: file_dir: file directory Returns: list of images and labels ''' iris = [] label_iris = [] contact = [] label_contact = [] for file in os.listdir(file_dir): name = file.split('_') if name[0]=="iris": iris.append(file_dir + file) label_iris.append(0) else: contact.append(file_dir + file) label_contact.append(1) print('There are %d iris\nThere are %d contact' %(len(iris), len(contact))) image_list = np.hstack((iris, contact)) label_list = np.hstack((label_iris, label_contact)) temp = np.array([image_list, label_list]) temp = temp.transpose() np.random.shuffle(temp) image_list = list(temp[:, 0]) label_list = list(temp[:, 1]) label_list = [int(i) for i in label_list] return image_list, label_list
为了大家更方便的理解和修改代码,我们对代码进行讲解如下
1-3行 : 导入需要的模块
5行: 定义训练集合的位置,这个需要根据自己的机器进行修改
7行: 定义函数 get_files
18行: os.listdir(file_dir) 获取指定目录file_dir下的所有文件名词,也就是我们的训练图片名称
18行:for file in os.listdir(file_dir): 遍历所有的图片
19行: name为一个数组,由于我们根据MINIST来定制的图片名词,所以file.split(‘_')会将图像名称分为两部分,第一部分为classification,通过name[0]来获得分类信息。
21行、24行:iris.append(file_dir + file)/contact.append(file_dir + file)将图像的绝对路径放入到iris/contact中
22行、25行:label_iris.append(0)/label_contact.append(1)给对应的图片贴标签
28-29行:将二分类的图像与标签压入到list中
31-33行:合并二分类图像,然后打乱
38行:返回打乱后对应的图像与标签
在spyder下执行如上代码后会返回如下信息

这样图像和标签信息就被load到了内存中,我们接下来就可以利用现有的模型对图像进行分类训练,模型的选择和训练的过程,我们会在后面进行讲解。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持小牛知识库。
-
问题内容: 我是TensorFlow的新手。我正在寻找有关图像识别的帮助,可以在其中 训练自己的图像 数据集。 有没有训练新数据集的示例? 问题答案: 如果您对如何在TensorFlow中输入自己的数据感兴趣,可以查看本教程。 我也写与CS230的最佳做法指南在斯坦福这里。 新答案(带有)和带有标签 随着in的引入,我们可以创建一批没有占位符且没有队列的图像。步骤如下: 创建一个包含图像文件名的列
-
问题内容: 因此,我一直遵循Google的官方tensorflow指南,并尝试使用Keras构建一个简单的神经网络。但是,在训练模型时,它不使用整个数据集(具有60000个条目),而是仅使用1875个条目进行训练。有可能解决吗? 输出: 这是我一直在为此工作的原始Google colab笔记本:https ://colab.research.google.com/drive/1NdtzXHEpiN
-
我有文件及其非常大的文件说100MB文件。我想执行NER以提取组织名称。我使用OpenNLP进行了培训。 示例代码: 但是我得到了一个错误:。 有没有办法使用openNLP for NER来训练大型数据集?你能发布示例代码吗? 当我谷歌时,我发现Class GIS和DataIndexer界面可用于训练大型数据集,但我知道如何训练?你能发布示例代码吗?
-
我是opennlp新手,需要帮助来定制解析器 我已经使用了带有预训练模型的opennlp解析器en-pos-maxtent.bin用相应的语音部分标记新的原始英语句子,现在我想自定义标签。 例句:狗跳过墙。 使用en-pos-maxtent.bin进行POS标记后,结果将是 狗-NNP 跳跃-VBD 超过-在 The-DT wall-NN 但是我想训练我自己的模型并用我的自定义标签标记单词,例如
-
问题内容: 我有一个很大的数据集,想将其分为训练(50%)和测试集(50%)。 假设我有100个示例存储了输入文件,每一行包含一个示例。我需要选择50条线作为训练集和50条线测试集。 我的想法是首先生成一个长度为100(值范围从1到100)的随机列表,然后将前50个元素用作50个训练示例的行号。与测试集相同。 这可以在Matlab中轻松实现 但是如何在Python中完成此功能?我是Python的新
-
问题内容: 我想跑 分句。没有训练模型,因此我将单独训练模型,但是我不确定我使用的训练数据格式是否正确。 我的训练数据是每行一句话。我找不到与此有关的任何文档,只有此线程(https://groups.google.com/forum/#!topic/nltk- users/bxIEnmgeCSM )揭示了一些有关训练数据格式的信息。 句子标记器的正确训练数据格式是什么? 问题答案: 嗯,是的,P