
JDK源码分析之String、StringBuilder和StringBuffer

前言
本文主要介绍了关于JDK源码分析之String、StringBuilder和StringBuffer的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧
String类的申明
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {…}
String类用了final修饰符,表示它不可以被继承,同时还实现了三个接口, 实现Serializable接口表示String类可被序列化;实现Comparable<T> 接口主要是提供一个compareTo 方法用于比较String字符串;还实现了CharSequence 接口,这个接口代表的是char值得一个可读序列(CharBuffer, Segment, String, StringBuffer, StringBuilder也都实现了CharSequence接口)
String主要字段、属性说明
/*字符数组value,存储String中实际字符 */
private final char value[];
/*字符串的哈希值 默认值0*/
private int hash;
/*字符串的哈希值 默认值0*/
/*一个比较器,用来排序String对象, compareToIgnoreCase方法中有使用 */
public static final Comparator<String> CASE_INSENSITIVE_ORDER
= new CaseInsensitiveComparator();
String 部分方法分析
String类提供了系列的构造函数,其中有几个都已经不推荐使用了,如下图:
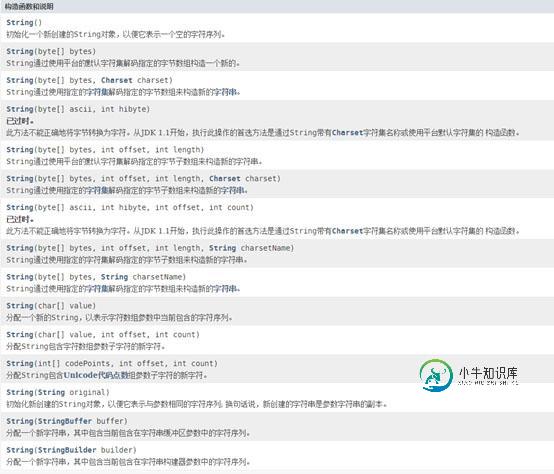
构造函数
以下是两个常用的构造函数的实现:
//String str = new String(“123”)
public String(String original) {
this.value = original.value;
this.hash = original.hash;
}
//String str3 = new String(new char[] {'1','2','3'});
public String(char value[]) {
//将字符数组值copy至value
this.value = Arrays.copyOf(value, value.length);
}
boolean equals(Object anObject)
String 类重写了 equals 方法,将此字符串与指定的对象比较。当且仅当该参数不为 null,并且是与此对象表示相同字符序列的 String 对象时,结果才为 true。
public boolean equals(Object anObject) {
//直接将对象引用相比较,相同返回true
if (this == anObject) {
return true;
}
//比较当前对象与anObject的字符序列value
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
int compareTo(String anotherString)
逐位比较两个字符串的字符序列,如果某一位字符不相同,则返回该位的两个字符的Unicode 值的差,所有位都相同,则计算两个字符串长度之差,两个字符串相同则返回0
public int compareTo(String anotherString) {
int len1 = value.length;
int len2 = anotherString.value.length;
//取长度较小的字符串的长度
int lim = Math.min(len1, len2);
char v1[] = value;
char v2[] = anotherString.value;
int k = 0;
while (k < lim) {
//将两个字符串的字符序列value逐个比较,如果不等,则返回该位置两个字符的Unicode 之差
char c1 = v1[k];
char c2 = v2[k];
if (c1 != c2) {
return c1 - c2; //返回Unicode 之差
}
k++;
}
//长度较小的字符串所有位都比较完,则返回两个字符串长度之差
//如果两个字符串相同,那么长度之差为0,即相同字符串返回0
return len1 - len2;
}
compareToIgnoreCase(String str)方法实现于此类似,比较时忽略字符的大小写,实现方式如下:
public int compare(String s1, String s2) {
int n1 = s1.length();
int n2 = s2.length();
int min = Math.min(n1, n2);
for (int i = 0; i < min; i++) {
char c1 = s1.charAt(i);
char c2 = s2.charAt(i);
if (c1 != c2) {
c1 = Character.toUpperCase(c1);
c2 = Character.toUpperCase(c2);
if (c1 != c2) {
c1 = Character.toLowerCase(c1);
c2 = Character.toLowerCase(c2);
if (c1 != c2) {
// No overflow because of numeric promotion
return c1 - c2;
}
}
}
}
return n1 - n2;
}
native String intern()
当调用 intern 方法时,如果池已经包含一个等于此 String 对象的字符串(用 equals(Object) 方法确定),则返回池中的字符串。否则,将此 String 对象添加到池中,并返回此 String 对象的引用。
所有字面值字符串和字符串赋值常量表达式都使用 intern 方法进行操作,例如:String str1 = "123";
String内存位置:常量池OR堆
String对象可以直接通过字面量创建,也可以通过构造函数创建,有什么区别呢?
1.通过字面量或者字面量字符串通过”+”拼接的方式创建的String对象存储在常量池中,实际创建时如果常量池中存在,则直接返回引用,如果不存在则创建该字符串对象
2.使用构造函数创建字符串对象,则直接在堆中创建一个String对象
3.调用intern方法,返回则会将该对象放入常量池(不存在则放入常量池,存在则返回引用)
下面举例说明String对象内存分配情况:
String str1 = new String("123");
String str2 = "123";
String str3 = "123";
String str4 = str1.intern();
System.out.println(str1==str2); // false str1在堆中创建对象,str2在常量池中创建对象
System.out.println(str2==str3); // true str2在常量池中创建对象,str3直接返回的str2创建的对象的引用 所以str2和str3指向常量池中同一个对象
System.out.println(str4==str3); // true str4返回常量池中值为"123"的对象,因此str4和str2、str3都相等
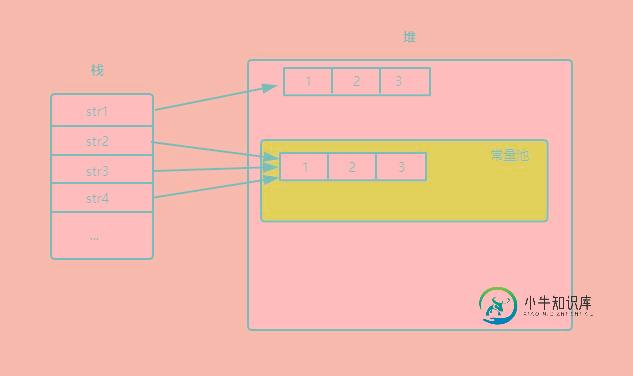
关于字符串拼接示例:
public class StringTest {
public static final String X = "ABC"; // 常量X
@Test
public void Test() {
String str5 = new String("ABC");
String str6 = str5+"DEF"; //堆中创建
String str7 = "ABC"+"DEF"; //常量池
String str8 = X+"DEF"; //X为常量,值是固定的,因此X+"DEF"值已经定下来为ABCDEF,实际上编译后得代码相当于String str8 = "ABCDEF"
String str9 = "ABC";
String str10 = str9+"DEF"; //堆中
System.out.println(str6==str7); //false
System.out.println(str8==str7); //true
System.out.println(str10==str7); //false
System.out.println(X==str9); //true
} }
反编译后的代码看一下便一目了然:

内存分配如下:
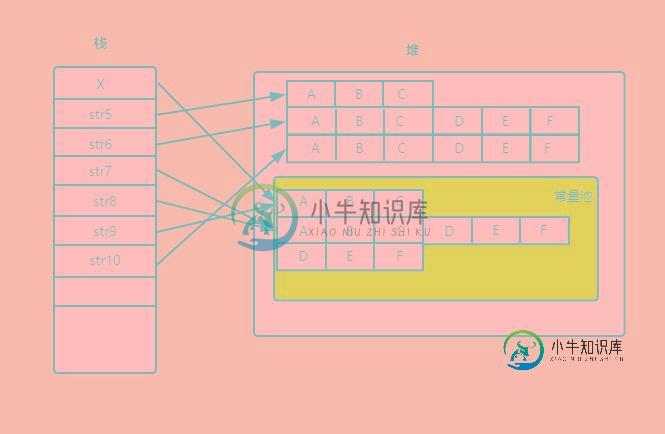
String、StringBuffer、StringBuilder
由于String类型内部维护的用于存储字符串的属性value[]字符数组是用final来修饰的:
/** The value is used for character storage. */ private final char value[];
表明在赋值后可以再修改,因此我们认为String对象一经创建后不可变,在开发过程中如果碰到频繁的拼接字符串操作,如果使用String提供的contact或者直接使用”+”拼接字符串会频繁的生成新的字符串,这样使用显得低效。Java提供了另外两个类:StringBuffer和StringBuilder,用于解决这个问题:
看一下下面的代码:
String str1="123"; String str2="456"; String str3="789"; String str4 = "123" + "456" + "789"; //常量相加,编译器自动识别 String str4=“123456789” String str5 = str1 + str2 + str3; //字符串变量拼接,推荐使用StringBuilder StringBuilder sb = new StringBuilder(); sb.append(str1); sb.append(str2); sb.append(str3);
下面是StringBuilder类的实现,只截取了分析的部分代码:
public final class StringBuilder
extends AbstractStringBuilder
implements java.io.Serializable, CharSequence
{
//拼接字符串
@Override
public StringBuilder append(String str) {
//调用父类AbstractStringBuilder.append super.append(str); return this; } }
abstract class AbstractStringBuilder implements Appendable, CharSequence {
/**
* 存储字符串的字符数组,非final类型,区别于String类
*/
char[] value;
/**
* The count is the number of characters used.
*/
int count;
public AbstractStringBuilder append(String str) {
if (str == null)
return appendNull();
int len = str.length();
//检查是否需要扩容
ensureCapacityInternal(count + len);
//字符串str拷贝至value
str.getChars(0, len, value, count);
count += len;
return this;
}
private void ensureCapacityInternal(int minimumCapacity) {
// overflow-conscious code
// minimumCapacity=count+str.length
//拼接上str后的容量 如果 大于value容量,则扩容
if (minimumCapacity - value.length > 0) {
//扩容,并将当前value值拷贝至扩容后的字符数组,返回新数组引用
value = Arrays.copyOf(value,
newCapacity(minimumCapacity));
}
}
//StringBuilder扩容
private int newCapacity(int minCapacity) {
// overflow-conscious code
// 计算扩容容量
// 默认扩容后的数组长度是按原数(value[])组长度的2倍再加上2的规则来扩展,为什么加2?
int newCapacity = (value.length << 1) + 2;
if (newCapacity - minCapacity < 0) {
newCapacity = minCapacity;
}
return (newCapacity <= 0 || MAX_ARRAY_SIZE - newCapacity < 0)
? hugeCapacity(minCapacity)
: newCapacity;
}
}
StringBuffer和StringBuilder用一样,内部维护的value[]字符数组都是可变的,区别只是StringBuffer是线程安全的,它对所有方法都做了同步,StringBuilder是线程非安全的,因此在多线程操作共享字符串变量的情况下字符串拼接处理首选用StringBuffer, 否则可以使用StringBuilder,毕竟线程同步也会带来一定的消耗。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对小牛知识库的支持。
-
本文向大家介绍JDK源码之PriorityQueue解析,包括了JDK源码之PriorityQueue解析的使用技巧和注意事项,需要的朋友参考一下 一.优先队列的应用 优先队列在程序开发中屡见不鲜,比如操作系统在进行进程调度时一种可行的算法是使用优先队列,当一个新的进程被fork()出来后,首先将它放到队列的最后,而操作系统内部的Scheduler负责不断地从这个优先队列中取出优先级较高的进程执行
-
ethereum的虚拟机源码所有部分在core/vm下。 去除测试总共有24个源码文件。 整个vm调用的入口在go-ethereum/core/state_transaction.go中。 我们主要是为了分析虚拟机源码,所以关于以太坊是如何进行交易转账忽略过去。 从上面的截图我们可以看出, 当以太坊的交易中to地址为nil时, 意味着部署合约, 那么就会调用evm.Create方法。 否则调用了e
-
以下是输出 第1行返回,第3行返回false。 我不明白为什么编译器不认为“name1”和“sb”包含相同的值 类似地,编译器并不认为“s”和“sb”包含相同的字符串(都是非原语)。 有人能解释一下line1和line3的输出吗?
-
本文向大家介绍JUC之Semaphore源码分析,包括了JUC之Semaphore源码分析的使用技巧和注意事项,需要的朋友参考一下 Semaphore 主要用于限量控制并发执行代码的工具类, 其内部通过 一个 permit 来进行定义并发执行的数量。 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持呐喊教程。
-
区块链技术是计算机技术与金融技术交融的成功创新,被认为是极具潜力的分布式账本平台的核心技术。如果你还不了解区块链,可以阅读 区块链技术指南。
-
Memcached源码分析共8篇文章,前7篇文章主要分析每个模块的c源代码。这一篇文章主要是将之前的流程串起来,总结和回顾。同时通过这篇文章可以全局去看Memcached的结构。 一、Memcache的网络模型 Memcached主要是基于Libevent 网络事件库进行开发的。 Memcached的网络模型分为两部分:主线程和工作线程。主线程主要用来接收客户端的连接信息;工作线程主要用来接管客户