
使用rst2pdf实现将sphinx生成PDF

当初项目文档是用sphinx写的,一套rst下来make html得到一整个漂亮的在线文档。现在想要将文档导出为离线的handbook pdf,于是找到了rst2pdf这个项目,作为sphinx的拓展,然后加上少量配置即可输出中文PDF。
rst2pdf
简介
rst2pdf是一个将 reStructuredText 转换为 PDF 的工具,具有下列特性:
安装
easy_install rst2pdf
配置rst2pdf
注册到sphinx项目
需要告诉sphinx我们安装了rst2pdf,并且将其作为插件使用。只需在项目根目录下的conf.py中配置:
# Add any Sphinx extension module names here, as strings. They can be # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom # ones. extensions = [ 'sphinx.ext.autodoc', 'rst2pdf.pdfbuilder' ]
即可。然后,在conf.py中拷入PDF相关的配置:
# -- Options for PDF output --------------------------------------------------
# Grouping the document tree into PDF files. List of tuples
# (source start file, target name, title, author, options).
#
# If there is more than one author, separate them with \\.
# For example: r'Guido van Rossum\\Fred L. Drake, Jr., editor'
#
# The options element is a dictionary that lets you override
# this config per-document.
# For example,
# ('index', u'MyProject', u'My Project', u'Author Name',
# dict(pdf_compressed = True))
# would mean that specific document would be compressed
# regardless of the global pdf_compressed setting.
pdf_documents = [
('index', u'HanLP Handbook', u'HanLP Handbook', u'hankcs'),
]
# A comma-separated list of custom stylesheets. Example:
pdf_stylesheets = ['a3','zh_CN']
# Create a compressed PDF
# Use True/False or 1/0
# Example: compressed=True
#pdf_compressed = False
# A colon-separated list of folders to search for fonts. Example:
pdf_font_path = ['C:\\Windows\\Fonts']
# Language to be used for hyphenation support
pdf_language = "zh_CN"
# Mode for literal blocks wider than the frame. Can be
# overflow, shrink or truncate
pdf_fit_mode = "shrink"
# Section level that forces a break page.
# For example: 1 means top-level sections start in a new page
# 0 means disabled
#pdf_break_level = 0
# When a section starts in a new page, force it to be 'even', 'odd',
# or just use 'any'
#pdf_breakside = 'any'
# Insert footnotes where they are defined instead of
# at the end.
#pdf_inline_footnotes = True
# verbosity level. 0 1 or 2
#pdf_verbosity = 0
# If false, no index is generated.
#pdf_use_index = True
# If false, no modindex is generated.
#pdf_use_modindex = True
# If false, no coverpage is generated.
#pdf_use_coverpage = True
# Documents to append as an appendix to all manuals.
#pdf_appendices = []
# Enable experimental feature to split table cells. Use it
# if you get "DelayedTable too big" errors
#pdf_splittables = False
# Set the default DPI for images
#pdf_default_dpi = 72
# Enable rst2pdf extension modules (default is only vectorpdf)
# you need vectorpdf if you want to use sphinx's graphviz support
#pdf_extensions = ['vectorpdf']
# Page template name for "regular" pages
#pdf_page_template = 'cutePage'
# Show Table Of Contents at the beginning?
# pdf_use_toc = False
# How many levels deep should the table of contents be?
pdf_toc_depth = 2
# Add section number to section references
pdf_use_numbered_links = False
# Background images fitting mode
pdf_fit_background_mode = 'scale'
具体配置项的值请自行调整,不需要严格按照我的来。
样式表
在项目根目录下创建一个zh_CN.json,写入:
{
"embeddedFonts": [
"simsun.ttc"
],
"fontsAlias": {
"stdFont": "simsun",
"stdBold": "simsun",
"stdItalic": "simsun",
"stdBoldItalic": "simsun",
"stdMono": "simsun",
"stdMonoBold": "simsun",
"stdMonoItalic": "simsun",
"stdMonoBoldItalic": "simsun",
"stdSans": "simsun",
"stdSansBold": "simsun",
"stdSansItalic": "simsun",
"stdSansBoldItalic": "simsun"
},
"styles": [
[
"base",
{
"wordWrap": "CJK"
}
],
[
"literal",
{
"wordWrap": "None"
}
]
]
}
关于以上样式的说明:
embeddedFonts用于嵌入字体,经试验,必须包含至少四个值才不会报错。不过这四个字体值可以是重复的。
fontsAlias用来指定各类字形用什么字体。如stdFont指正文字体,stdBold指粗体,stdItalic指斜体。其他的还有stdBoldItalic粗斜体,stdMono等宽体,等等。确保所用字体已经安装在你的操作系统上,且字体必须是TTF类型的(Windows环境下限制比较多~)。
wordWrap用于指定换行规则,CJK就是适用于中日韩文字的规则。这是从网上的模板抄来的,但经我的测试发现,如果用CJK规则的话,中英混排的文档里面英文部分就没法正常断行,这真是个遗憾。实际上,fontsAlias的分类很多都只对英文字体有意义,如严格来讲中文是没有所谓斜体的(不过因为Word的普及,经常看到中文被设置为斜体的情形)。如果是纯中文文档,当然随便用哪些中文字体都行,如宋体。现实中,经常会有中英文混排的情形,所以如果全用中文字体的话,英文部分就没法显示斜体等字形了。
关于pdf_stylesheets的说明:这个参数中默认使用的某些样式包含了一些字体,而这些字体并非在所有操作系统上都找得到。'sphinx'和'kerning'都是默认提供的样式,要么不用它们,要么直接修改其包含的字体。'a4'指设置输出的PDF为A4纸大小。默认的样式文件可以在rst2pdf的安装路径下找到。
然后配置编译脚本
Windows用户,在make.bat中加入:
if "%1" == "pdf" ( %SPHINXBUILD% -b pdf %ALLSPHINXOPTS% %BUILDDIR%/pdf if errorlevel 1 exit /b 1 echo. echo.Build finished. The pdf files are in %BUILDDIR%/pdf. goto end )
类Unix用户修改Makefile:
pdf: $(SPHINXBUILD) -b pdf $(ALLSPHINXOPTS) $(BUILDDIR)/pdf @echo @echo "Build finished. The PDF files are in _build/pdf."
输出PDF
然后一句:
make pdf
就能输出PDF了。
解决findfonts.py:249 Unknown font:
这应该是由于pdf_font_path配置有误造成的,事实上,我确定配置无误rst2pdf还是找不到字体文件,于是我修改了X:\Program Files (x86)\Python27\Lib\site-packages\rst2pdf\findfonts.py第236行,在
fontfile = get_nt_fname(fname)
后面加了一句:
fontfile = 'C:\\Windows\\Fonts\\simsun.ttc'
强行解决问题。
解决rst2pdf输出PDF为空白文档
事实上,在字体正常的情况下,我发现输出的PDF依然是空白的:
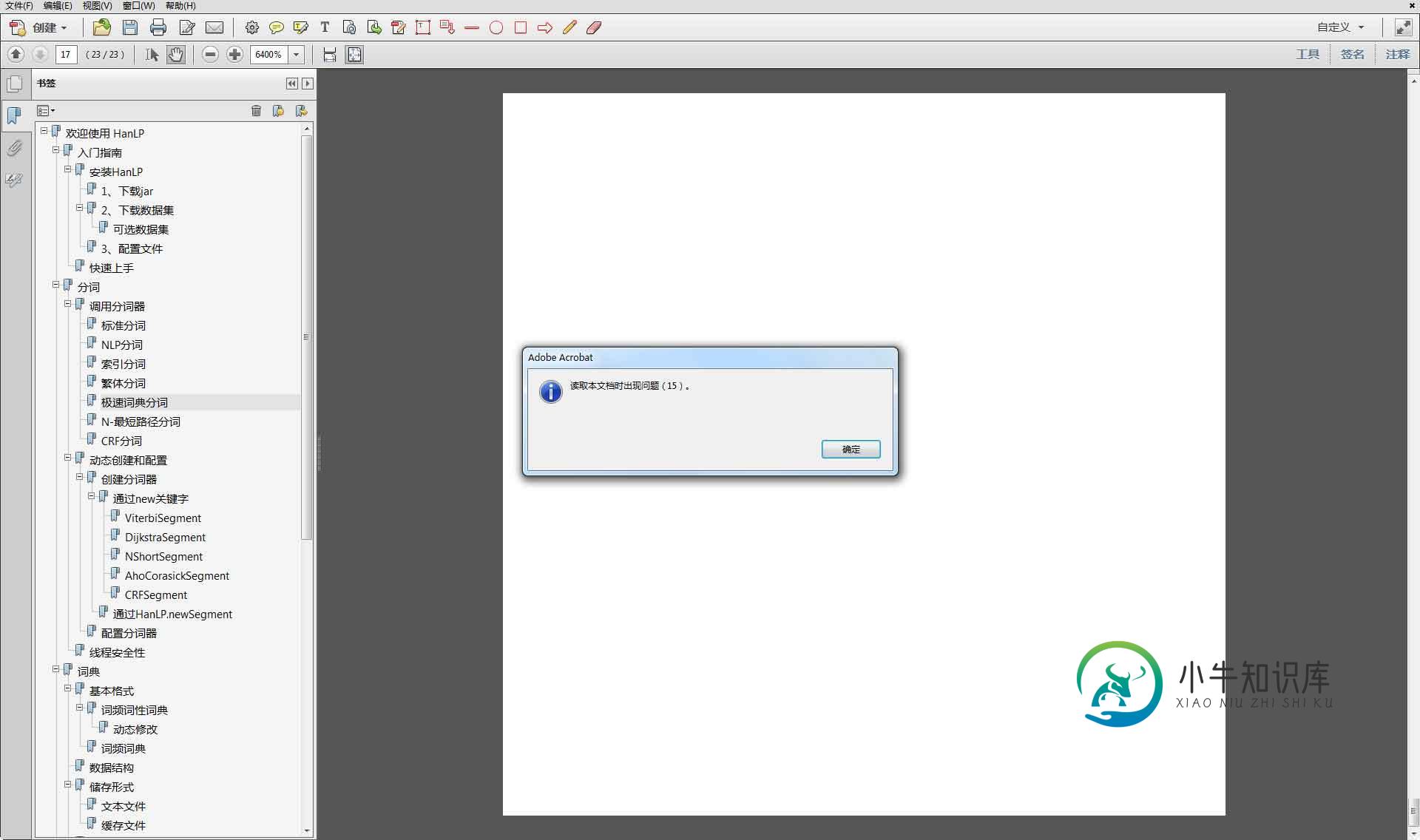
在使用二分法排除rst文件中的问题后,我发现这是由于PDF开头的目录造成的。当目录超出一页时就会发生这种情况,我倾向于认为这是rst2pdf的一个bug。
解决方法是将pdf_toc_depth调小一点,或者干脆不生成目录,pdf_use_toc = False。
PDF效果
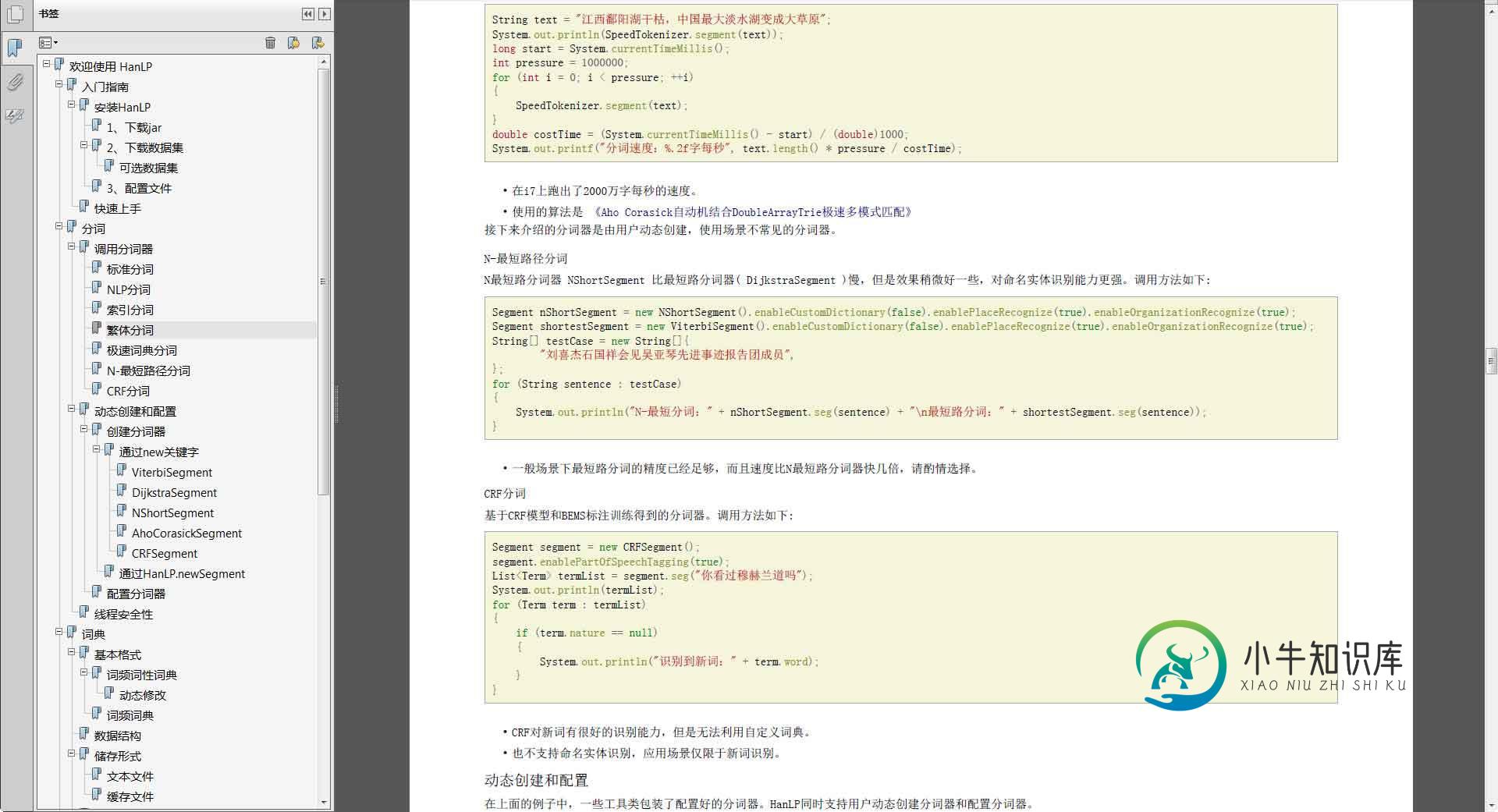
于是再次重试,可以生成漂亮的PDF了:
相关链接:
http://sphinx-users.jp/cookbook/pdf/rst2pdf.html
http://ralsina.me/static/manual.pdf
http://www.typemylife.com/sphinx-restructuredtext-pdf-generation-with-rst2pdf/
-
rst2pdf是一个用来转换reStructuredText到PDF不使用任何中间格式的工具。这个工具提供了另一种产生PDF直接使用ReportLab库。
-
本文向大家介绍使用python实现生成用户信息,包括了使用python实现生成用户信息的使用技巧和注意事项,需要的朋友参考一下 今天练习的时候要展示一个从用户信息列表,就想把他做成信息和修改在一起的一个网页,方便用户修改内容 考虑到要把信息和值分开放,那么肯定是字典了,因为需要保证位置不变,使用有序字典 考虑到需要解析方便和好看点,所以让models.py中返回的就直接是”k1 v1 k2 v2”
-
问题内容: 我一直在构建具有许多不同功能的Python模块。 我正在使用Sphinx和readthedocs提供文档。我已经取得了不错的进步,但是目前我有一个庞大的页面,该页面提供了所有功能的文档(按字母顺序)。 我看过其他项目,每个项目都有单独的页面。在查看它们的源代码时,我发现已经为每个文件创建了一个单独的.rst文件。我假设这是自动完成的,并且此页面有关生成自动文档摘要的内容似乎在描述其中的
-
本文向大家介绍Ruby中使用连续体Continuation实现生成器,包括了Ruby中使用连续体Continuation实现生成器的使用技巧和注意事项,需要的朋友参考一下 ruby中有很多经典的驱动器结构,比如枚举器和生成器等.这次简单介绍下生成器的概念.生成器是按照功能要求,一次产生一个对象,或称之为生成一个对象的方法.ruby中的连续体正好可以用来完成生成器的功能.连续体说起来晦涩,其实还是很
-
本文向大家介绍Winform实现将网页生成图片的方法,包括了Winform实现将网页生成图片的方法的使用技巧和注意事项,需要的朋友参考一下 通常浏览器都有将网页生成图片的功能,本文实例讲述了Winform实现将网页生成图片的方法。分享给大家供大家参考。具体方法如下: 工具截图如下: 生成后的图片如下: 手动填写网站地址,可选择图片类型和保持图片地址,来生成页面的图片,当图片路径未选择时则保存桌面;
-
本文向大家介绍在MySQL中使用Sphinx实现多线程搜索的方法,包括了在MySQL中使用Sphinx实现多线程搜索的方法的使用技巧和注意事项,需要的朋友参考一下 MySQL、Sphinx及许多数据库和搜索引擎中的查询是单线程的。比如说,在一台32个CPU核心、16个磁盘的R910服务器上执行一个查询,它最多只会用到一个核心和一个磁盘。没错,只会使用一个。 如果查询是CPU密集型作业,那么会使用