
python 实现多线程下载m3u8格式视频并使用fmmpeg合并

电影之类的长视频好像都用m3u8格式了,这就导致了多线程下载视频的意义不是很大,都是短视频,线不线程就没什么意义了嘛。
我们知道,m3u8的链接会下载一个文档,相当长,半小时的视频,应该有接近千行ts链接。
这些ts链接下载成ts文件,就是碎片化的视频,加以合并,就成了需要的视频。
那,即便网速很快,下几千行视频,效率也就低了,更何况还要合并。我就琢磨了一下午,怎么样才能多线程下载m3u8格式的视频呢?
先上代码,再说重难点:
import datetime
import os
import re
import threading
import requests
from queue import Queue
# 预下载,获取m3u8文件,读出ts链接,并写入文档
def down():
# m3u8链接
url = 'https://ali-video.acfun.cn/mediacloud/acfun/acfun_video/segment/3zf_GAW6nFMuDXrTLL89OZYOZ4mwxGoASH6UcZbsj1_6eAxUxtp3xm8wFmGMNOnZ.m3u8?auth_key=1573739375-474267152-0-a5aa2b6df4cb4168381bf8b04d88ddb1'
# 当ts文件链接不完整时,需拼凑
# 大部分网站可使用该方法拼接,部分特殊网站需单独拼接
base_url = re.split(r"[a-zA-Z0-9-_\.]+\.m3u8", url)[0]
# print(base_url)
resp = requests.get(url)
m3u8_text = resp.text
# print(m3u8_text)
# 按行拆分m3u8文档
ts_queue = Queue(10000)
lines = m3u8_text.split('\n')
# 找到文档中含有ts字段的行
concatfile = 'cache/' + "s" + '.txt'
for line in lines:
if '.ts' in line:
if 'http' in line:
# print("ts>>", line)
ts_queue.put(line)
else:
line = base_url + line
ts_queue.put(line)
# print('ts>>',line)
filename = re.search('([a-zA-Z0-9-]+.ts)', line).group(1).strip()
# 一定要先写文件,因为线程的下载是无序的,文件无法按照
# 123456。。。去顺序排序,而文件中的命名也无法保证是按顺序的
# 这会导致下载的ts文件无序,合并时,就会顺序错误,导致视频有问题。
open(concatfile, 'a+').write("file %s\n" % filename)
return ts_queue,concatfile
# 线程模式,执行线程下载
def run(ts_queue):
tt_name = threading.current_thread().getName()
while not ts_queue.empty():
url = ts_queue.get()
r = requests.get(url, stream=True)
filename = re.search('([a-zA-Z0-9-]+.ts)', url).group(1).strip()
with open('cache/' + filename, 'wb') as fp:
for chunk in r.iter_content(5242):
if chunk:
fp.write(chunk)
print(tt_name + " " + filename + ' 下载成功')
# 视频合并方法,使用ffmpeg
def merge(concatfile, name):
try:
path = 'cache/' + name + '.mp4'
command = 'ffmpeg -y -f concat -i %s -crf 18 -ar 48000 -vcodec libx264 -c:a aac -r 25 -g 25 -keyint_min 25 -strict -2 %s' % (concatfile, path)
os.system(command)
print('视频合并完成')
except:
print('合并失败')
if __name__ == '__main__':
name = input('请输入视频名称:')
start = datetime.datetime.now().replace(microsecond=0)
s,concatfile = down()
# print(s,concatfile)
threads = []
for i in range(15):
t = threading.Thread(target=run, name='th-'+str(i), kwargs={'ts_queue': s})
threads.append(t)
for t in threads:
t.start()
for t in threads:
t.join()
end = datetime.datetime.now().replace(microsecond=0)
print('下载耗时:' + str(end - start))
merge(concatfile,name)
over = datetime.datetime.now().replace(microsecond=0)
print('合并耗时:' + str(over - end))
效果图:

代码开始:自己输入视频名称(也可以去原网站爬名称)
查看下载耗时,fmmpeg开始合并:

合并耗时:

7分多钟,90个ts文件,接近40MB。两秒下载完成。
更大的文件,开更多的线程。
然后我们画画重难点:
第一:ts文件命名问题。
我们知道,每一个线程启动,除了队列不会重复,那么代码里都会重新跑(线程里的代码),那么,1.ts,2.ts....这种命名是不可能的了,文件会被覆盖。命名我使用了ts链接中的部分链接。
第二:合并问题。
文件的合并是根据文档内的顺序,也就是,如果边下载边合并,那么,线程的无序性导致下载无序,文件写入也就无序化了,合并时,时间线会错误,合出来的视频就无法看。因此,文件要提前写好才行,这和命名有很大的关联,看代码即知。
第三:有的m3u8是特殊处理的,代码具有一定的局限性。
写的时候挺难的,脑子都乱了,就这些吧,记录一下。
对了,贴一下下载的图:90个ts文件,一个mp4文件,一个文档。
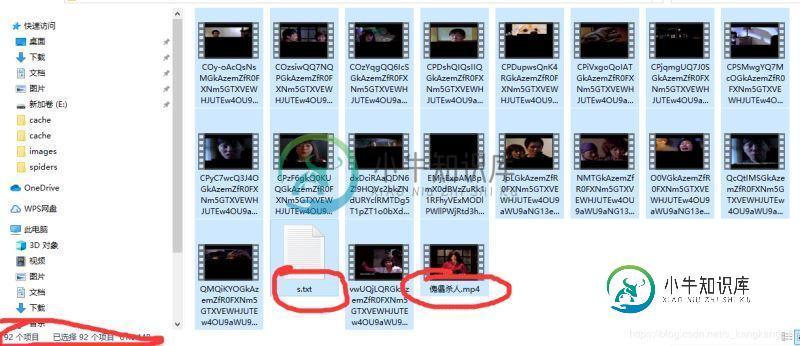
总结
以上所述是小编给大家介绍的python 实现多线程下载m3u8格式视频并使用fmmpeg合并,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对小牛知识库网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
-
本文向大家介绍python 下载m3u8视频的示例代码,包括了python 下载m3u8视频的示例代码的使用技巧和注意事项,需要的朋友参考一下 速度很慢. 40m 5分钟 不加多线程 1小时。 可能我的m3u8不行,或者我电脑不行, 多线程是机械式的。 电脑好 可以多加几条。 以上就是python 下载m3u8视频的示例代码的详细内容,更多关于python 下载m3u8视频的资料请关注呐喊教
-
本文向大家介绍python3.6根据m3u8下载mp4视频,包括了python3.6根据m3u8下载mp4视频的使用技巧和注意事项,需要的朋友参考一下 需要下载某网站的视频,chrome浏览器按F12打开开发者模式,发现视频链接是以"blob:http"开头的链接,打开这个链接后找不到网页,网上查了下,找到了下载方法,在这里做个记录,如果有错误,欢迎指出。 程序在Windows 10下运行,不过L
-
本文向大家介绍python实现多线程网页下载器,包括了python实现多线程网页下载器的使用技巧和注意事项,需要的朋友参考一下 本文为大家分享了python实现的一个多线程网页下载器,供大家参考,具体内容如下 这是一个有着真实需求的实现,我的用途是拿它来通过 HTTP 方式向服务器提交游戏数据。把它放上来也是想大家帮忙挑刺,找找 bug,让它工作得更好。 keywords:python,http,
-
我已经使用程序youtube-dl下载了一个YouTube播放列表,我选择了单独下载视频和音频,我现在有一个文件夹充满了视频及其相应的音频,我希望与ffmpeg合并在一起。 我需要使用批处理脚本来执行此操作,但问题是youtube-dl在原始文件的标题之后添加了临时字母,因此视频与其对应的音频没有相同的名称,文件名如下所示: 如何使用windows批处理脚本和ffmpeg合并这些多个视频/音频文件
-
本文向大家介绍python 多线程将大文件分开下载后在合并的实例,包括了python 多线程将大文件分开下载后在合并的实例的使用技巧和注意事项,需要的朋友参考一下 废话不多说了,上代码吧: 以上这篇python 多线程将大文件分开下载后在合并的实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持呐喊教程。
-
我正在开发一个可以流式传输. m3u8播放列表(HLS播放)中的音频流的项目。我正在为上述目的使用Videojs。当我使用. m3u8和(. ts)格式的视频时,一切都很顺利。这些流在所有主要浏览器中播放。代码如下: 和html格式 该代码适用于包含<代码>位的HLS。ts视频流。 现在,我的流提供程序通过给我