
python学习将数据写入文件并保存方法

python将文件写入文件并保存的方法:
使用python内置的open()函数将文件打开,用write()函数将数据写入文件,最后使用close()函数关闭并保存文件,这样就可以将数据写入文件并保存了。
示例代码如下:
file = open("ax.txt", 'w')
file.write('hskhfkdsnfdcbdkjs')
file.close()
执行结果:
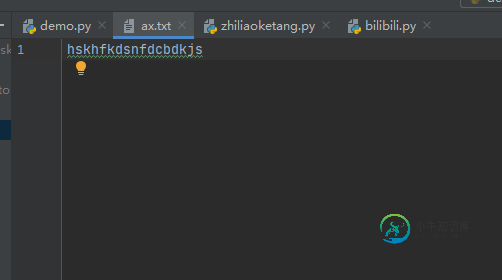
内容扩展:
python将字典中的数据保存到文件中
d = {'a':'aaa','b':'bbb'}
s = str(d)
f = open('dict.txt','w')
f.writelines(s)
f.close()
实例2:
def main():
list1 = [['西瓜','兰州','first',20],['香蕉','西安','second',30],['苹果','银川','third',40],['桔子','四川','fourth',40]]
output = open('data.xls','w',encoding='gbk')
output.write('fruit\t place\t digital\t number\n')
for i in range(len(list1)):
for j in range(len(list1[i])):
output.write(str(list1[i][j])+' ')
output.write('\t')
output.write('\n')
output.close()
if __name__ == '__main__':
main()
到此这篇关于python学习将数据写入文件并保存方法的文章就介绍到这了,更多相关python将数据写入文件并保存详解内容请搜索小牛知识库以前的文章或继续浏览下面的相关文章希望大家以后多多支持小牛知识库!
-
我正在编写一个文件编写器,它将ID和名称(这两个字符串)写入文本文件。这需要用户输入,然后将数据存储在txt文件中。但是,当我再次运行它时,任何新数据都会覆盖以前的数据,因此数据永远不会保存到txt文件中。 谁能告诉我如何保存这些数据,以便添加的任何新数据都存储在下一行,而不覆盖上一行? 谢啦
-
问题内容: 我有这个项目: 导入文件 连接到SQL Server数据库 将所有数据转移到数据库中 文本文件按选项卡划分为四个字段,例如数据库。 我已经完成了使用富文本框并将所有数据保存在字符串中的第一步。我的想法是将字符串拆分为每行并将其保存在数组中,然后:如何拆分每一行,以便可以正确保存字段?如何将SQL Server上的数据库连接到C#上的项目? 问题答案: 让我们一次解决这一步骤… 获取数据
-
问题内容: Python新手对csv模块感到有点沮丧。以这种速度,如果我自己编写文件解析器会更容易,但是我想用Pythonic的方式做事情。 我写了一个小python脚本,应该将我的数据保存到CSV文件中。 这是我的代码片段: 文件myfile.csv已成功创建,但为空-但已锁定,因为Python进程仍在使用它。似乎数据已写入内存中的文件,但尚未刷新到磁盘。 由于Python进程在文件上持有锁,因
-
本文向大家介绍Python将json文件写入ES数据库的方法,包括了Python将json文件写入ES数据库的方法的使用技巧和注意事项,需要的朋友参考一下 1、安装Elasticsearch数据库 PS:在此之前需首先安装Java SE环境 下载elasticsearch-6.5.2版本,进入/elasticsearch-6.5.2/bin目录,双击执行elasticsearch.bat 打开浏览
-
问题内容: 我正在尝试重组在Excel文件中组织降水数据的方式。为此,我编写了以下代码: 这段代码运行良好,通过Jupyter,我可以看到结果是不错的 但是,尝试将此数据帧保存到csv文件时遇到问题。 结果文件包含垂直索引列,看来我无法调用特定的单元格。 (希望有人可以帮助我解决这个问题)非常感谢! 问题答案: 全部在文档中。 您有兴趣跳过索引列,因此: 如果您还想跳过标题,请添加: 我不知道您的
-
(希望有人能帮我解决这个问题)非常感谢!!