
使用Numpy对特征中的异常值进行替换及条件替换方式

原始数据为Excel文件,由传感器获得,通过Pyhton xlrd模块读入,读入后为数组形式,由于其存在部分异常值和缺失值,所以便利用Numpy对其中的异常值进行替换或条件替换。
1. 将'nan'替换为给定值
import numpy as np data = np.array([['nan', 1, 2, 3, 4], # 数据类型为字符串型 [10, 15, 20, 25, 'nan'], ['nan', 5, 8, 10, 20]]) print(data) # [['nan' '1' '2' '3' '4'] # ['10' '15' '20' '25' 'nan'] # ['nan' '5' '8' '10' '20']] data[data == 'nan'] = 100 # 将numpy中为'nan'的项替换为 100 print(data) # [['100' '1' '2' '3' '4'] # ['10' '15' '20' '25' '100'] # ['100' '5' '8' '10' '20']] data = data.astype(float) # 将数据由字符型转换为浮点型 print(data) # [[100. 1. 2. 3. 4.] # [ 10. 15. 20. 25. 100.] # [100. 5. 8. 10. 20.]]
2. 按列进行条件替换
当利用'3σ准则'或者箱型图进行异常值判断时,通常需要对 > upper 或 < lower的值进行处理,这时就需要按列进行条件替换了。
print(data) # [[100. 1. 2. 3. 4.] # [ 10. 15. 20. 25. 100.] # [100. 5. 8. 10. 20.]] data[:, 1][data[:, 1] < 5] = 5 # 对第2列小于 5 的替换为5 print(data) # [[100. 5. 2. 3. 4.] # [ 10. 15. 20. 25. 100.] # [100. 5. 8. 10. 20.]] data[:, 2][data[:, 2] > 15] = 10 # 对第3列大于 15 的替换为10 print(data) # [[100. 5. 2. 3. 4.] # [ 10. 15. 10. 25. 100.] # [100. 5. 8. 10. 20.]]
补充知识:Python之dataframe修改异常值—按行判断值是否大于平均值的指定倍数,如果是则用均值替换
如下所示:
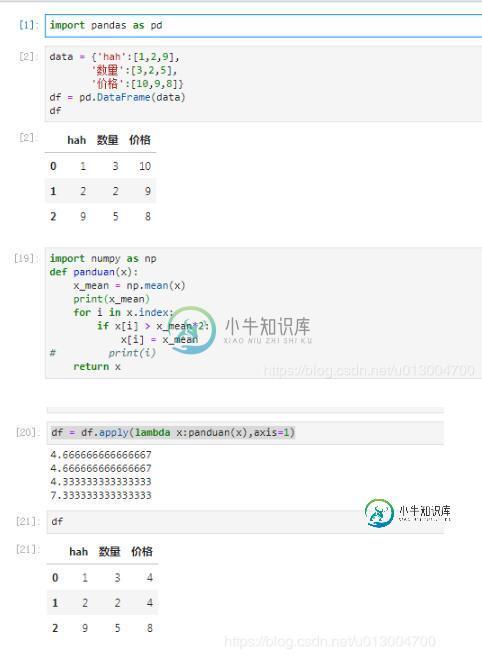
import pandas as pd
data = {'hah':[1,2,9],
'数量':[3,2,5],
'价格':[10,9,8]}
df = pd.DataFrame(data)
df
import numpy as np
def panduan(x):
x_mean = np.mean(x)
print(x_mean)
for i in x.index:
if x[i] > x_mean*2:
x[i] = x_mean
# print(i)
return x
df = df.apply(lambda x:panduan(x),axis=1)
以上这篇使用Numpy对特征中的异常值进行替换及条件替换方式就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持小牛知识库。
-
问题内容: 有没有一种简单的方法可以将数组中的所有负值都替换为0? 我对如何使用NumPy数组有一个完整的了解。 例如 我要回去 给出: 这就是我遇到的问题-如何使用此数组修改原始数组。 问题答案: 你在那儿 尝试:
-
我有一个数据集,包含一系列国家和年份的几个指标的值(3072,1134行和列),但有些NaN。 下面是数据集的示例: 我想根据提交的
-
我正在从文本文件中读取预订系统的座位数据,并将其写入ArrayList中。一个行将被放入一个可变的fileline中。文件行是从每个“,”中拆分出来的,并放入名为Components的数组中。然后将组件放入对象中。 txt文件示例 然后进入一个if语句,检查座位是否合适,如果合适,我想将false更改为true,并将乘客名添加为null,但只在合适的座位上。我想知道是否有任何方法可以覆盖文本文件中
-
问题内容: 我的apicontroller返回了以下JSON对象: 我要替换为 我已经尝试了下面的代码,但它仅代替的第一次出现。如何替换所有条目? 谢谢, 问题答案: 您需要使替换全局: 这样,它将继续替换null直到到达结尾 正则表达式文档: https://developer.mozilla.org/zh- CN/docs/Web/JavaScript/Reference/Global_Obj
-
问题内容: 我可能在做一些非常愚蠢的事情,但是我很沮丧。 我有一个数据框,我想用超过零的值替换特定列中的值。我以为这是实现此目标的一种方式: 如果将通道复制到新的数据框中,这很简单: 这完全符合我的要求,但似乎无法与通道一起用作原始数据帧的一部分。 问题答案: 可以在0.20.0之前的熊猫版本上正常工作,但是由于pandas为0.20.0 ,因此不推荐使用,因此应避免使用它。而是可以使用或索引器。
-
问题内容: 我有一个需要处理的大型numpy数组,以便在满足条件的情况下将每个元素更改为1或0(稍后将用作像素遮罩)。数组中大约有800万个元素,而我当前的方法对于简化流程花费的时间太长: 是否有一个numpy函数可以加快速度? 问题答案: 您可以使用以下方法来缩短它: