
C语言中的链接编写教程

链接
链接就是将不同部分的代码和数据收集和组合成为一个单一文件的过程,这个文件可被加载或拷贝到存储器执行.
链接可以执行与编译时(源代码被翻译成机器代码时),也可以执行与加载时(在程序被加载器加载到存储器并执行时),甚至执行与运行时,由应用程序来执行.在现代系统中,链接是由链接器自动执行的.
链接器分为:静态链接器和动态链接器两种.
静态链接器
静态链接器以一组可重定位目标文件和命令行参数作为输入,生成一个完全链接的可以加载和运行的可执行目标文件作为输出.
静态链接器主要完成两个任务:
1>符号解析:目标文件定义和引用符号.符号解析的目的在于将每个符号引用和一个符号定义联系起来.
2>重定位:编译器和汇编器生成从地址零开始的代码和数据节.链接器通过把每个符号定义和一个存储器位置联系起来,然后修改所有对这些符号的引用,使得他们执行这个存储位置,从而重定位这些节.
目标文件:
目标文件有三种形式:
1>可重定位的目标文件:
包含二进制代码和数据,其形式可以再编译时与其他可定位目标文件合并起来,创建一个可执行目标文件.
2>可执行目标文件:
包含二进制代码和数据,其形式可以被直接拷贝到存储器并执行.
3>共享目标文件:
一种特殊的可重定位目标文件,可以再加载或运行时,被动态地夹在到存储器并执行.
编译器和汇编器生成可重定位目标文件(包括共享目标文件),链接器生成可执行目标文件.
可重定位目标文件:
EF头L以一个16字节的序列开始,这个序列描述了字的大小和生成该文件的系统字节顺序.ELF头剩下的部分包含帮助链接器解析和解释目标文件的信息.其中包括ELF头的大小,目标文件的类型(比如,可重定位,可执行,共享目标文件),机器类型,节头部表的文件偏移,以及节头部表中的表目大小和数量.不同节的位置和大小是节头部表描述的,其中目标文件中的每个节都有一个固定大小的表目.ELF格式的可重定位目标文件结构如下图:
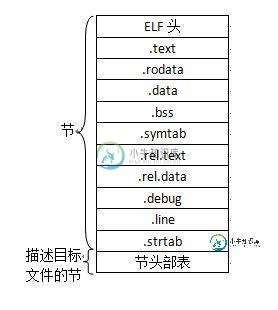
.text:已编译程序的机器代码
.rodata:只读数据
.data:已初始化的全局C变量
.bss:未初始化的全局C变量.在目标文件中这个节不占实际空间,仅是一个占位符.
.sysmtab:一个符号表,存放在程序中被定义和引用的函数和全局变量的信息.
.rel.text:当链接器把这个目标文件和其他文件结合时,.text节中的许多位置都需要修改.一般而言,任何调用外部函数或者引用全局变量的指令都要修改.另一个方面,调用本地函数的指令则不需要修改.
.rel.data:被模块定义或引用的任何全局变量的信息.
.debug:一个调试符号表
.line:原始C源程序中的行号和.text节中机器指令之间的映射.
.strtab:一个字符串表,其中内容包括.symtab和.debug节中的符号表,以及节头部中的节名字.
符号和符号表
每个可重定位目标模块m都有一个符号表,它包含m所定义和引用的符号的信息.在链接器上下文中,有三种不同的符号:
1>由m定义并能被其他模块引用的全局符号.全局链接器符号对应于非静态的C函数以及被定义为不带C的static属性的全局变量.
2>由其他模块定义并被模块m引用的全局符号.这些符号成为外部符号,对应于定义在其他模块中的C函数和变量.
3>只被模块m定义和引用的本地符号.有的本地符号链接器符号对应于带static属性的C函数和全局变量.这些符号在模块m中的任何地方都可见,但是不能被其他模块引用.目标文件中对应于模块m的节和相应的源文件的名字也能获得本地符号.
符号表式有汇编器构造的,使用编译器输出到汇编语言.s文件中的符号.sysmab节中包含ELF符号表.这张符号表包含一个关于表目的数组.表目的格式如下:
typedef struct{
int name; //string table offset
int value; //section offset, or VM address
int size; //object size in bytes
char type:4, //data, func, section, or src file
binding:4; //local or global
char reserved; //unused
char section; //section header index, ABS, UNDEF, or COMMON
}Elf_Symbol;
符号解析
链接器解析符号引用的方法是将每个引用和它输入的可重定位目标文件按的符号表中的一个确定的符号定义联系起来.
对于那些和引用定义在相同模块的本地符号的引用,符号解析式非常简单明了的.编译器只允许每个模块中的每个本地符号只有一个定义.编译器还确保静态本地变量,它们会有本地链接器符号,拥有唯一的名字.
对于全局符号的引用解析,当编译器遇到一个不是在当前模块中定义的符号(变量或函数名)时,它会假设该符号式在其他某个模块中定义的,生成一个链接器符号表表目,并把它交给链接器处理.如果链接器在它的任何输入模块中都找不到这个被引用的符号,它就输出一条错误信息并终止.
在编译时,编译器输出的每个全局符号给汇编器,或者是强,或者是弱,而汇编器把这个信息隐含地编码在可重定位目标文件的符号表中.函数和以初始化的全局变量是强符号,未初始化的全局变量是弱符号.
根据符号的强弱,有如下规则:
1>不允许有多个强符号
2>如果有一个强符号和多个弱符号,则选择强符号
3>如果有多个弱符号,则任选一个弱符号
与静态库链接
所有编译系统都提供一种机制,将所有相关的目标模块打包为一个单独的文件,称为静态库,它可以用做链接器的输入.当链接器构造一个输出的可执行文件时,它只拷贝静态库里被应用程序引用的目标模块.
在unix系统中,静态库以一种称为存档的特殊文件格式存放在磁盘中.存档文件是一组连接起来的可重定位目标文件的集合,有一个头部描述每个成员目标文件的大小和位置.
链接器如何使用静态库来解析引用
在符号解析阶段,链接器从左到右按照它们在编译驱动程序命令行上出现的相同顺序来扫描可重定位目标文件和存档文件.在这次扫描中,链接器位置一个可重定位目标文件集合E,这个集合中的文件会被合并起来形成可执行文件,和一个未解析的符号集合U,以及一个在前面输入文件中已定义的符号结合D.初始时,E,U,D都是空的.
1>对于命令行上的每个输入文件f,链接器会判断f是一个目标文件还是一个存档文件.如果是一个目标文件,那么链接器把f添加到E,修改U和D来反映f中的符号定义和引用,并继续下一个输入文件.
2>如果f是一个存档文件,那么链接器就尝试匹配U中未解析的符号由存档文件成员定义的符号.如果某个存档文件成员m,定义了一个符号来解析U中的一个引用,那么就将m加到E中,并且链接器修改U和D来反映m中的符号定义和引用.对存档文件中的所有成员目标文件都反复进行这个过程,知道U和D都不再发生变化.在此时,任何不包含在E中的成员目标文件都会被丢弃,而链接器将继续到下一个输入文件.
3>如果当链接器完成对输入命令行的扫描后,U是非空的,那么链接器就会输出一个错误并终止.否则,它会合并重定位E中的目标文件,从而构建输出的可执行文件.
这种方式,导致了在输入命令时要考虑到,静态库和目标文件的位置,库文件放在目标文件的后面,如果库文件之间有引用关系,则被引用的库放在后面.
重定位
当链接器完成了符号解析这一步时,它就把代码中的每个符号引用和确定的一个符号定义(也就是,它的一个输入目标模块中的一个符号表表目)联系起来.此时,链接器就知道它的输入目标模块中的代码节和数据解的确切大小.然后就开始重定位步骤.重定位由两步组成:
1>重定位节和符号定义:
在这一步中,链接器将所有相同类型的节合并为一个新的聚合节.然后,链接器将运行时存储器地址赋值给新的聚合节,赋给输入模块定义的每个节,以及赋给输入模块定义的每个符号.当这一步完成时,程序中的每个指令和全局变量都一个唯一的运行时存储器地址.
2>重定位节中的符号引用:
在这一步中,链接器修改代码节和数据节中对每个符号的引用,使得它们指向正确的运行时地址.为了执行这一步,链接器依赖于称为重定位表目的可重定位目标模块中的数据结构.
重定位表目:
当汇编器生成一个目标模块时,它并不知道数据和代码最终将存放在存储器中的什么位置.它也不知道这个模块引用的任何外部定义的函数或者全局变量的位置.所以,无论何时汇编器遇到对最终位置未知的目标引用,它就会生成一个重定位表目,告诉链接器在将目标文件合并为可执行文件时,如何修改这个引用.代码的重定位表目放在.rel.text中.已初始化数据的重定位表目放在rel.data中.
ELF重定位表目的格式如下:
typedef struct{
int offset; //offset of the reference to relocate
int symbol:24, //symbol the reference point to
type:8; //relocation type
} Elf32_Rel;
ELF定义了11中不同的重定位类型,其中最基本的两种重定位类型是:R_386_PC32(重定位一个使用32PC相关的地址引用)和R_386_32(重定位一个使用32位绝对地址的引用).
动态链接器
共享库是一个目标模块,在运行时,可以加载到任意的存储器地址,并在存储器中和一个程序链接起来.这个过程称为动态链接,是由动态链接器完成的.
共享库的共享在两个方面有所不同.首先,在任何给定的文件系统中,对于一个库只有一个.so文件.所有引用该库德可执行目标文件共享这个.so文件中的代码和数据,而不是像静态库德内容那样被拷贝和嵌入到引用它们的可执行的文件中.其次,在存储器中,一个共享库的.text节只有一个副本可以被不同的正在运行的进程共享.
多目标文件的链接
stack.c
#include <stdio.h>
#define STACKSIZE 1000
typedef struct stack {
int data[STACKSIZE];
int top;
} stack;
stack s;
int count = 0;
void pushStack(int d)
{
s.data[s.top ++] = d;
count ++;
}
int popStack()
{
return s.data[-- s.top];
}
int isEmpty()
{
return s.top == 0;
}
link.c
#include <stdio.h>
int a, b;
int main()
{
a = b = 1;
pushStack(a);
pushStack(b);
pushStack(a);
while (! isEmpty()) {
printf("%d\n", popStack());
}
return 0;
}
编译方式:
gcc -Wall stack.c link.c -o main
提示出错信息如下:

但是代码是可以执行的
定义和声明
static和extern修饰函数
上述编译出现错误的原因是:编译器在处理函数调用代码时没有找到函数原型,只好根据函数调用代码做隐式声明,把这三个函数声明为:
int pushStack(int); int popStack(void); int isEmpty(void);
编译器往往不知道去哪里找函数定义,像上面的例子,我让编译器编译main.c,而这几个函数定义却在stack.c里,编译器无法知道,因此可以用extern声明。修改link.c如下:
#include <stdio.h>
int a, b;
extern void pushStack(int d);
extern int popStack(void);
extern int isEmpty(void);
int main()
{
a = b = 1;
pushStack(a);
pushStack(b);
pushStack(a);
while (! isEmpty()) {
printf("%d\n", popStack());
}
return 0;
}
这样编译器就不会报警了。这里extern关键字表示这个标识符具有External Linkage.pushStack这个标识符具有External Linkage指的是:如果link.c和stack.c链接在一起,如果pushStack在link.c和stack.c中都声明(在stack.c中的声明同时也是定义),那么这些声明指的是同一个函数,链接后是同一个GLOBAL符号,代表同一个地址。函数声明中的extern可以省略不写,不屑extern的函数声明也表示这个函数具有External Linkage。
如果用static关键字修饰一个函数声明,则表示该标识符具有Internal Linkage,例如有以下两个程序文件:
/* foo.c */
static void foo(void) {}
/*main.c*/
void foo(void);
int main(void) { foo(); return 0;}
编译链接在一起会出错,原因是:
虽然在foo.c中定义了函数foo,但是这个函数是static属性,只具有internal Linkage。如果把foo.c编译成目标文件,函数名foo在其中是一个LOCAL的符号,不参与链接过程,所以在链接时,main.c中用到一个External Linkage的foo函数,链接器却找不到它的定义在哪,无法确定它的地址,也就无法做符号解析,只好报错。
凡是被多次声明的变量或函数,必须有且只有一个声明是定义,如果有多个定义,或者一个定义都没有,链接器就无法完成链接
static和extern修饰变量
如果我想在link.c中访问stack.c中定义的int变量count,则可以用extern声明
#include <stdio.h> int a, b; extern void pushStack(int d); extern int popStack(void); extern int isEmpty(void); extern int count; int main() { a = b = 1; pushStack(a); pushStack(b); pushStack(a); printf("%d\n", count); while (! isEmpty()) { printf("%d\n", popStack()); } return 0; }
变量count具有external linkage,它的存储空间是在stack.c中分配的,所以link.c中的变量声明extern int count;不是变量定义,因为它不分配存储空间。
如果不想在stack.c外让外界访问到count,则可以用static关键字将count声明为Internal Linkage
区别
变量生命和函数声明有一点不同,函数声明的extern可写可不写,而变量声明如果不写extern,意思就完全变了。如果上面的例子不写extern就表示在main函数中定义一个全局变量count。
用static关键字声明具有Internal Linkage的函数和关键字是处于保护内部状态的目的,也是一种封装(Encapsulation)的思想。一个模块中,有些函数是提供给外界使用的,也称为导出(Export)给外界使用,这些函数用extern声明为External Linkage的。
头文件
为了防止每次函数extern声明,例如又有一个foo.c也使用pushStack等函数,又需要在foo.c中写多个extern声明,为了避免这种重复麻烦的操作,可以自己定义一个stack.h头文件:
#ifndef STACK_H
#define STACK_H
#define STACKSIZE 1000
typedef struct stack {
int data[STACKSIZE];
int top;
} stack;
extern void pushStack(int d);
extern int popStack(void);
extern int isEmpty(void);
#endif
这样,在link.c里就只需要包含这个头文件就可以了,而不需要写三个函数声明了:
#include <stdio.h>
#include "stack.h"
int a, b;
extern int count;
int main()
{
a = b = 1;
pushStack(a);
pushStack(b);
pushStack(a);
printf("%d\n", count);
while (! isEmpty()) {
printf("%d\n", popStack());
}
return 0;
}
为什么#include <stdio.h>用角括号,而#include "stack.h"用引号?原因:
- 对于用角括号包含的头文件,gcc首先查找-I选项指定的目录,然后查找系统的头文件目录(通常是/usr/include)
- 对于用“”包含的头文件,gcc首先查找包含头文件的.c文件所在的目录,然后查找-I选项指定的目录,然后查找系统的头文件目录
用#ifndef #define #endif是为了防止头文件的重复包含,头文件重复包含的问题如下:
- 使预处理的速度变慢了,要处理很多本来不需要处理的头文件
- 如果a.h包含了b.h,然后b.h又包含了a.h的情况,预处理就陷入死循环了
- 头文件按有些代码不允许重复出现
头文件中的变量和函数声明一定不能是定义。如果头文件中出现变量或函数定义,这个头文件又被多个.c文件包含,那么这些.c文件就不能链接在一起
-
C语言是一门面向过程的、抽象化的通用程序设计语言,广泛应用于底层开发。C语言能以简易的方式编译、处理低级存储器。C语言是仅产生少量的机器语言以及不需要任何运行环境支持便能运行的高效率程序设计语言。
-
问题内容: 我之前曾问过一个问题,有关将哪种语言用于AI原型。共识似乎是,如果我希望它速度很快,就需要使用Java或C ++之类的语言,但是Python / Perl / Ruby对于接口位将是不错的选择。 因此,这引出了另一个问题。将这些语言链接在一起有多么容易?哪种组合最有效?因此,如果我想拥有一个调用C ++或Java AI函数的Ruby CGI类型程序,那么容易吗?我在哪里寻求有关做这类事
-
主要内容:安装C-Free 5.0,运行C语言代码安装C-Free 5.0 C-Free 是一款国产的Windows下的C/ C++ IDE,最新版本是 5.0,整个软件才 14M,非常轻巧,安装简单。 下载地址: C-Free 5.0下载 按照教程中的说明安装并 C-Free 5.0。 需要注意的是:C-Free 5.0 在 XP、Win7 下能够完美运行,在 Win8、Win10 下可能会存在兼容性问题,读者可以先尝试安装,不行的话再使用
-
主要内容:1) 新建源文件,2) 生成可执行程序,4) 总结前面我们给出了一段完整的C语言代码,就是在显示器上输出“小牛知识库”,如下所示: 本节我们就来看看如何通过 Dev C++ 来运行这段代码。 Dev C++ 支持单个源文件的编译,如果你的程序只有一个源文件(初学者基本都是在单个源文件下编写代码),那么不用创建项目,直接运行就可以;如果有多个源文件,才需要创建项目。 1) 新建源文件 打开 Dev C++,在上方菜单栏中选择“文件 --> 新建 -
-
问题内容: 我知道供应商有自己的原始SQL语言子集,这些子集用C(类似于Postgre SQL)或MS-SQL Server(C ++)等编写。 那么,原始的SQL是用C编写的,还是在Assembly中创建的呢?我真的找不到关于其原始语言根源的明确答案(除了历史等) 问题答案: 在Oracle上进行的快速历史搜索得出: 在70年代后期,Ingres刚开始在加州大学伯克利分校工作时,三个从事CIA合
-
《汇编语言》(Assembly Language)是计算机专业中一门重要的基础课程,是一种面向机器的低级语言。它依赖于硬件,能通过巧妙的程序设计充分发挥硬件的潜力。汇编语言程序产生的代码运行效率高。因此,到目前为止,许多软件系统(例如操作系统等)的核心部分仍然用汇编语言来编写。