
javascript的document.referrer浏览器支持、失效情况总结

在流量统计服务中都有Traffic source这个功能。Traffic source是针对访次级别的概念,换句话说,当访次建立的时候,landing page的流量来源即是该访次的Traffic source。虽然Traffic source有很多种,不过不幸的是依据现在JS,获得Traffic source的途径只有两种——document.referrer、window.opener.更不幸的是,window.opener适用的场景不多,而document.referrer非常的弱,以至于很多场景下无法准确判断出流量来源。
document.referrer的覆盖
从使用意义上来说document.referrer希望能够追踪到的是浏览器端行为。如果一张页面A被打开,那么浏览器端可能会发生的动作有用户操作、JS代码两种。
先来看看用户打开页面A可能会进行的操作:
| 1 | 直接在地址栏中输入A的地址 |
| 2 | 从B页面左击link A,跳转至A页面 |
| 3 | 从B页面右击link A,在新窗口中打开 |
| 4 | 从B页面右击link A,在新标签页中打开 |
| 5 | 拖动link A至地址栏 |
| 6 | 拖动link A至标签栏 |
| 7 | 使用浏览器的前进、后退按钮 |
注意这里的link即指<A>标签,但是如果有事件或者target还要另当别论。
JS打开页面可能的方式:
| 1 |
修改window.location |
| 2 |
使用window.open |
| 3 |
点击flash |
上面列出了客户端打开页面的一些方法,此外,如果通过服务端的重定向技术,也能够使得页面A呈现给访客。
下面来针对具体的浏览器测试,如果是上述的这些情况,document.referrer表现如何:
| 序号 | 场景 |
IE8.0 | FF3.6 | FF4.0 | chrome |
| 1 | 直接在地址栏中输入A的地址 | " " |
" " |
" " | " " |
| 2 | 从B页面左击link A,A页面替换B页面(target='_self') | √ | √ | √ | √ |
| 3 | 从B页面左击link A,A在新窗口中打开(target='_blank') | √ | √ | √ | √ |
| 3 | 从B页面右击link A,在新窗口中打开 | √ | √ | √ | " " |
| 4 | 从B页面右击link A,在新标签页中打开 | √ | √ | √ | " " |
| 5 | 鼠标拖动link A至地址栏 | / | " " | " " | " " |
| 6 | 鼠标拖动link A至标签栏 | " " | " " | " " | " " |
| 7 | 使用浏览器的前进、后退按钮 | 保持 | 保持 | 保持 | 保持 |
| 8 | 修改window.location打开A页面(同域) | " " | √ | √ | √ |
| 9 | 使用window.open打开A页面 | " " | √ | √ | √ |
| 10 | 点击flash打开A页面 | ||||
| 11 | 服务器重定向至A页面 | " " | " " | " " | " " |
其中," "表示一个空的字符串,√表示能够正确判断来源页,保持则意味使用前进后退不会改变页面的referrer。从这张表里可以看出document.referrer能覆盖大约一半的case。但是对于一些比较常用的操作,例如利用鼠标拖动link至标签栏、前进后退等情况还不能做出正确的处理。
document.referrer的来源
浏览器在向server请求页面A的时候,会发送HTTP请求。这个请求的Header里会带上Referer属性,server接收到该请求后,可以提取出Header里的Referer,用于判断访客是从哪个页面发起的请求。
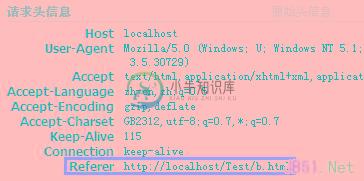
一般情况下浏览器请求A时发送的Header中Referer是什么,那么拿到A页面后document.referre的值就是什么。上图是一个请求A页面的Header,A的document.referre为http://localhost/Test/b.html。
如果在Header中不包含Referre,那么用document.referre去取的时候,就会被赋值为空字符串。
关于HTTPS请求
如果在一张普通的HTTP页面上点击了HTTPS的链接,那么在https请求头部可以附上Referer信息,之后在HTTPS页面中依然可以用document.referre来获得普通的http页面。
同样,如果是在一张https页面上点击了另一个HTTPS的链接,可以在请求的头部附上Referer信息。
但是如果是从一张https页面点击了http链接,那么很不幸,发送的http请求头里无法包含关于https页面的信息,这可能是出于一种对https页面的保护措施。
伪造Referer信息
根据上文的描述,document.referre源自于Header中的Referer。那么如果想修改document.referre的值,理论上讲,仅需要修改请求Header。可以将Header中现有的Referer替换成自己想要的值,如果原来没有也可以添加Referer。
在客户端,篡改Header是一件非常容易的事情。在一个页面的http请求发出去之前,可以利用截包工具将其拦截,然后分析出头部信息,并且修改Referre。
搜了一下,对于FireFox可以使用RefControl插件方便的进行修改。总之,欺骗Traffic source是轻而易举的事情。
页面强制Refresh
写完不久就发现遗漏了一种页面跳转的方式,即在html中的meta标签里强制指定页面进行refresh。例如在b.html中写入
<meta http-equiv="Refresh" content="5;URL=a.html">
则过5秒后浏览器会自动向server发起a页面请求。
经过测试,在IE8,FF3.6-FF4.0中,均不会带有Referer信息,但是chrome却能够鬼使神差的把b.html作为Referer添加进头部。
-
Docusaurus 允许网站通过 浏览器列表配置(browserslist configuration) 来定义其要支持的所有浏览器。 目的 网站需要在向后兼容性和文件体积之间做平衡。由于旧的浏览器不支持现代的 API 或语法,因此需要更多代码才能实现相同的功能,这会增加网站的加载时间,从而对所有其他用户造成不利的影响。为权衡起见,Docusaurus 打包工具仅支持浏览器列表中所定义的浏览器版
-
把jade编译为一个可供浏览器使用的单文件,只需要简单的执行: $ make jade.js 如果你已经安装了uglifyjs (npm install uglify-js),你可以执行下面的命令它会生成所有的文件。其实每一个正式版本里都帮你做了这事。 $ make jade.min.js 默认情况下,为了方便调试Jade会把模板组织成带有形如 __.lineno = 3 的行号的形式。 在浏览器
-
Next.js 支持 IE11 和所有的现代浏览器使用了@babel/preset-env。为了支持 IE11,Next.js 需要全局添加Promise的 polyfill。有时你的代码或引入的其他 NPM 包的部分功能现代浏览器不支持,则需要用 polyfills 去实现。 ployflls 实现案例为polyfills。
-
AdminLTE 与 Bootstrap 4 支持的浏览器一样。Bootstrap 支持 主流平台和浏览器,稳定版在 Windows 上,我们支持 Internet Explorer 10-11 / Microsoft Edge。更多详细信息,请点击此处。 你可以在 我们的 .browserslistrc 文件 找到支持的浏览器情况及其版本: # https://github.com/browse
-
本文向大家介绍c++迭代器失效的情况汇总,包括了c++迭代器失效的情况汇总的使用技巧和注意事项,需要的朋友参考一下 一、序列式容器(数组式容器) 对于序列式容器(如vector,deque),序列式容器就是数组式容器,删除当前的iterator会使后面所有元素的iterator都失效。这是因为vetor,deque使用了连续分配的内存,删除一个元素导致后面所有的元素会向前移动一个位置。所以不能使用
-
主要内容:HTML5 浏览器支持,将 HTML5 元素定义为块元素,实例,为 HTML 添加新元素,实例,Internet Explorer 浏览器问题,完美的 Shiv 解决方案,实例你可以让一些较早的浏览器(不支持HTML5)支持 HTML5。 HTML5 浏览器支持 现代的浏览器都支持 HTML5。 此外,所有浏览器,包括旧的和最新的,对无法识别的元素会作为内联元素自动处理。 正因为如此,你可以 "教会" 浏览器处理 "未知" 的 HTML 元素。 甚至你可以教会 IE6 (Windows