
将字典转换为DataFrame并进行频次统计的方法

首先将一个字典转化为DataFrame,然后以DataFrame中的列进行频次统计。
代码如下:
import pandas as pd
a={'one':['A','A','B','C','C','A','B','B','A','A'],
'tao':['B','B','C','C','A','A','C','B','C','A'],
'three':['C','B','A','A','B','B','B','A','C','D']}
b=pd.DataFrame(a)
b.describe()
b是转换后DataFrame,显示如表格:

one tao three 0 A B C 1 A B B 2 B C A 3 C C A 4 C A B 5 A A B 6 B C B 7 B B A 8 A C C 9 A A D
频次统计如表格:
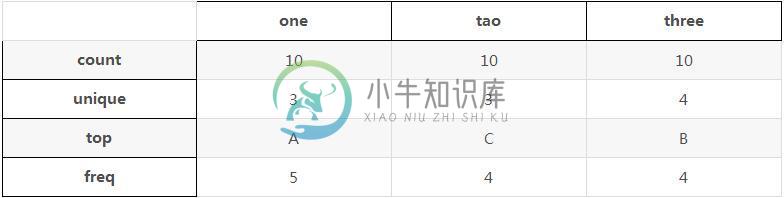
one tao three count 10 10 10 unique 3 3 4 top A C B freq 5 4 4
其中count是总共变量数量,unique是每列有几个变量,top是频次最高的那个变量,freq是频次最高变量出现的频次。
以上这篇将字典转换为DataFrame并进行频次统计的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持小牛知识库。
-
问题内容: 我有一个包含四列的。我想将此DataFrame转换为python字典。我希望第一列的元素为,同一行中其他列的元素为。 数据框: 输出应如下所示: 字典: 问题答案: 该方法将列名设置为字典键,因此你需要稍微调整DataFrame的形状。将“ ID”列设置为索引,然后转置是实现此目的的一种方法。 还接受一个“东方”参数,你需要该参数才能为每列输出值列表。否则,将为每一列返回形式的字典。
-
问题内容: 我有这样的词典列表: 我想把它变成这样的大熊猫: 注意:列的顺序无关紧要。 如何将字典列表转换为如上所述的? 问题答案: 假设d你的字典列表很简单:
-
本文向大家介绍Python-将嵌套字典列表转换为Pandas Dataframe,包括了Python-将嵌套字典列表转换为Pandas Dataframe的使用技巧和注意事项,需要的朋友参考一下 python很多时候会从各种来源接收数据,这些数据可以采用不同的格式,例如csv,JSON等,可以转换为python列表或字典等。但是要使用诸如pandas之类的包应用计算或分析,我们需要将此数据转换为一
-
问题内容: 将列表/元组转换为dict的最佳方法是什么,其中键是列表的不同值,而值是这些不同值的频率? 换一种说法: (我不得不多次执行上述操作,标准库中是否有适合您的内容?) 编辑: Jacob Gabrielson指出2.7 / 3.1分支的标准库中有一些内容 问题答案: 有点儿 通常效果很好。
-
问题内容: 我无法访问JSON中的数据。我究竟做错了什么? 问题答案: 将字典转换为对象,而不是对象!因此,您必须使用方法将其加载到 请参阅作为保存方法和检索方法。 这是代码示例,可以帮助您进一步了解它:
-
我无法访问JSON中的数据。我做错了什么?