
MongoDB游标超时问题的4种解决方法

当我们使用Python从MongoDB里面读取数据时,可能会这样写代码:
import pymongo handler = pymongo.MongoClient().db.col for row in handler.find(): parse_data(row)
短短4行代码,读取MongoDB里面的每一行数据,然后传入parse_data做处理。处理完成以后再读取下一行。逻辑清晰而简单,能有什么问题?只要parse_data(row)不报错,这一段代码就完美无缺。
但事实并非这样。
你的代码可能会在for row in handler.find()这一行报错。它的原因,说来话长。
要解释这个问题,我们首先就需要知道,handler.find()返回的并不是数据库里面的数据,而是一个游标(cursor)对象。如下图所示:
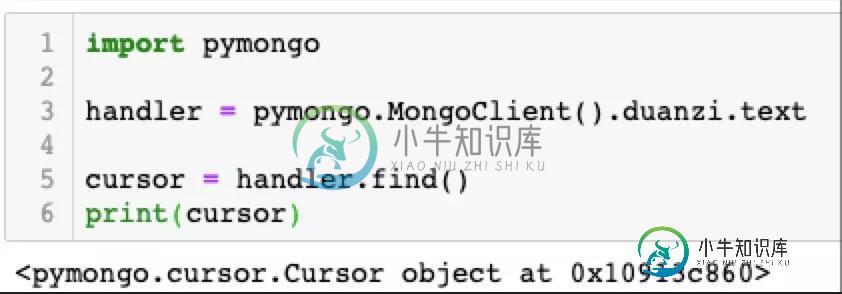
只有当你使用for循环开始迭代它的时候,游标才会真正去数据库里面读取数据。
但是,如果每一次循环都连接数据库,那么网络连接会浪费大量时间。
所以pymongo会一次性获取100行,for row in handler.find()循环第一次的时候,它会连上MongoDB,读取一百条数据,缓存到内存中。于是第2-100次循环,数据都是直接从内存里面获取,不会再连接数据库。
当循环进行到底101次的时候,再一次连接数据库,再读取第101-200行内容……
这个逻辑非常有效地降低了网络I/O耗时。
但是,MongoDB默认游标的超时时间是10分钟。10分钟之内,必需再次连接MongoDB读取内容刷新游标时间,否则,就会导
致游标超时报错:
pymongo.errors.CursorNotFound: cursor id 211526444773 not found
如下图所示:

所以,回到最开始的代码中来,如果parse_data每次执行的时间超过6秒钟,那么它执行100次的时间就会超过10分钟。此时,当程序想读取第101行数据的时候,程序就会报错。
为了解决这个问题,我们有4种办法:
- 修改MongoDB的配置,延长游标超时时间,并重启MongoDB。由于生产环境的MongoDB不能随便重启,所以这个方案虽然有用,但是排除。
- 一次性把数据全部读取下来,再做处理:
all_data = [row for row in handler.find()] for row in all_data: parse(row)
这种方案的弊端也很明显,如果数据量非常大,你不一定能全部放到内存里面。即使能够全部放到内存中,但是列表推导式遍历了所有数据,紧接着for循环又遍历一次,浪费时间。
3.让游标每次返回的数据小于100条,这样消费完这一批数据的时间就会小于10分钟:
# 每次连接数据库,只返回50行数据 for row in handler.find().batch_size(50): parse_data(row)
但这种方案会增加数据库的连接次数,从而增加I/O耗时。
4.让游标永不超时。通过设定参数no_cursor_timeout=True,让游标永不超时:
cursor = handler.find(no_cursor_timeout=True) for row in cursor: parse_data(row) cursor.close() # 一定要手动关闭游标
然而这个操作非常危险,因为如果你的Python程序因为某种原因意外停止了,这个游标就再也无法关闭了!除非重启MongoDB,否则这些游标会一直留在MongoDB上,占用资源。
当然可能有人会说,使用try...except把读取数据的地方包住,只要抛出了异常,在处理异常的时候关闭游标即可:
cursor = handler.find(no_cursor_timeout=True) try: for row in cursor: parse_data(row) except Exception: parse_exception() finally: cursor.close() # 一定要手动关闭游标
其中finally里面的代码,无论有没有异常,都会执行。
但这样写会让代码非常难看。为了解决这个问题,我们可以使用游标的上下文管理器:
with handler.find(no_cursor_timeout=True) as cursor: for row in cursor: parse_data(row)
只要程序退出了with的缩进,游标自动就会关闭。如果程序中途报错,游标也会关闭。
它的原理可以用下面两段代码来解释:
class Test:
def __init__(self):
self.x = 1
def echo(self):
print(self.x)
def __enter__(self):
print('进入上下文')
return self
def __exit__(self, *args):
print('退出上下文')
with Test() as t:
t.echo()
print('退出缩进')
运行效果如下图所示:

接下来在with的缩进里面人为制造异常:
class Test:
def __init__(self):
self.x = 1
def echo(self):
print(self.x)
def __enter__(self):
print('进入上下文')
return self
def __exit__(self, *args):
print('退出上下文')
with Test() as t:
t.echo()
1 + 'a' # 这里一定会报错
print('退出缩进')
运行效果如下图所示:

无论在with的缩进里面发生了什么,Test这个类中的__exit__里面的代码始终都会运行。
我们来看看pymongo的游标对象里面,__exit__是怎么写的,如下图所示:

可以看到,这里正是关闭游标的操作。
因此,如果我们使用上下文管理器,就可以放心大胆地使用no_cursor_timeout=True参数了。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对小牛知识库的支持。
-
问题内容: 在VB6中填充ADO记录集时遇到问题。当我使用SSMS运行查询时,查询(命中SQLServer 2008)只需要大约1秒钟即可运行。当结果集很小时,它可以很好地工作,但是当结果集变成几百个记录时,则需要花费很长时间。800条以上的记录需要大约5分钟的时间才能返回(在SSMS中查询仍然只需要1秒的时间),而6000条以上的记录则需要20分钟以上的时间。我已经通过增加命令超时来“修复”异常
-
本文向大家介绍PHP http请求超时问题解决方案,包括了PHP http请求超时问题解决方案的使用技巧和注意事项,需要的朋友参考一下 一,http请求超时时间 可能出现的场景: 1,curl进程运行了一个世纪还木结束,curl的时候设置了超时时间 --connect-timeout 1000 2,operation timed out after 1000 milliseconds with 0
-
本文向大家介绍Python使用urllib模块的urlopen超时问题解决方法,包括了Python使用urllib模块的urlopen超时问题解决方法的使用技巧和注意事项,需要的朋友参考一下 在新的公司开始上班,今天工作的主题内容是市场部门需要抓取一些论坛用户的邮箱,以便发送营销邮件。 于是用了一个python脚本来执行,前面抓了几个都没有什么问题,后来碰到一个论坛,在执行urlopen的地方总是
-
本文向大家介绍mysql安装时出现各种常见问题的解决方法,包括了mysql安装时出现各种常见问题的解决方法的使用技巧和注意事项,需要的朋友参考一下 小编为大家整理许多mysql安装时出现各种常见问题的解决方法,供大家参考,具体内容如下 问题一: 当各位在安装、重装时出现could not start the service mysql error:0 原因: 卸载mysql时并没有完全删除相关文件
-
本文向大家介绍有关Ajax跨域问题的两种解决方法,包括了有关Ajax跨域问题的两种解决方法的使用技巧和注意事项,需要的朋友参考一下 概述 Ajax跨域是前端开发中常见的问题,本文描述了以Google浏览器Chrome作为客户端和以Tomcat作为Web服务器的情况下的解决办法。 问题现象 当出现跨域访问的时候ajax通常会报类似如下错误: XMLHttpRequest cannot load ht
-
本文向大家介绍C#百万数据查询出现超时问题的解决方法,包括了C#百万数据查询出现超时问题的解决方法的使用技巧和注意事项,需要的朋友参考一下 本文较为详细的讲解了C#百万数据查询出现超时问题的解决方法,分享给大家供大家参考之用。具体方法如下: 很多时候我们用C#从百万数据中筛选一些信息时,经常会出现程序连接超时的错误,常见的错误有很多,例如: Timeout expired. The timeout