
MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。他支持的数据结构非常松散,是类似json的bjson格式,因此可以存储比较复杂的数据类型。Mongo最大的特点是他支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
整体架构:
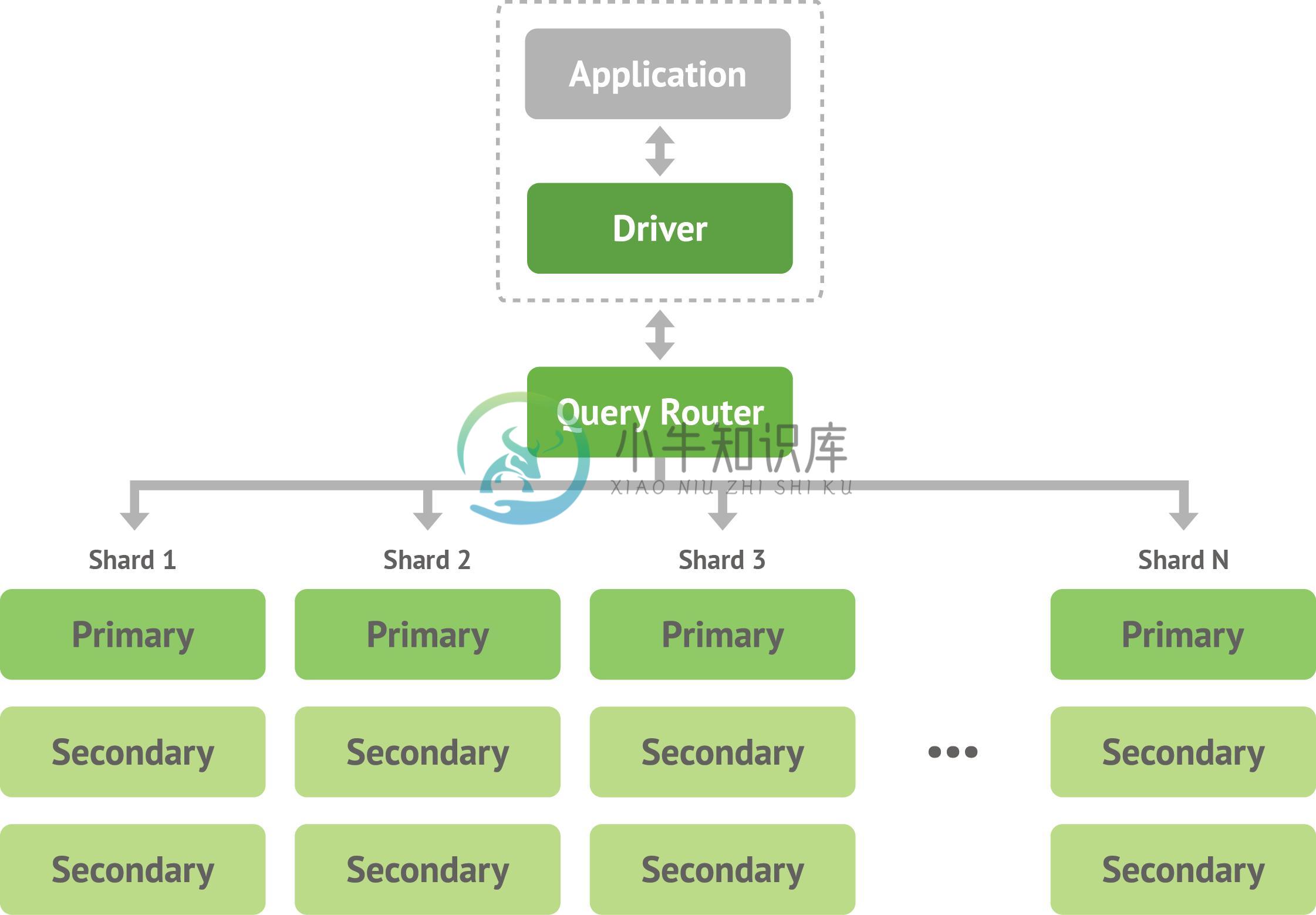
内部架构:
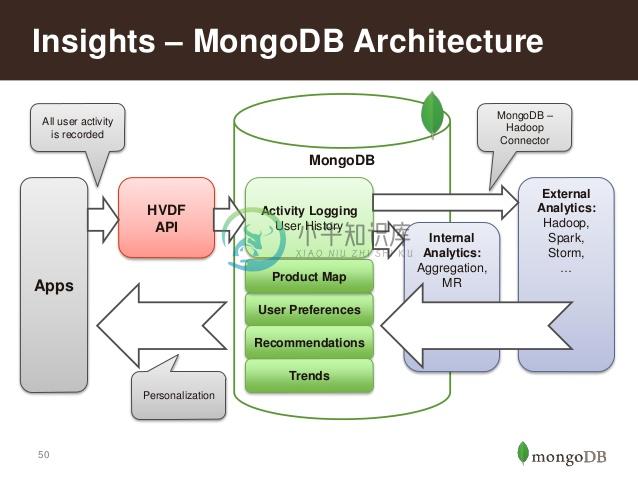
它的特点是高性能、易部署、易使用,存储数据非常方便。主要功能特性有:
-
面向集合存储,易存储对象类型的数据。
-
模式自由。
-
支持动态查询。
-
支持完全索引,包含内部对象。
-
支持查询。
-
支持复制和故障恢复。
-
使用高效的二进制数据存储,包括大型对象(如视频等)。
-
自动处理碎片,以支持云计算层次的扩展性
-
支持RUBY,PYTHON,JAVA,C++,PHP等多种语言。
-
文件存储格式为BSON(一种JSON的扩展)
-
可通过网络访问
所谓"面向集合"(Collenction-Orented),意思是数据被分组存储在数据集中,被称为一个集合(Collenction)。每个 集合在数据库中都有一个唯一的标识名,并且可以包含无限数目的文档。集合的概念类似关系型数据库(RDBMS)里的表(table),不同的是它不需要定义任何模式(schema)。模式自由(schema-free),意味着对于存储在mongodb数据库中的文件,我们不需要知道它的任何结构定义。如果需要的话,你完全可以把不同结构的文件存储在同一个数据库里。存储在集合中的文档,被存储为键-值对的形式。键用于唯一标识一个文档,为字符串类型,而值则可以是各中复杂的文件类型。我们称这种存储形式为BSON(Binary Serialized dOcument Format)。
MongoDB服务端可运行在Linux、Windows或OS X平台,支持32位和64位应用,默认端口为27017。推荐运行在64位平台,因为 MongoDB 在32位模式运行时支持的最大文件尺寸为2GB。
MongoDB把数据存储在文件中(默认路径为:/data/db),为提高效率使用内存映射文件进行管理。
-
MongoDB文档的数据结构和JSON基本一样。 切换数据库,此处使用NoSQL Manager for MongoDB工具作为客户端, 命令 user test 查看所有数据库 show dbs 切换到数据库 runoob: use runoob 执行删除命令: db.dropDatabase() 删除集合 db.collection.drop() 以下实例删除了 runoob 数据库中
-
订阅 Python全栈白宝书-零基础入门篇 可报销!白嫖入口-请点击我。推荐他人订阅,可获取扣除平台费用后的35%收益,文末名片加V! 说明:该文属于 Python全栈白宝书专栏,免费阶段订阅数量4300+,购买任意白宝书体系化专栏可加入TFS-CLUB 私域社区。 福利:加入社区的小伙伴们,除了可以获取博主所有付费专栏的阅读权限之外,还有机会加入 星荐官共赢计划
-
订阅 Python全栈白宝书-零基础入门篇 可报销!白嫖入口-请点击我。推荐他人订阅,可获取扣除平台费用后的35%收益,文末名片加V! 说明:该文属于 Python全栈白宝书专栏,免费阶段订阅数量4300+,购买任意白宝书体系化专栏可加入TFS-CLUB 私域社区。 福利:加入社区的小伙伴们,除了可以获取博主所有付费专栏的阅读权限之外,还有机会加入 星荐官共赢计划
-
基础篇(能解决工作中80%的问题): MongoDB的概述、应用场景、下载方式、连接方式和发展历史等 MongoDB数据类型、重要概念以及shell常用指令 MongoDB文档的各种增加、更新、删除操作总结 MongoDB各种查询操作总结 MongoDB对列的各种操作总结 MongoDB中的索引操作总结 进阶篇: MongoDB聚合操作总结 MongoDB的导入导出、备份恢复总结 MongoDB的
-
CentOS 安装 mongodb 推荐使用 yum 源头安装方式,便于管理 创建 mongodb yum 源头 vim /etc/yum.repos.d/mongodb-org-5.0.repo 编辑刚刚创建的文件,将下面内容写入 [mongodb-org-5.0] name=MongoDB Repository baseurl=https://repo.mongodb.org/yum/red
-
https://www.mongodb.com/docs/upcoming/tutorial/install-mongodb-on-red-hat/ 本人在官方下载了mongodb,安装后发现没有mongod文件。导致无法知道有没有成功。所以翻阅官方文档。特此记录下来。以便后续查阅。 mongodb 安装。 首先创建文件/etc/yum.repos.d/mongodb-org-6.0.repo t
-
基础篇(能解决工作中80%的问题): MongoDB的概述、应用场景、下载方式、连接方式和发展历史等 MongoDB数据类型、重要概念以及shell常用指令 MongoDB文档的各种增加、更新、删除操作总结 MongoDB各种查询操作总结 MongoDB对列的各种操作总结 MongoDB中的索引操作总结 进阶篇: MongoDB聚合操作总结 MongoDB的导入导出、备份恢复总结 MongoDB的
-
一、MongoDB基本操作 1.1、软件环境准备 软件环境: MongoDB Server5.0.9 Navicat15.0.28 RoboMongo 0.9.0 Window10系统 1.2、MongoDB连接 MongoDB连接,使用“username:password@hostname/dbname’”的形式进行连接。 连接本地数据库服务器,端口是默认的。 mongodb://localho
-
一、介绍 HDFS (Hadoop Distributed File System)是 Hadoop 下的分布式文件系统,具有高容错、高吞吐量等特性,可以部署在低成本的硬件上。 二、HDFS 设计原理 2.1 HDFS 架构 HDFS 遵循主/从架构,由单个 NameNode(NN) 和多个 DataNode(DN) 组成: NameNode : 负责执行有关 文件系统命名空间 的操作,例如打开,
-
分布式支持 数据访问层支持分布式数据库,包括读写分离,要启用分布式数据库,需要开启数据库配置文件中的deploy参数: return [ // 启用分布式数据库 'deploy' => 1, // 数据库类型 'type' => 'mysql', // 服务器地址 'hostname' => '192.168.1.1,19
-
简而言之:如果您有大量不同大小的文档,其中相对较少的文档达到最大对象大小,那么在MongoDB中存储这些文档的最佳实践是什么? 我有一套文件,比如: 值列表的长度因文档而异。对于大多数文档,它将有几个元素,对于少数文档,它将有数千万个元素,我将达到MongoDB中的最大对象大小限制。问题是,我为那些非常大(而且相对较少)的文档提出的任何特殊解决方案都可能会对我存储小文档的方式产生影响,否则,这些小
-
我需要使用spring@Cacheable注释缓存对MongoDB的调用: 不幸的是,使用@Cacheable注释接口中的任何方法都会导致以下异常: 我正在寻找一种方法来缓存对DB的调用(这相当昂贵)。有什么想法吗?
-
一面 11.1 分布式存储 阿里天池比赛,问了一些模块的优化 问存储项目 问TinyKV 项目 操作系统:cpu cache,false sharing,gdb C++:移动语义,std::map,rbtree和b+tree区别。 perf 观察程序性能 算法题:二叉树的路径和 二面 11.2 leader 面 开局先选方向:DB,分布式,操作系统,体系结构,计算机网络。选了分布式,狂问raft
-
之前的秋招面经:深信服 Go 开发面经(已 offer) bg:专升本+ACM银牌+三个项目(一个毕设的KV分离LSM-Tree,一个6824的分布式KV,一个OJ) 某小厂,存储方向技术积累还不错,避免定位就不写具体名字了。自己也一直比较憧憬做 infra 吧,不想写 CRUD 业务,所以就投了。面试内容都是事后回忆,可能有遗漏或记错的 一面 50min 自我介绍 项目实现细节、设计考量、优化(
-
我想知道是否有任何机制可以在Spring Data MongoDB存储库中使用带有注释的?我希望能收到我所拥有的文件数量,而不必获取所有文件。 基本上,这在Java中相当于:
-
null 假设我有100张唱片。缓存只能保存40条记录(最常用)和100条记录在磁盘文件(不在任何其他数据库中)。 所以,如果从这100条记录中请求任何东西,我就不必去实际的数据库(例如Sybase db)? 如果在100条记录中找到了密钥,但它不存在于内存缓存中(40条记录),则获取该密钥,放入内存缓存中,并使用驱逐策略将其他密钥交换到磁盘文件中(但在磁盘上,我总是有100条记录) 如果缓存和磁