
mysql sql语句性能调优简单实例

mysql sql语句性能调优简单实例
在做服务器开发时,有时候对并发量有一定的要求,有时候影响速度的是某个sql语句,比如某个存储过程。现在假设服务器代码执行过程中,某个sql执行比较缓慢,那如何进行优化呢?
假如现在服务器代码执行如下sql存储过程特别缓慢:
call sp_wplogin_register(1, 1, 1, '830000', '222222');
可以按如下方法来进行调试:
1. 打开mysql profiling:

2. 然后执行需要调优的sql,我们这里执行两条sql,一条commit语句,另外一条就是调用上面的存储过程语句:
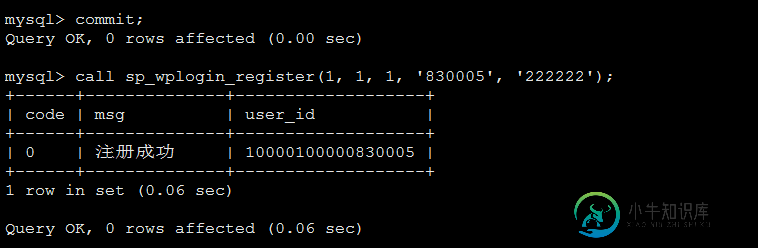
3. 利用profiling来显示每条sql执行的时间,其中存储过程由一系列sql组成,这里也被分解开显示:

可以看到标红处的sql执行速度与其他sql语句远远不是一个量级的。我们对这行进行优化,比如为字段f_phone建立索引。
感谢阅读,希望能帮助到大家,谢谢大家对本站的支持!
-
对于某些工作负载,可以在通过在内存中缓存数据或者打开一些实验选项来提高性能。 在内存中缓存数据 Spark SQL可以通过调用sqlContext.cacheTable("tableName")方法来缓存使用柱状格式的表。然后,Spark将会仅仅浏览需要的列并且自动地压缩数据以减少内存的使用以及垃圾回收的 压力。你可以通过调用sqlContext.uncacheTable("tableName")
-
集群中的Spark Streaming应用程序获得最好的性能需要一些调整。这章将介绍几个参数和配置,提高Spark Streaming应用程序的性能。你需要考虑两件事情: 高效地利用集群资源减少批数据的处理时间 设置正确的批容量(size),使数据的处理速度能够赶上数据的接收速度 减少批数据的执行时间 设置正确的批容量 内存调优
-
常用命令 1. 查看系统 CPU 总数 $ grep -c ^processor /proc/cpuinfo $ lscpu 2. 查看网卡信息,主机名 $ hostname $ ip addr show eth0 3. 查看系统上运行的服务 # systemctl list-units -t service | awk '$3=="active"' ** ** ** **
-
硬件因素 内存(RAM)的读写速度时普通 SSD 的 25 倍。MongoDB 中依赖 RAM 最多的操作包括:聚合、索引遍历、写操作、查询引擎、连接 Table 1. 常见存储的IOPS 类型 IOPS 7200 rpm SATA 75 - 100 15000 rpm SAS 175 - 210 SSD Intel X25-E(SLC) 5000 SSD Intel X25-M G2(MLC)
-
6. 简单语句 简单语句包含在单一的一个逻辑行中。几个简单语句可以用分号分隔出现在单一的一行中。简单语句的语法是: simple_stmt ::= expression_stmt | assert_stmt | assignment_stmt | augmented_assignment_stm
-
每行只应该有一条语句,除非多条语句关联特别紧密。 case FOO: oogle (zork); boogle (zork); break; case BAR: oogle (bork); boogle (zork); break; case BAZ: oogle (gork); boogle (bork); break; for或while循环语句的空