
Pyspark读取parquet数据过程解析

parquet数据:列式存储结构,由Twitter和Cloudera合作开发,相比于行式存储,其特点是:
可以跳过不符合条件的数据,只读取需要的数据,降低IO数据量;压缩编码可以降低磁盘存储空间,使用更高效的压缩编码节约存储空间;只读取需要的列,支持向量运算,能够获取更好的扫描性能。
那么我们怎么在pyspark中读取和使用parquet数据呢?我以local模式,linux下的pycharm执行作说明。
首先,导入库文件和配置环境:
import os from pyspark import SparkContext, SparkConf from pyspark.sql.session import SparkSession os.environ["PYSPARK_PYTHON"]="/usr/bin/python3" #多个python版本时需要指定 conf = SparkConf().setAppName('test_parquet') sc = SparkContext('local', 'test', conf=conf) spark = SparkSession(sc)
然后,使用spark进行读取,得到DataFrame格式的数据:host:port 属于主机和端口号
parquetFile = r"hdfs://host:port/Felix_test/test_data.parquet"
df = spark.read.parquet(parquetFile)
而,DataFrame格式数据有一些方法可以使用,例如:
1.df.first() :显示第一条数据,Row格式
print(df.first())
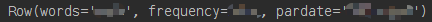
2.df.columns:列名
3.df.count():数据量,数据条数
4.df.toPandas():从spark的DataFrame格式数据转到Pandas数据结构
5.df.show():直接显示表数据;其中df.show(n) 表示只显示前n行信息
6.type(df):显数据示格式

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持小牛知识库。
-
我是火花的新手,我找不到这个...我有许多拼花地板文件上传到的位置: 此文件夹的总大小为,。如何将这些文件分块并读取到一个数据包中,如何将所有这些文件加载到一个数据包中? 错误:
-
本文向大家介绍通过openpyxl读取excel文件过程解析,包括了通过openpyxl读取excel文件过程解析的使用技巧和注意事项,需要的朋友参考一下 这篇文章主要介绍了通过openpyxl读取excel文件过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 1、环境准备 python3环境、安装openpyxl模块 2、excel文件数
-
我有一个桶,里面有几个小的拼花文件,我想把它们合并成一个更大的文件。 要完成此任务,我想创建一个spark作业来消费并写入一个新文件。 知道怎么了吗?
-
pyspark新手,希望将csv文件读取到数据帧。似乎不能让人读。有什么帮助吗? ()中的Py4JJavaError回溯(最近一次调用)----
-
我正在尝试用PySpark从HBase写/读。 环境: null 我的火花提交是: 当我写到HBase时,一切都很好,数据从mydf保存到HBase表中。 当我试图阅读时,它很好,只有在激发行动之前。df.show()-导致错误。
-
在我们的Java应用程序中,我需要从oracle数据库中读取8000万记录。我试图为此重新设计多线程程序。目前,我们使用Java5个线程池,10个线程基于主键模式并行读取数据库。每个线程将读取不同的模式,如001*和002*。 如何提高该计划的性能?我正在考虑设计模式,让引导线程读取数据库并将处理委托给子线程。在我们现有的设计中,不同的线程通过10个jdbc连接访问表。使用新方法,我将只有一个线程