
深入Python解释器理解Python中的字节码

我最近在参与Python字节码相关的工作,想与大家分享一些这方面的经验。更准确的说,我正在参与2.6到2.7版本的CPython解释器字节码的工作。
Python是一门动态语言,在命令行工具下运行时,本质上执行了下面的步骤:
- 当第一次执行到一段代码时,这段代码会被编译(如,作为一个模块加载,或者直接执行)。根据操作系统的不同,这一步生成后缀名是pyc或者pyo的二进制文件。
- 解释器读取二进制文件,并依次执行指令(opcodes)。
Python解释器是基于栈的。要理解数据流向,我们需要知道每条指令的栈效应(如,操作码和参数)。
探索Python二进制文件
得到一个二进制文件字节码的最简单方式,是对CodeType结构进行解码:
import marshal
fd = open('path/to/my.pyc', 'rb')
magic = fd.read(4) # 魔术数,与python版本相关
date = fd.read(4) # 编译日期
code_object = marshal.load(fd)
fd.close()
code_object包含了一个CodeType对象,它代表被加载文件的整个模块。为了查看这个模块的类定义、方法等的所有嵌套编码对象(编码对象,原文为code object),我们需要递归地检查CodeType的常量池。就像下面的代码:
import types def inspect_code_object(co_obj, indent=''): print indent, "%s(lineno:%d)" % (co_obj.co_name, co_obj.co_firstlineno) for c in co_obj.co_consts: if isinstance(c, types.CodeType): inspect_code_object(c, indent + ' ') inspect_code_object(code_object) # 从第一个对象开始
这个案例中,我们打印出一颗编码对象树,每个编码对象是其父对象的子节点。对下面的代码:
class A: def __init__(self): pass def __repr__(self): return 'A()' a = A() print a
我们得到的树形结果是:
<module>(lineno:2) A(lineno:2) __init__(lineno:3) __repr__(lineno:5)
为了测试,我们可以通过compile指令,编译一个包含Python源码的字符串,从而能够得到一个编码对象:
co_obj = compile(python_source_code, '<string>', 'exec')
要获取更多关于编码对象的信息,我们可以查阅Python文档的co_* fields 部分。
初见字节码
一旦我们得到了编码对象,我们就可以开始对它进行拆解了(在co_code字段)。从字节码中解析出它的含义:
- ? 解释操作码的含义
- ? 提取任意参数
dis模块的disassemble函数展示了是如何做到的。对我们前面例子,它输出的结果是:
2 0 LOAD_CONST 0 ('A')
3 LOAD_CONST 3 (())
6 LOAD_CONST 1 (<code object A at 0x42424242, file "<string>", line 2>)
9 MAKE_FUNCTION 0
12 CALL_FUNCTION 0
15 BUILD_CLASS
16 STORE_NAME 0 (A)
8 19 LOAD_NAME 0 (A)
22 CALL_FUNCTION 0
25 STORE_NAME 1 (a)
9 28 LOAD_NAME 1 (a)
31 PRINT_ITEM
32 PRINT_NEWLINE
33 LOAD_CONST 2 (None)
36 RETURN_VALUE
我们得到了:
- 行号(当它改变时)
- 指令的序号
- 当前指令的操作码
- 操作参数(oparg),操作码用它来计算实际的参数。例如,对于LOAD_NAME操作码,操作参数指向tuple co_names的索引。
- 计算后的实际参数(圆括号内)
对于序号为6的指令,操作码LOAD_CONST的操作参数,指向需要从tuple co_consts加载的对象。这里,它指向A的类型定义。同样的,我们能够继续并反编译所有的代码对象,得到模块的全部字节码。
字节码的第一部分(序号0到16),与A的类型定义有关;其他的部分是我们实例化A,并打印它的代码。
有趣的字节码构造
所有的操作码都是相当直接易懂的,但是由于下面的原因,在个别情况下会显得奇怪:
- 编译器优化
- 解释器优化(因此会导致加入额外的操作码)
顺序变量赋值
首先,我们看看顺序地对多个元素赋值,会发生什么:
(1) a, b = 1, '2' (2) a, b = 1, e (3) a, b, c = 1, 2, e (4) a, b, c, d = 1, 2, 3, e
这4中语句,会产生差别相当大的字节码。
第一种情况最简单,因为赋值操作的右值(RHS)只包含常量。这种情况下,CPython会创建一个(1, ‘a') 的t uple,使用UNPACK_SEQUENCE操作码,把两个元素压到栈上,并对变量a和b分别执行STORE_FAST操作:
0 LOAD_CONST 5 ((1, '2')) 3 UNPACK_SEQUENCE 2 6 STORE_FAST 0 (a) 9 STORE_FAST 1 (b)
而第二种情况,则在右值引入了一个变量,因此一般情况下,会调用一条取值指令(这里简单地调用了LOAD_GLOBAL指令)。但是,编译器不需要在栈上为这些值创建一个新的tuple,也不需要调用UNPACK_SEQUENCE(序号18);调用ROT_TWO就足够了,它用来交换栈顶的两个元素(虽然交换指令19和22也可以达到目的)。
12 LOAD_CONST 1 (1) 15 LOAD_GLOBAL 0 (e) 18 ROT_TWO 19 STORE_FAST 0 (a) 22 STORE_FAST 1 (b)
第三种情况变得很奇怪。把表达式放到栈上与前一种情况的处理方式相同,但是在交换栈顶的3个元素后,它再次交换了栈顶的2个元素:
25 LOAD_CONST 1 (1) 28 LOAD_CONST 3 (2) 31 LOAD_GLOBAL 0 (e) 34 ROT_THREE 35 ROT_TWO 36 STORE_FAST 0 (a) 39 STORE_FAST 1 (b) 42 STORE_FAST 2 (c)
最后一种情况是通用的处理方式,ROT_*操作看起来行不通了,编译器创建了一个tuple,然后调用UNPACK_SEQUENCE把元素放到栈上:
45 LOAD_CONST 1 (1) 48 LOAD_CONST 3 (2) 51 LOAD_CONST 4 (3) 54 LOAD_GLOBAL 0 (e) 57 BUILD_TUPLE 4 60 UNPACK_SEQUENCE 4 63 STORE_FAST 0 (a) 66 STORE_FAST 1 (b) 69 STORE_FAST 2 (c) 72 STORE_FAST 3 (d)
函数调用构造
最后一组有趣的例子是关于函数调用构造,以及创建调用的4个操作码。我猜测这些操作码的数量是为了优化解释器代码,因为它不像Java,有invokedynamic,invokeinterface,invokespecial,invokestatic或者invokevirtual之一。
Java中,invokeinterface,invokespecial和invokevirtual都是从静态类型语言中借鉴来的(invokespecial只被用来调用构造函数和父类AFAIK)。Invokestatic是自我描述的(不需要把接收方放在栈上),在Python中没有类似的概念(在解释器层面上,而不是装饰者)。简短的说,Python调用都能被转换成invokedynamic。
在Python中,不同的CALL_*操作码确实不存在,原因是类型系统,静态方法,或者特殊访问构造器的需求。它们都指向了Python中一个函数调用是如何确定的。从语法来看:
调用结构允许代码这些写:
func(arg1, arg2, keyword=SOME_VALUE, *unpack_list, **unpack_dict)
关键字参数允许通过形式参数的名称来传递参数,而不仅仅是通过位置。*符号从一个可迭代的容器中取出所有元素,作为参数传入(逐个元素,不是以tuple的形式),而**符号处理一个包含关键字和值的字典。
这个例子用到了调用构造的几乎所有特性:
? 传递变量参数列表(_VAR):CALL_FUNCTION_VAR, CALL_FUNCTION_VAR_KW
? 传递基于字典的关键字(_KW):CALL_FUNCTION_KW, CALL_FUNCTION_VAR_KW
字节码是这样的:
0 LOAD_NAME 0 (func)
3 LOAD_NAME 1 (arg1)
6 LOAD_NAME 2 (arg2)
9 LOAD_CONST 0 ('keyword')
12 LOAD_NAME 3 (SOME_VALUE)
15 LOAD_NAME 4 (unpack_list)
18 LOAD_NAME 5 (unpack_dict)
21 CALL_FUNCTION_VAR_KW 258
通常,CALL_FUNCTION调用将oparg解析为参数个数。但是,更多的信息被编码。第一个字节(0xff掩码)存储参数的个数,第二个字节((value >> 8) & 0xff)存储传递的关键字参数个数。为了要计算需要从栈顶弹出的元素个数,我们需要这么做:
na = arg & 0xff # num args nk = (arg >> 8) & 0xff # num keywords n_to_pop = na + 2 * nk + CALL_EXTRA_ARG_OFFSET[op]
CALL_EXTRA_ARG_OFFSET包含了一个偏移量,由调用操作码确定(对CALL_FUNCTION_VAR_KW来说,是2)。这里,在访问函数名称前,我们需要弹出6个元素。
对于其他的CALL_*调用,完全依赖于代码是否使用列表或者字典传递参数。只需要简单的组合即可。
构造一个极小的CFG
为了理解代码是如何运行的,我们可以构造一个控制流程图(control-flow graph,CFG),这个过程非常有趣。我们通过它,查看在什么条件下,哪些无条件判断的操作码(基本单元)序列会被执行。
即使字节码是一门真正的小型语言,构造一个运行稳定的CFG需要大量的细节工作,远超出本博客的范围。因此如果需要一个真实的CFG实现,你可以看看这里equip。
在这里,我们只关注没有循环和异常的代码,因此控制流程只依赖与if语句。
只有少数几个操作码能够执行地址跳转(对没有循环和异常的情况);它们是:
JUMP_FORWARD:在字节码中跳转到一个相对位置。参数是跳过的字节数。
JUMP_IF_FALSE_OR_POP,JUMP_IF_TRUE_OR_POP,JUMP_ABSOLUTE,POP_JUMP_IF_FALSE,以及POP_JUMP_IF_TRUE:参数都是字节码中的绝对地址。
为一个函数够造CFG,意味着要创建基本的单元(不包含条件判断的操作码序列——除非有异常发生),并且把它们与条件和分支连在一起,构成一个图。在我们的例子中,我们只有True、False和无条件分支。
让我们来考虑下面的代码示例(在实际中绝对不要这样用):
def factorial(n): if n <= 1: return 1 elif n == 2: return 2 return n * factorial(n - 1)
如前所述,我们得到factorial方法的代码对象:
module_co = compile(python_source, '', 'exec') meth_co = module_co.co_consts[0]
反汇编结果是这样的(<<<后是我的注释):
3 0 LOAD_FAST 0 (n) 3 LOAD_CONST 1 (1) 6 COMPARE_OP 1 (<=) 9 POP_JUMP_IF_FALSE 16 <<< control flow 4 12 LOAD_CONST 1 (1) 15 RETURN_VALUE <<< control flow 5 >> 16 LOAD_FAST 0 (n) 19 LOAD_CONST 2 (2) 22 COMPARE_OP 2 (==) 25 POP_JUMP_IF_FALSE 32 <<< control flow 6 28 LOAD_CONST 2 (2) 31 RETURN_VALUE <<< control flow 7 >> 32 LOAD_FAST 0 (n) 35 LOAD_GLOBAL 0 (factorial) 38 LOAD_FAST 0 (n) 41 LOAD_CONST 1 (1) 44 BINARY_SUBTRACT 45 CALL_FUNCTION 1 48 BINARY_MULTIPLY 49 RETURN_VALUE <<< control flow
在这个字节码中,我们有5条改变CFG结构的指令(添加约束条件,或者允许快速退出):
POP_JUMP_IF_FALSE:跳转到绝对地址16和32;
RETURN_VALUE:从栈顶弹出一个元素,并返回。
提取基本单元很简单,因为我们只关心那些改变控制流程的指令。在我们的例子中,我们没有遇到强制跳转指令,如JUMP_FORWARD或JUMP_ABSOLUTE。
提取这类结构的代码示例:
import opcode
RETURN_VALUE = 83
JUMP_FORWARD, JUMP_ABSOLUTE = 110, 113
FALSE_BRANCH_JUMPS = (111, 114) # JUMP_IF_FALSE_OR_POP, POP_JUMP_IF_FALSE
def find_blocks(meth_co):
blocks = {}
code = meth_co.co_code
finger_start_block = 0
i, length = 0, len(code)
while i < length:
op = ord(code[i])
i += 1
if op == RETURN_VALUE: # We force finishing the block after the return,
# dead code might still exist after though...
blocks[finger_start_block] = {
'length': i - finger_start_block - 1,
'exit': True
}
finger_start_block = i
elif op >= opcode.HAVE_ARGUMENT:
oparg = ord(code[i]) + (ord(code[i+1]) << 8)
i += 2
if op in opcode.hasjabs: # Absolute jump to oparg
blocks[finger_start_block] = {
'length': i - finger_start_block
}
if op == JUMP_ABSOLUTE: # Only uncond absolute jump
blocks[finger_start_block]['conditions'] = {
'uncond': oparg
}
else:
false_index, true_index = (oparg, i) if op in FALSE_BRANCH_JUMPS else (i, oparg)
blocks[finger_start_block]['conditions'] = {
'true': true_index,
'false': false_index
}
finger_start_block = i
elif op in opcode.hasjrel:
# Essentially do the same...
pass
return blocks
我们得到了下面的基本单元:
Block 0: {'length': 12, 'conditions': {'false': 16, 'true': 12}}
Block 12: {'length': 3, 'exit': True}
Block 16: {'length': 12, 'conditions': {'false': 32, 'true': 28}}
Block 28: {'length': 3, 'exit': True}
Block 32: {'length': 17, 'exit': True}
以及单元的当前结构:
Basic blocks start_block_index := length := size of instructions condition := true | false | uncond -> target_index exit* := true
我们得到了控制流程图(除了入口和隐式的退出单元),之后我们可以把它转化成可视化的图形:
def to_dot(blocks):
cache = {}
def get_node_id(idx, buf):
if idx not in cache:
cache[idx] = 'node_%d' % idx
buf.append('%s [label="Block Index %d"];' % (cache[idx], idx))
return cache[idx]
buffer = ['digraph CFG {']
buffer.append('entry [label="CFG Entry"]; ')
buffer.append('exit [label="CFG Implicit Return"]; ')
for block_idx in blocks:
node_id = get_node_id(block_idx, buffer)
if block_idx == 0:
buffer.append('entry -> %s;' % node_id)
if 'conditions' in blocks[block_idx]:
for cond_kind in blocks[block_idx]['conditions']:
target_id = get_node_id(blocks[block_idx]['conditions'][cond_kind], buffer)
buffer.append('%s -> %s [label="%s"];' % (node_id, target_id, cond_kind))
if 'exit' in blocks[block_idx]:
buffer.append('%s -> exit;' % node_id)
buffer.append('}')
return 'n'.join(buffer)
可视化的流程控制图:
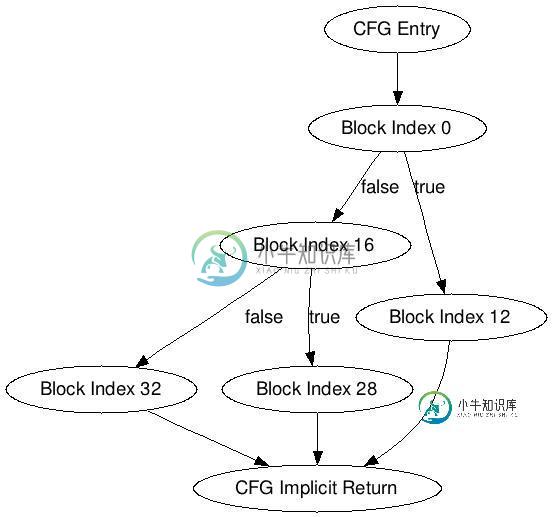
为什么有这篇文章?
需要访问Python字节码的情况确实很少见,但是我已经遇到过几次这种情形了。我希望,这篇文章能够帮助那些开始研究Python逆向工程的人们。
然而现在,我正在研究Python代码,尤其是它的字节码。由于目前在Python中尚不存在这样的工具(并且检测源代码通常会留下非常低效的装饰器检测代码),这就是为什么equip会出现的原因。
-
本文向大家介绍深入理解Python中装饰器的用法,包括了深入理解Python中装饰器的用法的使用技巧和注意事项,需要的朋友参考一下 因为函数或类都是对象,它们也能被四处传递。它们又是可变对象,可以被更改。在函数或类对象创建后但绑定到名字前更改之的行为为装饰(decorator)。 “装饰器”后隐藏了两种意思——一是函数起了装饰作用,例如,执行真正的工作,另一个是依附于装饰器语法的表达式,例如,at
-
本文向大家介绍深入理解Python对Json的解析,包括了深入理解Python对Json的解析的使用技巧和注意事项,需要的朋友参考一下 Json简介 JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式。它基于JavaScript(Standard ECMA-262 3rd Edition - December 1999)的一个子集。 JSON采用完全独立于
-
本文向大家介绍深入理解Python中的元类(metaclass),包括了深入理解Python中的元类(metaclass)的使用技巧和注意事项,需要的朋友参考一下 译注:这是一篇在Stack overflow上很热的帖子。提问者自称已经掌握了有关Python OOP编程中的各种概念,但始终觉得元类(metaclass)难以理解。他知道这肯定和自省有关,但仍然觉得不太明白,希望大家可以给出一些实际的
-
本文向大家介绍深入理解python中的闭包和装饰器,包括了深入理解python中的闭包和装饰器的使用技巧和注意事项,需要的朋友参考一下 python中的闭包从表现形式上定义(解释)为:如果在一个内部函数里,对在外部作用域(但不是在全局作用域)的变量进行引用,那么内部函数就被认为是闭包(closure)。 以下说明主要针对 python2.7,其他版本可能存在差异。 也许直接看定义并不太能明白,下面
-
当我们编写Python代码时,我们得到的是一个包含Python代码的以.py为扩展名的文本文件。要运行代码,就需要Python解释器去执行.py文件。 由于整个Python语言从规范到解释器都是开源的,所以理论上,只要水平够高,任何人都可以编写Python解释器来执行Python代码(当然难度很大)。事实上,确实存在多种Python解释器。 CPython 当我们从Python官方网站下载并安装好
-
当我们编写Python代码时,我们得到的是一个包含Python代码的以.py为扩展名的文本文件。要运行代码,就需要Python解释器去执行.py文件。 由于整个Python语言从规范到解释器都是开源的,所以理论上,只要水平够高,任何人都可以编写Python解释器来执行Python代码(当然难度很大)。事实上,确实存在多种Python解释器。 CPython 当我们从Python官方网站下载并安装好