
python函数调用,循环,列表复制实例

我就废话不多说了,大家还是直接看代码吧!
year=int(raw_input('year:\n'))
month=int(raw_input('month:\n'))
day=int(raw_input('day:\n'))
sum=0
months=(0,31,59,90,120,151,181,212,243,273,304,334)
if 0<month<=12:
sum=months[month-1]
else:
print 'data error!'
sum+=day
leap=0
if(year%400==0)or((year%4==0)and(year%100!=0)):
leap=1
if(leap==1)and(month>2):
sum+=1
print 'it is the %dth day.' %sum
list.sort()从小到大排列
求斐波那契数列
F0 = 0 (n=0) F1 = 1 (n=1) Fn = F[n-1]+ F[n-2](n=>2)
def fib(n): a,b=1,1 for i in range(n-1): a,b=b,a+b return a print fib(10)
输出第10 位 用循环来实现
def fib(n): if n==1 or n==2: return 1 return fib(n-1)+fib(n-2) print fib(10)
用递归实现
列表的复制:
a=[1,2,3] b=a[:] print b
a[:]2边可以填数,从左边开始到右边结束
输出九九乘法口诀:
for i in range(1,10): print for j in range(1,i+1): print '%d*%d=%d'%(i,j,i*j),
外层循环决定行,内层循环决定列。print默认后面加换行。print内容后加,输出以空格为结尾。
补充知识:python循环的一个优化,原来方法可以再次封装调用,类似匿名函数
循环优化
每种编程语言都会强调需要优化循环。当使用Python的时候,你可以依靠大量的技巧使得循环运行得更快。然而,开发者经常漏掉的一个方法是:避免在一个循环中使用点操作。
例如,考虑下面的代码:
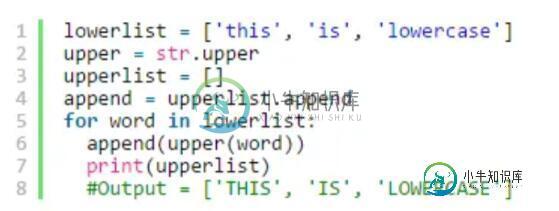
每一次你调用方法str.upper,Python都会求该方法的值。然而,如果你用一个变量代替求得的值,值就变成了已知的,Python就可以更快地执行任务。优化循环的关键,是要减少Python在循环内部执行的工作量,因为Python原生的解释器在那种情况下,真的会减缓执行的速度。
(注意:优化循环的方法有很多,这只是其中的一个。例如,许多程序员都会说,列表推导是在循环中提高执行速度的最好方式。这里的关键是,优化循环是程序取得更高的执行速度的更好方式之一。)
以上这篇python函数调用,循环,列表复制实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持小牛知识库。
-
假设我有一系列python函数: 我想这样称呼他们: 大概是这样的: 如果我有很多函数要调用,这是很有帮助的,但这将有for循环。在没有for循环的情况下,我是否有其他方法来执行此操作?
-
我想以小批量遍历ArrayList。 例如,如果ArrayList大小为75,批大小为10,我希望它处理记录0-10,然后10-20,然后20-30,依此类推。 我试过这个,但没有成功:
-
问题内容: 我正在尝试在循环内创建函数: 问题在于所有功能最终都相同。这三个函数都没有返回0、1和2,而是返回2: 为什么会发生这种情况,我应该怎么做才能获得分别输出0、1和2的3个不同函数? 问题答案: 你在后期绑定方面遇到了问题-每个函数都i尽可能晚地查找(因此,在循环结束后调用时,i将设置为2)。 可以通过强制早期绑定轻松修复:更改为以下形式: 缺省值(右手i输入i=i是参数名的默认值,i左
-
我使用以下程序集和c源(分别使用fasm和gcc)将一些程序集与一些c链接起来,以测试函数调用的成本 组件: c来源: 我得到的结果令人惊讶。首先,速度取决于我链接的顺序。如果我以的形式链接,典型的输出是 但是以相反的顺序链接,我得到了一个更像的输出: 他们的不同令人惊讶,但这不是我要问的问题。(此处有相关问题) 我要问的问题是,在第二次运行中,有函数调用的循环如何比没有函数调用的循环快,调用函数
-
问题内容: 有人可以解释吗? 什么是 […]? 问题答案: 只是Python告诉您您有一个循环引用。它足够聪明,不会进入尝试打印出来的无限循环。
-
我远离python有一段时间了。当我尝试下面的代码时,它会给我索引错误