
AI小程序之语音听写来了,十分钟掌握百度大脑语音听写全攻略

语音识别极速版能将60秒以内的完整音频文件识别为文字。用于近场短语音交互,如手机语音搜索、聊天输入等场景。支持上传完整的录音文件,录音文件时长不超过60秒。实时返回识别结果。本文主要介绍采用百度语音识别,实现小程序的听写功能。

1 系统框架
用到的技术主要有:百度语音识别和微信小程序。采用微信提供的录音管理器 recorderManager实现录音,录音格式aac。小程序将用户上传的语音提交给百度语音证识别服务,返回文本信息并显示出来。全部功能都在小程序客户端完成,不需要服务器,适合个人开发者学习调试使用,同时也为商业应用提供相应解决方案。
2创建小程序项目
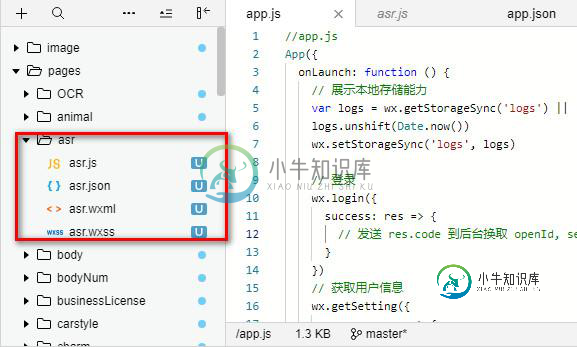
在根目录的全局配置文件app.json中增加:"pages/asr/asr",会自动创建相关页面文件,结构如下:
- asr.js:功能逻辑模块
- asr.wxss:页面样式文件
- asr.wxml:页面布局文件
- asr.json:页面配置文件
3 调用语音识别极速版API
3.1 首先要在控制台创建应用,调用语音识别极速版API,“获取API Key/Secret Key”。

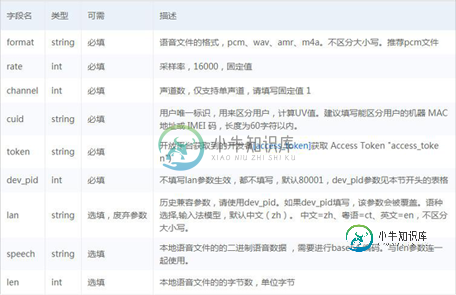
Body中放置请求参数,参数详情如下:
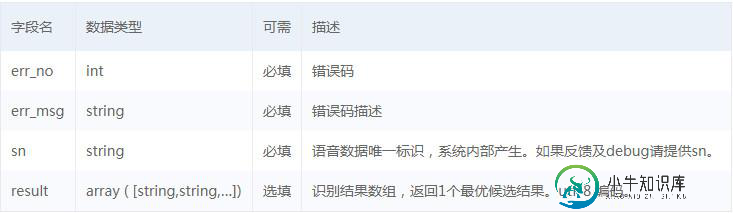
返回参数:
3.2 语音识别极速版功能实现
(1)发送URL请求核心代码




(2)定义按钮点击事件


(3)定义按钮点击事件



(4)修改页面样式文件



4 实现效果

到此这篇关于AI小程序语音听写的文章就介绍到这了,更多相关AI小程序语音听写内容请搜索小牛知识库以前的文章或继续浏览下面的相关文章希望大家以后多多支持小牛知识库!
-
本文向大家介绍python语音识别实践之百度语音API,包括了python语音识别实践之百度语音API的使用技巧和注意事项,需要的朋友参考一下 百度语音对上传的语音要求目前必须是单声道,16K采样率,采样深度可以是16位或者8位的PCM编码。其他编码输出的语音识别不出来。 语音的处理技巧: 录制为MP3的语音(通常采样率为44100),要分两步才能正确处理。第一步:使用诸如GoldWave的软件,
-
我试了很多,但都没找到,所以我希望你能帮助我。 我正在尝试构建我自己的语音识别应用程序,它不会显示对话框。 我已经编写了一些代码,它工作得很好,但我的问题是,识别器似乎停止了,而LogCat中没有任何错误或其他消息。 一个奇怪的事实是,“RecognitionListener”接口中的“onRmsChanged”仍然一直被调用,但不再调用“onBeginningOfSpeech”。 如果我在语音识
-
1.1. 目录 1.1.1. 功能操作路径 1.1.2. 选择适用的产品 1.1.3. 操作改写 1.1.4. 注意事项: 1.1.5. 书写规范: 1.1. 目录 本工具适用于因多音字、同音字而导致识别错误,可用该工具将错误的识别改写成为正确的识别给到意图处理,注意提交后将在5分钟后生效。 如「纸短情长」这四个字常识别为「指端清唱」,导致歌曲无法点播,可用这个工具将「指端清唱」改为「纸短情长」,
-
安装方法 执行 yum install libffi-devel yum install openssl-devel pip install scrapy scrapy的代码会安装在 /usr/local/lib/python2.7/site-packages/scrapy 中文文档在 http://scrapy-chs.readthedocs.io/zh_CN/latest/ 使用样例 创建
-
我正在开发一个用于录制通话的应用程序。这是我的代码片段。 这适用于android 7以下的设备,但当我使用Android 7移动设备时,我只能听到传出的声音,但听不到传入的声音。 有人能帮我修理它吗?
-
听音乐 选择音乐时,会显示以下的图标。 SensMe™ channels 使用音乐应用软件SensMe™ channels播放音乐。 详细请参阅[SensMe™ channels]。 UMD™ 可聆听UMD™MUSIC。 Memory Stick™ 可播放保存于Memory Stick™的音乐档案。 主机内存 可播放保存于主机内存的音乐档案。 (文件夹) 显示使用计算机新建的文件夹。且