
gradle中的增量构建浅析

文章目录 简介增量构建自定义inputs和outputs运行时API隐式依赖输入校验自定义缓存方法输入归一化其他使用技巧
简介
在我们使用的各种工具中,为了提升工作效率,总会使用到各种各样的缓存技术,比如说docker中的layer就是缓存了之前构建的image。在gradle中这种以task组合起来的构建工具也不例外,在gradle中,这种技术叫做增量构建。
增量构建
gradle为了提升构建的效率,提出了增量构建的概念,为了实现增量构建,gradle将每一个task都分成了三部分,分别是input输入,任务本身和output输出。下图是一个典型的java编译的task。
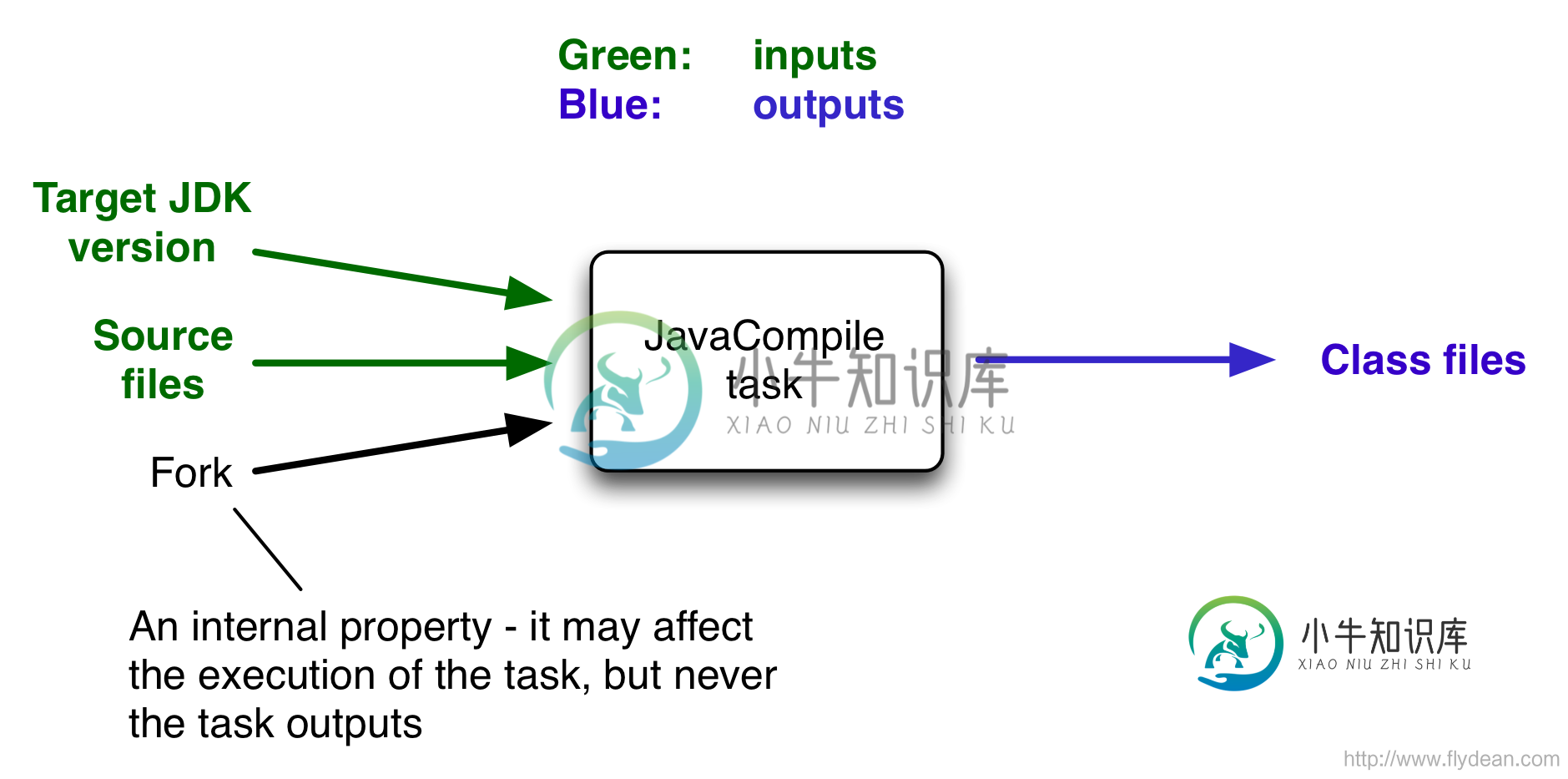
以上图为例,input就是目标jdk的版本,源代码等,output就是编译出来的class文件。
增量构建的原理就是监控input的变化,只有input发送变化了,才重新执行task任务,否则gradle认为可以重用之前的执行结果。
所以在编写gradle的task的时候,需要指定task的输入和输出。
并且要注意只有会对输出结果产生变化的才能被称为输入,如果你定义了对初始结果完全无关的变量作为输入,则这些变量的变化会导致gradle重新执行task,导致了不必要的性能的损耗。
还要注意不确定执行结果的任务,比如说同样的输入可能会得到不同的输出结果,那么这样的任务将不能够被配置为增量构建任务。
自定义inputs和outputs
既然task中的input和output在增量编译中这么重要,本章将会给大家讲解一下怎么才能够在task中定义input和output。
如果我们自定义一个task类型,那么满足下面两点就可以使用上增量构建了:
第一点,需要为task中的inputs和outputs添加必要的getter方法。
第二点,为getter方法添加对应的注解。
gradle支持三种主要的inputs和outputs类型:
- 简单类型:简单类型就是所有实现了Serializable接口的类型,比如说string和数字。
- 文件类型:文件类型就是 File 或者 FileCollection 的衍生类型,或者其他可以作为参数传递给 Project.file(java.lang.Object) 和 Project.files(java.lang.Object…) 的类型。
- 嵌套类型:有些自定义类型,本身不属于前面的1,2两种类型,但是它内部含有嵌套的inputs和outputs属性,这样的类型叫做嵌套类型。
接下来,我们来举个例子,假如我们有一个类似于FreeMarker和Velocity这样的模板引擎,负责将模板源文件,要传递的数据最后生成对应的填充文件,我们考虑一下他的输入和输出是什么。
输入:模板源文件,模型数据和模板引擎。
输出:要输出的文件。
如果我们要编写一个适用于模板转换的task,我们可以这样写:
import java.io.File;
import java.util.HashMap;
import org.gradle.api.*;
import org.gradle.api.file.*;
import org.gradle.api.tasks.*;
public class ProcessTemplates extends DefaultTask {
private TemplateEngineType templateEngine;
private FileCollection sourceFiles;
private TemplateData templateData;
private File outputDir;
@Input
public TemplateEngineType getTemplateEngine() {
return this.templateEngine;
}
@InputFiles
public FileCollection getSourceFiles() {
return this.sourceFiles;
}
@Nested
public TemplateData getTemplateData() {
return this.templateData;
}
@OutputDirectory
public File getOutputDir() { return this.outputDir; }
// 上面四个属性的setter方法
@TaskAction
public void processTemplates() {
// ...
}
}
上面的例子中,我们定义了4个属性,分别是TemplateEngineType,FileCollection,TemplateData和File。前面三个属性是输入,后面一个属性是输出。
除了getter和setter方法之外,我们还需要在getter方法中添加相应的注释: @Input , @InputFiles ,@Nested 和 @OutputDirectory, 除此之外,我们还定义了一个 @TaskAction 表示这个task要做的工作。
TemplateEngineType表示的是模板引擎的类型,比如FreeMarker或者Velocity等。我们也可以用String来表示模板引擎的名字。但是为了安全起见,这里我们自定义了一个枚举类型,在枚举类型内部我们可以安全的定义各种支持的模板引擎类型。
因为enum默认是实现Serializable的,所以这里可以作为@Input使用。
sourceFiles使用的是FileCollection,表示的是一系列文件的集合,所以可以使用@InputFiles。
为什么TemplateData是@Nested类型的呢?TemplateData表示的是我们要填充的数据,我们看下它的实现:
import java.util.HashMap;
import java.util.Map;
import org.gradle.api.tasks.Input;
public class TemplateData {
private String name;
private Map<String, String> variables;
public TemplateData(String name, Map<String, String> variables) {
this.name = name;
this.variables = new HashMap<>(variables);
}
@Input
public String getName() { return this.name; }
@Input
public Map<String, String> getVariables() {
return this.variables;
}
}
可以看到,虽然TemplateData本身不是File或者简单类型,但是它内部的属性是简单类型的,所以TemplateData本身可以看做是@Nested的。
outputDir表示的是一个输出文件目录,所以使用的是@OutputDirectory。
使用了这些注解之后,gradle在构建的时候就会检测和上一次构建相比,这些属性有没有发送变化,如果没有发送变化,那么gradle将会直接使用上一次构建生成的缓存。
注意,上面的例子中我们使用了FileCollection作为输入的文件集合,考虑一种情况,假如只有文件集合中的某一个文件发送变化,那么gradle是会重新构建所有的文件,还是只重构这个被修改的文件呢?
留给大家讨论
除了上讲到的4个注解之外,gradle还提供了其他的几个有用的注解:
@InputFile: 相当于File,表示单个input文件。
@InputDirectory: 相当于File,表示单个input目录。
@Classpath: 相当于Iterable,表示的是类路径上的文件,对于类路径上的文件需要考虑文件的顺序。如果类路径上的文件是jar的话,jar中的文件创建时间戳的修改,并不会影响input。
@CompileClasspath:相当于Iterable,表示的是类路径上的java文件,会忽略类路径上的非java文件。
@OutputFile: 相当于File,表示输出文件。
@OutputFiles: 相当于Map<String, File> 或者 Iterable,表示输出文件。
@OutputDirectories: 相当于Map<String, File> 或者 Iterable,表示输出文件。
@Destroys: 相当于File 或者 Iterable,表示这个task将会删除的文件。
@LocalState: 相当于File 或者 Iterable,表示task的本地状态。
@Console: 表示属性不是input也不是output,但是会影响console的输出。
@Internal: 内部属性,不是input也不是output。
@ReplacedBy: 属性被其他的属性替换了,不能算在input和output中。
@SkipWhenEmpty: 和@InputFiles 跟 @InputDirectory一起使用,如果相应的文件或者目录为空的话,将会跳过task的执行。
@Incremental: 和@InputFiles 跟 @InputDirectory一起使用,用来跟踪文件的变化。
@Optional: 忽略属性的验证。
@PathSensitive: 表示需要考虑paths中的哪一部分作为增量的依据。
运行时API
自定义task当然是一个非常好的办法来使用增量构建。但是自定义task类型需要我们编写新的class文件。有没有什么办法可以不用修改task的源代码,就可以使用增量构建呢?
答案是使用Runtime API。
gradle提供了三个API,用来对input,output和Destroyables进行获取:
- Task.getInputs() of type TaskInputs
- Task.getOutputs() of type TaskOutputs
- Task.getDestroyables() of type TaskDestroyables
获取到input和output之后,我们就是可以其进行操作了,我们看下怎么用runtime API来实现之前的自定义task:
task processTemplatesAdHoc {
inputs.property("engine", TemplateEngineType.FREEMARKER)
inputs.files(fileTree("src/templates"))
.withPropertyName("sourceFiles")
.withPathSensitivity(PathSensitivity.RELATIVE)
inputs.property("templateData.name", "docs")
inputs.property("templateData.variables", [year: 2013])
outputs.dir("$buildDir/genOutput2")
.withPropertyName("outputDir")
doLast {
// Process the templates here
}
}
上面例子中,inputs.property() 相当于 @Input ,而outputs.dir() 相当于@OutputDirectory。
Runtime API还可以和自定义类型一起使用:
task processTemplatesWithExtraInputs(type: ProcessTemplates) {
// ...
inputs.file("src/headers/headers.txt")
.withPropertyName("headers")
.withPathSensitivity(PathSensitivity.NONE)
}
上面的例子为ProcessTemplates添加了一个input。
隐式依赖
除了直接使用dependsOn之外,我们还可以使用隐式依赖:
task packageFiles(type: Zip) {
from processTemplates.outputs
}
上面的例子中,packageFiles 使用了from,隐式依赖了processTemplates的outputs。
gradle足够智能,可以检测到这种依赖关系。
上面的例子还可以简写为:
task packageFiles2(type: Zip) {
from processTemplates
}
我们看一个错误的隐式依赖的例子:
plugins {
id 'java'
}
task badInstrumentClasses(type: Instrument) {
classFiles = fileTree(compileJava.destinationDir)
destinationDir = file("$buildDir/instrumented")
}
这个例子的本意是执行compileJava任务,然后将其输出的destinationDir作为classFiles的值。
但是因为fileTree本身并不包含依赖关系,所以上面的执行的结果并不会执行compileJava任务。
我们可以这样改写:
task instrumentClasses(type: Instrument) {
classFiles = compileJava.outputs.files
destinationDir = file("$buildDir/instrumented")
}
或者使用layout:
task instrumentClasses2(type: Instrument) {
classFiles = layout.files(compileJava)
destinationDir = file("$buildDir/instrumented")
}
或者使用buildBy:
task instrumentClassesBuiltBy(type: Instrument) {
classFiles = fileTree(compileJava.destinationDir) {
builtBy compileJava
}
destinationDir = file("$buildDir/instrumented")
}
输入校验
gradle会默认对@InputFile ,@InputDirectory 和 @OutputDirectory 进行参数校验。
如果你觉得这些参数是可选的,那么可以使用@Optional。
自定义缓存方法
上面的例子中,我们使用from来进行增量构建,但是from并没有添加@InputFiles, 那么它的增量缓存是怎么实现的呢?
我们看一个例子:
public class ProcessTemplates extends DefaultTask {
// ...
private FileCollection sourceFiles = getProject().getLayout().files();
@SkipWhenEmpty
@InputFiles
@PathSensitive(PathSensitivity.NONE)
public FileCollection getSourceFiles() {
return this.sourceFiles;
}
public void sources(FileCollection sourceFiles) {
this.sourceFiles = this.sourceFiles.plus(sourceFiles);
}
// ...
}
上面的例子中,我们将sourceFiles定义为可缓存的input,然后又定义了一个sources方法,可以将新的文件加入到sourceFiles中,从而改变sourceFile input,也就达到了自定义修改input缓存的目的。
我们看下怎么使用:
task processTemplates(type: ProcessTemplates) {
templateEngine = TemplateEngineType.FREEMARKER
templateData = new TemplateData("test", [year: 2012])
outputDir = file("$buildDir/genOutput")
sources fileTree("src/templates")
}
我们还可以使用project.layout.files()将一个task的输出作为输入,可以这样做:
public void sources(Task inputTask) {
this.sourceFiles = this.sourceFiles.plus(getProject().getLayout().files(inputTask));
}
这个方法传入一个task,然后使用project.layout.files()将task的输出作为输入。
看下怎么使用:
task copyTemplates(type: Copy) {
into "$buildDir/tmp"
from "src/templates"
}
task processTemplates2(type: ProcessTemplates) {
// ...
sources copyTemplates
}
非常的方便。
如果你不想使用gradle的缓存功能,那么可以使用upToDateWhen()来手动控制:
task alwaysInstrumentClasses(type: Instrument) {
classFiles = layout.files(compileJava)
destinationDir = file("$buildDir/instrumented")
outputs.upToDateWhen { false }
}
上面使用false,表示alwaysInstrumentClasses这个task将会一直被执行,并不会使用到缓存。
输入归一化
要想比较gradle的输入是否是一样的,gradle需要对input进行归一化处理,然后才进行比较。
我们可以自定义gradle的runtime classpath 。
normalization {
runtimeClasspath {
ignore 'build-info.properties'
}
}
上面的例子中,我们忽略了classpath中的一个文件。
我们还可以忽略META-INF中的manifest文件的属性:
normalization {
runtimeClasspath {
metaInf {
ignoreAttribute("Implementation-Version")
}
}
}
忽略META-INF/MANIFEST.MF :
normalization {
runtimeClasspath {
metaInf {
ignoreManifest()
}
}
}
忽略META-INF中所有的文件和目录:
normalization {
runtimeClasspath {
metaInf {
ignoreCompletely()
}
}
}
其他使用技巧
如果你的gradle因为某种原因暂停了,你可以送 --continuous 或者 -t 参数,来重用之前的缓存,继续构建gradle项目。
你还可以使用 --parallel 来并行执行task。
到此这篇关于gradle中的增量构建的文章就介绍到这了,更多相关gradle增量构建内容请搜索小牛知识库以前的文章或继续浏览下面的相关文章希望大家以后多多支持小牛知识库!
-
问题内容: 我正在使用Jenkins 1.462,而Maven版本是3.0.4。在詹金斯,我启用了“增量构建-仅构建已更改的模块”复选框 我想找出两个问题: 增量构建是否足够? 在这里,如何在Subversion的多模块Maven构建中触发单个模块的Jenkins构建?例如,据说它不能以100%的频率工作。在这里,第19页的http://www.slideshare.net/andrewbayer
-
我在gradle构建中获得了java.lang.UnsupportedClassVersionError,它是一个multiproject gradle构建。我使用的是Java-8,到目前为止它还在工作,但是突然间它停止了工作,并开始抛出下面的异常。 下面是seeting.gradle 正如我已经提到的,这一直在工作,直到这些天,并开始抛出上面的异常。这里的任何帮助都是感激的。提前致谢
-
问题内容: 一个人如何使用Maven支持增量构建?那里有指南吗?(Google的最佳搜索结果令人失望) 问题答案: Maven默认情况下以增量方式生成,但是事实证明,编译器插件(即javac的核心)是如此之快,以至于每次构建新代码都不会成为代码库大小合理的瓶颈,而不是与构造大型程序集或运行大型测试进行比较套房。(与大多数语言一样,Java的编译速度比C ++快得多。)
-
我的问题是spring版本没有被识别为可变版本。那么我如何在字符串内部传递它呢?
-
本文向大家介绍gradle 分析构建,包括了gradle 分析构建的使用技巧和注意事项,需要的朋友参考一下 示例 在开始调整Gradle构建的性能之前,您应该建立基准并确定构建的哪些部分花费最多的时间。为此,您可以通过将--profile参数添加到Gradle命令来对构建进行概要分析: 构建完成后,您将在下./build/reports/profile/看到构建的HTML配置文件报告,如下所示:
-
问题内容: 我在Ubuntu上使用Android Studio。我启动了Android Studio,创建了一个“新项目”,并从开始。它引发了以下错误: 它还显示了一个带有圆圈的PNG文件和一个透明背景,文件名为: 在我再次尝试运行该应用程序之后,我现在有2个错误,而不是一个: 您能否帮助我解决问题? 问题答案: Android尚未为64位ubuntu构建SDK,从错误中我可以说您正在64位OS上