
linux grep正则表达式与grep用法详解

需要大家牢记:正则表达式与通配符不一样,它们表示的含义并不相同
正则表达式只是字符串的一种描述,只有和支持正则表达式的工具相结合才能进行字符串处理。本文以grep为例来讲解正则表达式。
grep命令
功能:输入文件的每一行中查找字符串。
基本用法:
grep [-acinv] [--color=auto] [-A n] [-B n] '搜寻字符串' 文件名
参数说明:
-a:将二进制文档以文本方式处理
-c:显示匹配次数
-i:忽略大小写差异
-n:在行首显示行号
-A:After的意思,显示匹配字符串后n行的数据
-B:before的意思,显示匹配字符串前n行的数据
-v:显示没有匹配行-A:After的意思,显示匹配部分之后n行-B:before的意思,显示匹配部分之前n行
--color:以特定颜色高亮显示匹配关键字
–color选项是个非常好的选项,可以让你清楚的明白匹配了那些字符。最好在自己的.bashrc或者.bash_profile文件中加入:
alias grep=grep --color=auto
每次grep搜索之后,自动高亮匹配效果了。
‘搜寻字符串'是正则表达式,注意为了避免shell的元字符对正则表达式的影响,请用单引号('')括起来,千万不要用双引号括起来("”)或者不括起来。
正则表达式分为基本正则表达式和扩展正则表达式。下面分别简单总结一下。
基本正则表达式
正则表达式学习,主要是对正则表达式元数据的学习。正则表达式本身没有什么高深的东西,本文仅仅对基本正则表达式的元数据进行一下总结:


扩展正则表达式
grep一般情况下支持基本正则表达式,可以通过参数-E支持扩展正则表达式,另外grep单独提供了一个扩展命令叫做egrep用来支持扩展正则表达式,这条命令和grep -E等价。虽然一般情况下,基本正则表达式就够用了。特殊情况下,复杂的扩展表达式,可以简化字符串的匹配。
扩展正则表达式就是在基本正则表达式的基础上,增加了一些元数据。
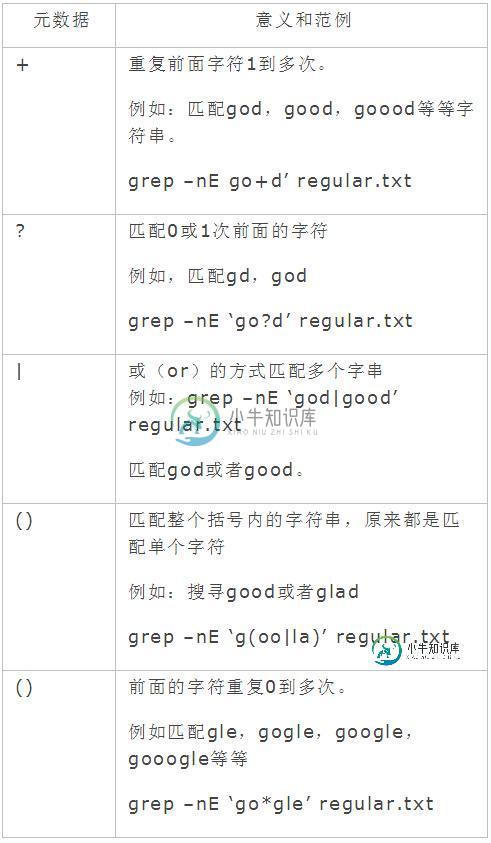
Linux下面正则表达式博大精深,上文支持总结了最常用的部分,如果熟练掌握的上面部分的正则表达式基本上可以满足日常使用了。
另外Linux很多命令支持正则表达式,比如find,sed,awk等等。请在使用的时候参照这些命令的手册使用正则表达式。
linux grep 正则表达式
grep正则表达式元字符集:
^ 锚定行的开始 如:'^grep'匹配所有以grep开头的行。
$ 锚定行的结束 如:'grep$'匹配所有以grep结尾的行。
. 匹配一个非换行符的字符 如:'gr.p'匹配gr后接一个任意字符,然后是p。
* 匹配零个或多个先前字符 如:'*grep'匹配所有一个或多个空格后紧跟grep的行。 .*一起用代表任意字符。
[] 匹配一个指定范围内的字符,如'[Gg]rep'匹配Grep和grep。
[^] 匹配一个不在指定范围内的字符,如:'[^A-FH-Z]rep'匹配不包含A-R和T-Z的一个字母开头,紧跟rep的行。
\(..\) 标记匹配字符,如'\(love\)',love被标记为1。
\ 锚定单词的开始,如:'\匹配包含以grep开头的单词的行。
\> 锚定单词的结束,如'grep\>'匹配包含以grep结尾的单词的行。
x\{m\} 重复字符x,m次,如:'0\{5\}'匹配包含5个o的行。
x\{m,\} 重复字符x,至少m次,如:'o\{5,\}'匹配至少有5个o的行。
x\{m,n\}重复字符x,至少m次,不多于n次,如:'o\{5,10\}'匹配5--10个o的行。
\w 匹配文字和数字字符,也就是[A-Za-z0-9],如:'G\w*p'匹配以G后跟零个或多个文字或数字字符,然后是p。
\b 单词锁定符,如: '\bgrep\b'只匹配grep。
常用的 grep 选项有:
-c 只输出匹配行的个数。
-i 不区分大小写(只适用于单字符)。
-h 查询多文件时不显示文件名。
-l 查询多文件时只输出包含匹配字符的文件名。
-n 显示匹配行及行号。
-s 不显示不存在或无匹配文本的错误信息。
-v 显示不包含匹配文本的所有行。
-V 显示软件版本信息
使用grep匹配时最好用双引号引起来,防止被系统误认为参数或者特殊命令,也可以匹配多个单词。
关于匹配的实例:
grep -c "48" test.txt 统计所有以“48”字符开头的行有多少
grep -i "May" test.txt 不区分大小写查找“May”所有的行)
grep -n "48" test.txt 显示行号;显示匹配字符“48”的行及行号,相同于 nl test.txt |grep 48)
grep -v "48" test.txt 显示输出没有字符“48”所有的行)
grep "471" test.txt 显示输出字符“471”所在的行)
grep "48;" test.txt 显示输出以字符“48”开头,并在字符“48”后是一个tab键所在的行
grep "48[34]" test.txt 显示输出以字符“48”开头,第三个字符是“3”或是“4”的所有的行)
grep "^[^48]" test.txt 显示输出行首不是字符“48”的行)
grep "[Mm]ay" test.txt 设置大小写查找:显示输出第一个字符以“M”或“m”开头,以字符“ay”结束的行)
grep "K…D" test.txt 显示输出第一个字符是“K”,第二、三、四是任意字符,第五个字符是“D”所在的行)
grep "[A-Z][9]D" test.txt 显示输出第一个字符的范围是“A-D”,第二个字符是“9”,第三个字符的是“D”的所有的行
grep "[35]..1998" test.txt 显示第一个字符是3或5,第二三个字符是任意,以1998结尾的所有行
grep "4\{2,\}" test.txt 模式出现几率查找:显示输出字符“4”至少重复出现两次的所有行
grep "9\{3,\}" test.txt 模式出现几率查找:显示输出字符“9”至少重复出现三次的所有行
grep "9\{2,3\}" test.txt 模式出现几率查找:显示输出字符“9”重复出现的次数在一定范围内,重复出现2次或3次所有行
grep -n "^$" test.txt 显示输出空行的行号
ls -l |grep "^d" 如果要查询目录列表中的目录 同:ls -d *
ls -l |grep "^d[d]" 在一个目录中查询不包含目录的所有文件
ls -l |grpe "^d…..x..x" 查询其他用户和用户组成员有可执行权限的目录集合
以上给大家介绍的grep与正则表达式和linux grep正则表达式,希望大家喜欢。
-
有没有人试图描述与正则表达式匹配的正则表达式? 由于重复的关键字,这个主题几乎不可能在网上找到。 它可能在实际应用程序中不可用,因为支持正则表达式的语言通常具有解析它们的方法,我们可以将其用于验证,以及一种在代码中分隔正则表达式的方法,可用于搜索目的。 但是我仍然想知道匹配所有正则表达式的正则表达式是什么样子的。应该可以写一个。
-
本文向大家介绍iOS 正则表达式详解,包括了iOS 正则表达式详解的使用技巧和注意事项,需要的朋友参考一下 一、系统自带正则表达式用法 除了正则可以用,还有NSScanner这个类可以达到某些相同的效果 1、创建正则表达式对象 2、正则表达式对象可调用的方法 5.谓词 以上所述是小编给大家介绍的iOS正则表达式,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢
-
本文向大家介绍shell脚本之正则表达式、grep、sed、awk,包括了shell脚本之正则表达式、grep、sed、awk的使用技巧和注意事项,需要的朋友参考一下 --正则-- 基础正则 ^word ##搜索以word开头的 vi/vim中 ^ 一行的开头 word$ ##搜索以word结尾的 vi/vim中 $ 一行的结尾 ^$ ##表示空行 .
-
我将一个regex模式列表传递给< code>grep来检查syslog文件。它们通常匹配IP地址和日志条目; 这只是一个模式列表,例如我正在循环传递的“1\.2\.部分,因此我无法传递“-v”。 我很困惑试图做上述的逆,不匹配线与某个IP地址和错误!1.2.3.4.*已爆炸”将匹配除1.2.3.4告诉我它已爆炸之外的任何syslog行。我必须能够包括一个IP地址不匹配。 在Stack Overf
-
本文向大家介绍正则表达式使用示例详解,包括了正则表达式使用示例详解的使用技巧和注意事项,需要的朋友参考一下 正则表达式(Regular Expression)是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为"元字符")。 正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。 下面通过实例代码介绍下正则表达式使用 //一个数据类型,记录文本规则,一些事先定
-
本文向大家介绍详解js正则表达式语法介绍,包括了详解js正则表达式语法介绍的使用技巧和注意事项,需要的朋友参考一下 本文介绍了js正则表达式,具体如下: 1. 正则表达式规则 1.1 普通字符 字母、数字、汉字、下划线、以及后边章节中没有特殊定义的标点符号,都是"普通字符"。表达式中的普通字符,在匹配一个字符串的时候,匹配与之相同的一个字符。 举例1:表达式 "c",在匹配字符串