《途虎养车》专题
-
用Jsoup刮雅虎答案
我正试图从雅虎答案中刮取关键词搜索的结果,在我的案例中,“酒精上瘾”。我正在使用Jsoup和URL修改来浏览搜索结果的页面以刮取结果。然而,我注意到,即使我为“最新”结果输入了URL,它仍然显示“相关性”结果,更糟糕的是,结果与浏览器上显示的不完全相同。 例如,最新结果的URL是:http://answers.yahoo.com/search/search_result?p=collow+addi
-
虎嗅网RSS阅读器
使用KissXML和正则表达式解析虎嗅网的RSS。代码还用了AFNetworking类库。 [Code4App.com]
-
 虎彩 前端 10min 已oc
虎彩 前端 10min 已oc4.25 自我介绍 问我会什么技术栈 项目用了什么技术栈 ES6有什么新东西 TS自带的泛型有哪些 反问: 老项目vue2+elementUI 新项目vue3+ts ---------------------------------------- 4.29 中午睡午觉 开了免打扰没接到电话 睡醒之后给hr打了之后说了一下 给我 offer 了 《缺人》
-
Hadoop MapReduce的用途
> 据说MapReduce接收一个文件并生成键值对。什么是钥匙?只是一个词,一个词的组合还是别的什么?如果关键是文件中的单词,那么为MapReduce编写代码的目的是什么?MapReduce应该在不实现特定算法的情况下做同样的事情。 如果所有的东西都转换成键值对,那么Hadoop所做的就是像JAVA和C#一样创建一个字典,Wright?也许Hadoop可以以更高效的方式创建字典。除了效率,Hado
-
Querydsl JPQLQuery fetchAll用途
我们正在将一个项目从Querydsl版本3更新到版本4。子查询的工作方式发生了变化。在版本3中,可以编写如下子查询: 我将代码升级到: 我的问题是关于我在查询末尾添加的fetchAll方法。我不确定是否有必要。我认为它是list的替代品,但我的同事指出返回类型只是JPQLQuery,它已经由where返回。 用于fetchAll状态的JavaDoc: 将“fetchJoin all propert
-
5.11.发布途径
Rust 项目使用一个叫做“发布途径”的概念来管理发布。理解这个选择你的项目应该使用哪个版本的 Rust 的过程是很重要的。 概览 Rust 发布有 3 种途径: 开发版(Nightly) 测试版(Beta) 稳定版(Stable) 新的开发发布每天创建一次。每 6 个星期,最后的开发版被提升为“测试版”。在这时,它将只会收到修改重大错误的补丁。6 个星期之后,测试版被提升为“稳定版”,而成为下一
-
特性和用途
JSSE 包括以下重要的特性: 作为一个标准的 JDK 组件 可扩展的,基于供应商的架构 100% 纯 Java 实现 提供了支持SSL版本 2.0 和 3.0,TLS 1.0 和以后版本的API,以及SSL 3.0 、TLS 3.0的实现和 包含可以实例化创建安全通道(SSLSocket、SSLServerSocket SSLEngine)的类 支持作为 SSL 握手的一部分的密码套件协商,用来
-
 富途一二面
富途一二面一面10.10 当天下午约第二天二面 70min 没录音具体问题记不清了😂 手撕快排 stl八股 c++八股 c++11 网络八股 问了点数据库问题 二面10.11 50min 无八股 无手撕 全程场景题 面试官说要一起讨论 项目具体场景分析 实现底层库rand场景分析 内存分配场景分析 问了下自己认为技术的优缺点 许愿个hr面
-
 高途Golang 一面
高途Golang 一面1. 自我介绍 2. 实习的业务 a. 异步接口对接的技术方案 3. 极客兔兔rpc框架 a. 项目需求,目的,如何实现 b. grpc有什么特点 ⅰ. protobuf ⅱ. proto版本兼容 ⅲ. 编码解码做了什么操作 ⅳ. 为什么比http速度更快 1. 序列化方式 4. go语言经常使用的代码包、框架 a. 协程相关的包有用过吗 b. waitGroup是怎么使用的、注意的点 ⅰ. Do
-
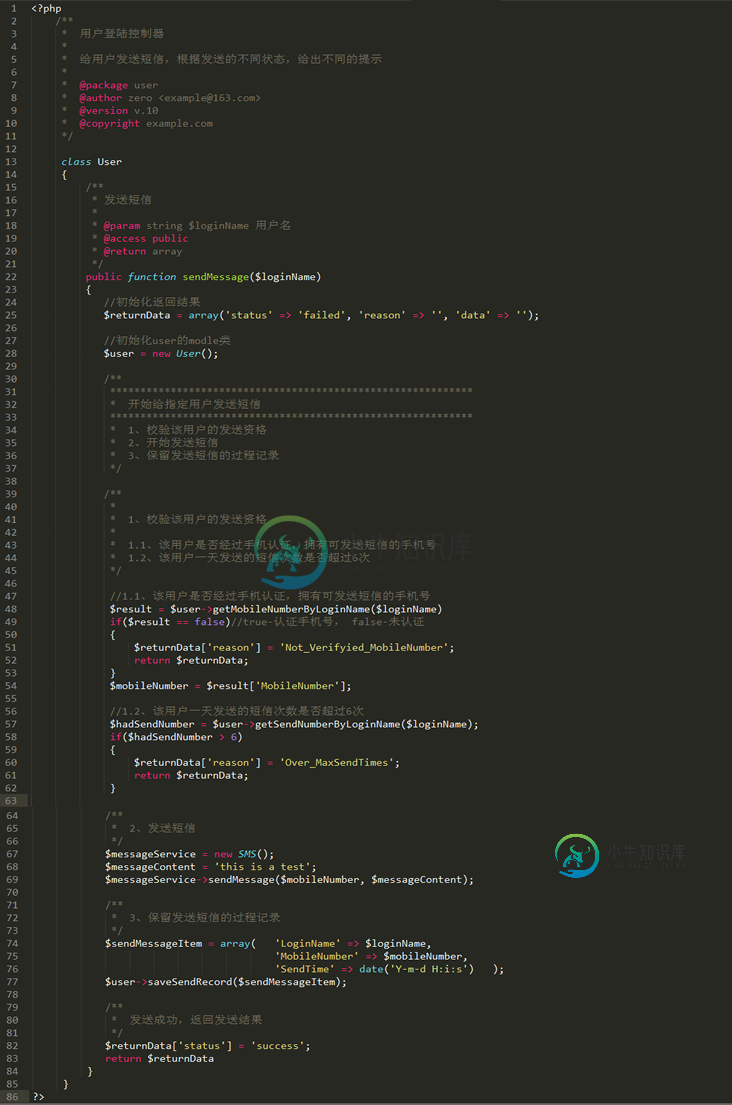 培养自己的php编码规范
培养自己的php编码规范本文向大家介绍培养自己的php编码规范,包括了培养自己的php编码规范的使用技巧和注意事项,需要的朋友参考一下 为什么我们要培养自己的编码规范? 我们写代码的时候,一个好的编码规范,对我们来说能够起到很多意向不到的效果。至少会有一下的好处: 1、提高我们的编码效率。整齐划一的代码方便我们进行复制粘贴嘛! 2、提高代码的可读性。 3、显示我们专业。别人看到了我们的代码,发现整个代码的书写流程都整齐划
-
Tensorflow,喂养占位符与估计(model_fn)?
我想建立一个lstm模型。但我正在得到
-
 双非大三 虎牙面经
双非大三 虎牙面经一面 大概30分钟 自我介绍 姓名 双非院校 专业 主修课程 项目经历 竞赛经历 校园经历等 项目 Q1:介绍自己的项目及项目难点 主要介绍了RabbitMQ和ActiveMQ在项目中的应用,没有准备很充足,应该多看看RabbitMQ或者activeMQ的原理对比。中间提问了两个问题。 1、为什么用了RabbitMQ和activeMQ,他们之间有什么不同?A:不是很了解两者,主要挑了RabbitM
-
 奇虎 360 Pika 文档手册
奇虎 360 Pika 文档手册Pika是360开源的类Redis存储系统。 Pika 是 360 DBA 和基础架构组联合开发的类 Redis 存储系统,完全支持 Redis 协议,用户不需要修改任何代码,就可以将服务迁移至 Pika。有维护 Redis 经验的 DBA 维护 Pika 不需要学习成本。 Pika 主要解决的是用户使用 Redis 的内存大小超过 50G、80G 等等这样的情况,会遇到启动恢复时间长,一主多从代
-
 虎牙C++0526二面面经
虎牙C++0526二面面经虎牙二面面经0526 1. c++结构体的内存对齐是怎么样的 2. mysql的索引是怎么设计的 3. 有哪些常见的索引失效的场景 4. c++标准库里优先队列是怎么实现的? 5. 堆排序是怎么做的 6. 快排是怎么实现的 7. tcp四次挥手过程 8. 乐观锁怎么实现的 9. 常用linux命令 10. 反问 持续大概20分钟,问的都还蛮基础 #虎牙信息集散地# #虎牙#
-
 虎牙C++0518一面凉经
虎牙C++0518一面凉经1. 自我介绍 2. 你这边打算实习多久?能实习多久,给个具体的时间 3. c++ virtual是什么 4. 虚函数存在哪里 5. 线程独占的资源有哪些(没答好,然后他问我,那你说一下线程享受哪些共同的资源,这个我答得还行,一般般吧) 6. shared_ptr存了什么? 7. 申请shared_ptr需要额外占多少空间? 8. 一个指针有多大? 9. epoll的工作原理? 10. 数据库第一