《上海爱数》专题
-
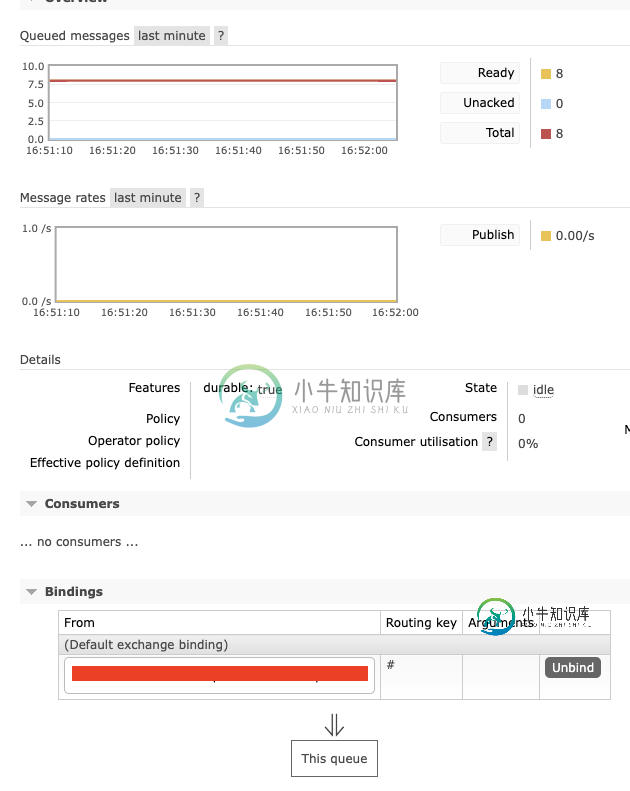 PolledProcessor在Spring云数据流上的问题
PolledProcessor在Spring云数据流上的问题我正在使用PolledProcessor提出一个spring云数据流处理器。我遵循了下面的示例https://spring.io/blog/2018/02/27/spring-cloud-stream-2-0-polled-consumers。下面是我的代码。我将带有源管道的流部署到这个处理器(源polled-processor)到scdf,并让源发布一些消息。我确认处理器每秒轮询一次来自scdf
-
neo4j:属性数组上的密码查询
我有一个域类,它具有名称为“alias”的属性,它是一个字符串的arraylist,如下所示: alias包含以下值:{“John Doe”、“Alex Smith”、“Greg Walsh”} 我希望能够使用如下所示的存储库查询进行类似“I saw Smith Today”的查询,并获得数组值输出“Alex Smith”: 我想做一个输入查询子字符串匹配的数组值。 例如:输入查询:“我今天看到史
-
View init上的SwiftUI可选绑定参数
我有一个视图,有时用于浏览数据,有时用于选择数据。 当用于浏览时,它由NavigationLink呈现。 当用于选择数据时,它以模式表的形式显示,并通过将绑定布尔值isPresented设置为false来关闭,因此我可以使用表函数onDismiss。 然而,在浏览模式下,我需要一种方法来跳过初始化isPresent绑定布尔值。正确的方法是view init()上的可选参数,但我尝试的所有内容都会抛
-
php网站上的Firebase analytics和crashlytics数据
-
多个Web资源上的全局参数
我正在使用jersey、jax-rs构建一个web服务应用程序 我在路径“/authenticate”处有一个 jax-rs 资源文件 我有多个带有独立路径的方法,比如“/user”“/test” } 正如对jersey客户端的建议,我使用来自客户端的单个web资源,并使用.path(“/xxx”)从同一web资源构建后续的web资源。 以下是我创建初始 Web 资源的方式 以下是我随后如何使用网
-
bot提及-discord.py上的触发器函数
我目前正在使用discord.py开发一个不和谐机器人。我的问题是,我怎么能触发一个功能,当我提到机器人。我在考虑一个if语句,但我不知道,我需要调用哪些变量。 代码的其余部分工作正常。如果我能得到一个代码片段就好了:)
-
32位linux上同时TCP/IP连接数
由于端口号是16位,在任何给定时间,单个Linux盒上最多只能有65536个端口。而TCP/IP需要一个端口号才能与外界对话。1)当客户机建立连接时,选择临时端口号。2)当监听套接字的服务器接受连接时,分配端口号。 因此,根据我的理解,在任何给定时间,给定机器上只能存在最多65536个TCP/IP连接。 那么,为什么有些或大多数负载均衡器要求20万个或更多的并发连接呢?
-
在iOS上解密AES-128加密数据
我正在尝试解密AES加密数据(在. NET中加密),但我的解密结果字符串似乎不可读,并且我没有收到任何错误。 数据加密使用: < li>Padding: PKCS7Padding < li>KeySize: 128 < li >模式:CBC, 我有InItVector、PassCode、salt和NumberOfPassword(3)次迭代。 这是我的代码: 下面是在 .NET 端加密数据的代码:
-
泽西FormData,上传多个文件数据
我在Jersey写了一个Rest服务来上传多个文件。如下图所示。但是我需要Restservice类中的属性名,即name=“metadata”和name=“file”。 选择XML文件1: 选择PDF文件2: FormDataContentDisposition仅从表单中提取内容类型、文件名,而不是输入类型名称=“属性。 任何帮助都将不胜感激。 我张贴使用超文本标记语言的请求如下所示。 也发布HT
-
Android上的数组到字符串[重复]
我有一个字符串数组。我想将这个字符串数组和两个字符串进行比较,所以我首先将数组分配给变量,然后将这个变量和字符串进行比较。如果数组被转换为等于第一个字符串,则执行其他等于第二个字符串的操作。但它会引发<code>无法解析方法字符串<code>错误。
-
在负载上获取数据(NodeJS、JS、exports)
我在JS中有一个函数,它获取一些数据,然后在一个函数中使用它来加载POST: 我想使用它后,我呈现页面,所以一些结果将已经存在之前,需要加载更多。有点像这样: 但我得到一个错误: 我如何使函数在浏览器中启动,这样我就不会因为fetch和window不存在而得到nodeJS错误?
-
在Linux上接收UDP广播数据包
我们现有的软件定期向本地子网(X.X.X.255)上的特定端口(7125)广播UDP数据包。我们的监控软件运行在HP-UX(11.11)上,可以接收这些数据包,没有问题。然而,在将监控软件移植到Linux(RHEL6.1)之后,我们发现它并没有接收到广播数据包。tcpdump显示了到达Linux主机的数据包,但内核不会将它们发送给我们的软件。 我使用了几个Python2.x脚本,这些脚本模拟了监控
-
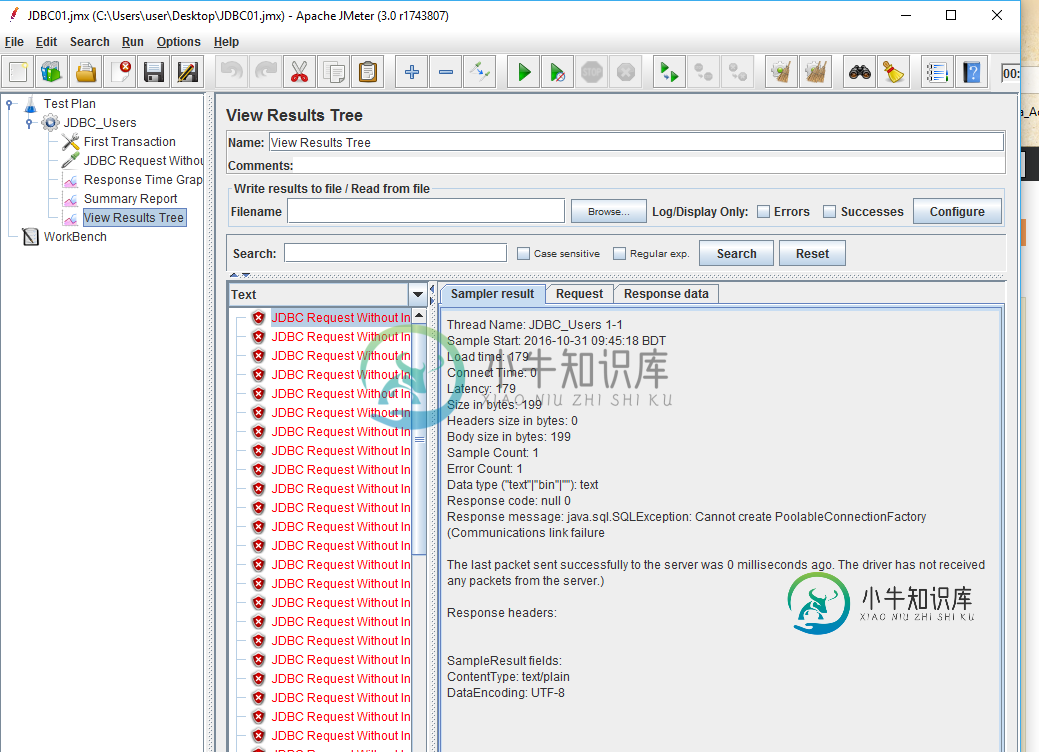 jmeter上JDBC请求的数据库连接
jmeter上JDBC请求的数据库连接对于Jmeter上的JDBC请求,我已经用giving正确地配置了数据库连接配置 数据库URL-jdbc:mysql://developmentdb.cwwxeukesrtn.ap-southeast-1.rds.amazonaws.com;development_db JDBC驱动程序类-com.mysql.JDBC.Driver 响应消息: java.sql.sqlException:无法创建
-
排序数组上的Swift与Kotlin性能
我尝试在和中排序一个大小为100000000的数组,我可以看到它们之间存在巨大的性能差距。对于这个数字,几乎比快倍(在我的机器上)。 我记录了一些结果,发现当大小在10000左右或更小时,swift的速度更快,但一旦数值上升,就会变得比慢得多。 下面是Swift和Kotlin的代码, 迅捷 科特林 下面是两个记录的时间, 迅捷 因此,在这里,您可以看到在大小增加时变得极其缓慢,尽管在数量较小时它会
-
web.xml中的上下文参数是什么?
什么