《哈啰出行》专题
-
操作SHA256哈希的大型文本数据库的最有效方法?
我必须经常在这种格式的大型(高达1G)CSV数据库中搜索哈希 在C.这需要非常快,内存使用不是问题(最低32G)。我发现这非常接近我的想法:将数据加载到内存中,一次性按哈希排序数据库,按哈希的第一个n字节索引,然后通过较小的子列表搜索。但是上面的帖子似乎没有解决我中间的一个问题。因为我不是一个密码学的家伙,我想知道哈希的分布,以及它是否可以用来更快地搜索子列表。对此或我的总体方法有什么建议吗?
-
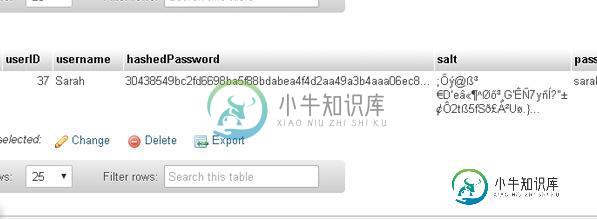 从数据库检索salt值时,我的哈希密码值不匹配
从数据库检索salt值时,我的哈希密码值不匹配我有个问题。从数据库检索salt值时,我的哈希密码值不匹配。 登记php > 用户输入用户名和密码。 通过POST收集用户名和密码。 生成随机盐值将盐值添加到密码值的末尾(由用户输入)。并散列全部值。 将用户名、盐、hashed密码和原始密码插入数据库(仅用于测试) } 登录。php > if(isset($_POST["用户名"]) }
-
为什么在哈希图中具有空值或空键会很有用?
问题内容: 不允许空键或值,而允许空值和1个空键。 问题: 为什么会这样呢? 在HashMap中具有这样的键和值有什么用? 问题答案: 1.为什么会这样? HashMap比Hashtable更新,并修复了其一些限制。 我只能猜测设计师在想什么,但这是我的猜测: Hashtable通过调用每个键来计算每个键的哈希值。如果键为null,则此操作将失败,因此这可能是不允许将null作为键的原因。 如果键
-
Java HashMap如何使用相同的哈希码处理不同的对象?
问题内容: 根据我的理解,我认为: 两个对象具有相同的哈希码是完全合法的。 如果两个对象相等(使用equals()方法),则它们具有相同的哈希码。 如果两个对象不相等,则它们不能具有相同的哈希码 我对么? 现在,如果正确的话,我有以下问题:HashMap内部使用对象的哈希码。因此,如果两个对象可以具有相同的哈希码,那么如何HashMap跟踪它使用的键? 有人可以解释HashMap内部如何使用对象的
-
将Spring Security SAML配置为使用SHA-256作为安全哈希算法
我正在研究Spring SAML和Microsoft ADFS 3.0之间的集成。甚至它已经在Spring SAML的留档中声明为: 双击提供程序打开它,选择tab Advanced并将“安全哈希算法”更改为SHA-1 我知道Spring SAML目前只支持SHA-1作为哈希算法,但我的要求是使用SHA-256。如果我尝试仅在ADFS中为SHA-256配置,它将不起作用。我想我得对Spring S
-
无法解析类com。云蜂。哈德逊。插件。文件夹文件夹
我试图使用groovy脚本从jenkins收集数据并收到错误: 无法解析类com。云蜂。哈德逊。插件。文件夹文件夹 下面是代码: 错误是: rg.codehaus.groovy.control.MultipleCompilationErrorsExceptio n:启动失败: Script1.groovy: 12:无法解析类com.cloudbees.hudson.plugins.folder.文
-
如何在Java中生成共享相同哈希代码的字符串?
用Java编写的现有系统使用字符串的哈希代码作为负载平衡的路由策略。 现在,我无法修改系统,但需要生成共享相同哈希代码的字符串来测试最坏的情况。 我从命令行提供这些字符串,并希望系统将所有这些字符串路由到同一个目的地。 有可能生成大量共享相同哈希代码的字符串吗? 为了明确这个问题: 备注:任何hashCode值均可接受。对字符串是什么没有限制。但它们应该彼此不同。 编辑:不接受String类的重写
-
此应用程序没有配置Android Key哈希。-使用Facebook SDK登录
我有问题与Facebook帐户登录在我的应用程序。我读到Facebook Doc。我做了脸书医生的所有步骤。 首次在应用程序中使用facebook帐户登录-成功!然后在应用程序中注销。我想用我的facebook帐户再次登录。但是不工作!!我拿了这个例外!请帮帮我! 例外:此应用程序没有配置Android Key哈希。在超文本传输协议中配置应用密钥哈希:developers.facebook.com
-
线性探测哈希表中数组M的大小应该有多大?
我试图理解使用Java实现的线性探测哈希表。然而,我对理解为什么M的初始值为30001感到失望。下面给出了代码的框架。 我的问题是为什么M在这里被初始化为30001。这是经验法则吗?初始化线性探测哈希表时,我应该如何确定M的大小?
-
如何在Ruby中从哈希表中获取第一个键和值对
我试图从ruby中的哈希表中获取第一个键和值键。我不知道散列的键值,因为它被传递给了方法。我在网上找不到如何将第一个键/值作为单独的哈希表查找。我认为只会试图找到一个名为0的元素,当我运行代码时,它只会返回。 我知道我可以找到密钥名和值,然后根据它们创建一个新的哈希,但我想知道是否有更简单的方法来做到这一点,这样我就可以立即得到一个哈希。 下面是我的代码: 这让我得到了正确的结果问题是我不明白为什
-
哈什地图。在两个hashmaps之间查找具有相同值的键
-
Spring Boot—如何手动创建bean并将其传递给哈希映射
要将类放入HashMap中。为此,我用@Service创建了一个Bean。就是这样: 这样做对吗?
-
如何使用PBKDF2在Java和Ruby中生成相同的安全哈希
我正在将一个web应用程序从Ruby移植到Java,并希望允许用户在不重置密码的情况下登录。下面是使用pbkdf2 gem生成哈希的Ruby代码: 读取Ruby gem的源代码时,它使用openssl::digest.new(“sha256”)作为默认散列函数,并生成一个32字节的值,该值使用“unpack(”h*“)”转换为一个64字符串。 所以,在Java,我尝试了以下几种方法: 使用pass
-
我应该使用哪种哈希算法来检查文件重复性
我有一个WCF服务,它接收XML文件(以字符串参数形式)进行处理。现在我想实现一个错误日志程序。我希望记录发生的异常,以及产生错误的XML文件。 为此,我创建了一个MySQL数据库,文件将存储在一个长blob字段中。 我的疑问是如何避免在存储文件的表中出现重复,因为用户可以重复提交相同的文件。为了节省存储空间,我想确定已经保存了完全相同的文件,在这种情况下,只需重用引用。 哪种方法最好?我的第一个
-
如何在Java中获取哈希算法名称的对象标识符
我必须执行密码算法名称和它们的对象标识符之间的转换。我使用Java加密体系结构(JCA)和Bouncy Castle作为安全提供程序。用JCA本身将OID转换为文本名称是相当容易的。 但是我如何执行从文本名称到OID的反向转换呢?在JCA中似乎没有办法获得算法名称的别名。Bouncy Castle 1.50具有映射,它将算法名称连接到OID,但所有这些映射都有限制访问。