《中国农业银行》专题
-
 中国青年出版社视觉设计面试
中国青年出版社视觉设计面试共1轮面试 面试的视觉设计岗,一轮面试后,笔试挂掉 一面:首先自我介绍,介绍作品集满意的作品。 考察了专业知识的掌握程度还有性格考察, 包括对设计趋势的认识,人工智能的认识, Q:为什么选择这个岗位。 问题比较简单,考察逻辑能力和平时的积累多少。 笔试:是针对一个产品做一个视觉宣传页面。时间一个礼拜,感觉还是比较注重最后的完成效果,由于没有把握好时间,做的比较粗糙,最后意料之中的挂掉了。 总的来说
-
zipimport — 从ZIP归档中国年加载Python代码
Example # zipimport_make_example.py import sys import zipfile if __name__ == '__main__': zf = zipfile.PyZipFile('zipimport_example.zip', mode='w') try: zf.writepy('.') zf.writ
-
 中国电信解决方案工程师一面
中国电信解决方案工程师一面双非本,坐标地级市分公司,总共感觉十分钟不到 1.自我介绍 2.说说实习干了啥 3.看项目上写的有商业计划书,说说怎么进行商业模型分析的 4.担任学生干部,说说主要都做了什么 结束,没有反问环节 面试间不隔音,一面前里面面试官大声密谋听的清清楚楚🤣多少人过笔试,多少人筛过简历,要录取多少个,我前一个好像是研究生,张嘴就是SCI,拿研究成果跟清华那个比怎么怎么好,听得我一愣一愣的,想走了都
-
 中软国际(长沙)Java开发实习 一面
中软国际(长沙)Java开发实习 一面1、自我介绍 2、介绍项目 3、controller层web路径访问顺序,前后端的交互流程 4、Dao层涉及的文件 5、mapper和xml文件,怎么关联的 6、怎么理解运用数据库的,举生活例子或代码说明 7、一段代码中,先删a表再删b表有无影响,两表是无关系的 8、实现某一事务的流程所需步骤 9、SQL题:具体用户记录唯一的表中,初始化时用户却产生多条记录,怎么删除多余的(只保留任意一条) 10
-
 中国南方航空社招信息类面经
中国南方航空社招信息类面经这个单位的面筋很少,我也来写一个供大家参考。 6.20官网投递 7.6收到笔试短信 7.9做了线上的考试, 考试分两个部分 1)专业知识(我投的软件测试),这部分题量不大,比较基础的一些知识。 2)托业考试(包含英语听力&阅读&语法),题量巨巨巨巨大,100道听力,100道阅读,个人感觉题的难度从易到难在递增(CET-6飘过选手) 7.21收到面试短信 7.23线上面试, 这个就比较坑了,给我分到
-
中国天气预报与万年历Chrome扩展
此Chrome扩展提供两个非常实用的功能:天气预报与万年历。通过设定此扩展可以提供国内多个城市的2-5天的天气预报。万年历功能提供1901-2049的农历与公历日期资料。此扩展的数据来源于中国天气网,扩展作者朱才。 介绍内容来自 http://www.chromepub.com/
-
 中国移动安全运营岗一面凉经
中国移动安全运营岗一面凉经面试官一共有三个,主要有两个负责提问,时长15min。 一开始是做自我介绍。 自我介绍完后面试官说我的简历是一片空白,他们看不到,让我再说一下自己的相关经历,我就把项目介绍了一遍,又把实习介绍了一遍。 讲完后有个面试官说说我跟他们的岗位不是很匹配(其实我做的项目还是比较和安全相关的,而且要是觉得不匹配一开始别发面不就完了还省得浪费双方时间,还是说移动也有kpi?),问我为什么要报这个岗,还问了一下
-
 9.03 国创中心(大模型后端开发岗)
9.03 国创中心(大模型后端开发岗)一面技术面: 1.自我介绍 2.介绍实习的项目 3.redis有用在哪些地方 4.redis为什么性能好? 5.mysql有了解吗? 6.场景题,找出在表A但不在表B中的数据?left join + is null 微服务项目的问题 7.谈一谈对微服务的理解? 8.openfeign底层原理(问好像不是这么问的,但我答了feign的底层) 9.开放题:我们的主要业务主要是做大模型的相关产品,进来的
-
 Unity中国 后端暑期实习 一面+二面
Unity中国 后端暑期实习 一面+二面之前投递了Unity中国的后端实习生,过几天HR给我打电话问我有没有继续读研究生的打算,我说有。她就说那可能她那边就只能把我放第二批了。我当时以为已经寄了,没想到过了十来天就发面试通知了。 Unity中国的一面和二面是挨在一起的,从上午10:00到11:45。 一面面试官感觉特别娇羞,写算法题的时候他给我代码中的问题,我当时没反应过来,顿了一下。他还跟我抱歉说是不是打断你了抱歉抱歉。 二面面试官感
-
 中国移动需求分析工程师一面
中国移动需求分析工程师一面大概是4月十几号进行的笔试初筛,时长两个小时,题型网上都有介绍,基本上比较简单,大概一周之后就通知进行一面。 一面流程,先进入审核面试间,看下证件之类的。随后是正式面试,面试间内三人,一位女士(比较年轻),两位男士(中年)。 简单的自我介绍。 女士面试官针对于简历的项目问题开始提问,背景,实际的工作内容等等,会深挖,需要提前好好准备。 项目执行有遇到什么困难,如何解决,有什么启示。认为自己最匹配需
-
在Jenkins作业的另一个Jenkins实例上运行Jenkins作业
问题内容: 我想创建一个Jenkins作业来启动其他Jenkins作业。那将非常容易,因为Jenkins模板项目插件允许我们创建一个类型为“使用来自另一个项目的构建器”的构建步骤。但是,使我的情况更难的是,我必须在其他计算机上开始Jenkins的工作。有什么标准方法可以做到吗? 问题答案: 万一您只想触发Job的新版本,您有多种方法可以完成它 您可以使用远程访问API并触发请求以从源Job构建目标
-
Hadoop调度作业按顺序运行(一个接一个作业)?
假设我在Hadoop环境中资源有限,我不想安排长时间运行的作业(即需要几天时间才能完成)。我正在分析大量过去的时间序列数据。我想安排一次需要一天数据的mapreduce作业(这需要一个小时来处理)。 那么,我如何安排,使新的工作提交后,前一个工作完成?
-
加载Jenkins作业配置页面很慢,没有运行作业
目前,当我们试图打开Jenkins配置页面时,大约需要45秒,而对于其他页面,如请求作业视图或查看控制台输出,则不到3秒。根据线程转储分析结果,我们得到了一个CPU“峰值”,描述为 "您的应用程序可能受到高CPU的困扰。"查看线程报告,我们没有看到任何阻塞状态,但有一个可疑状态:"1个线程是无限循环:DestRoyJavaVM" 不幸的是,我们无法确定这种高CPU的原因,可能还有相关的无限循环。
-
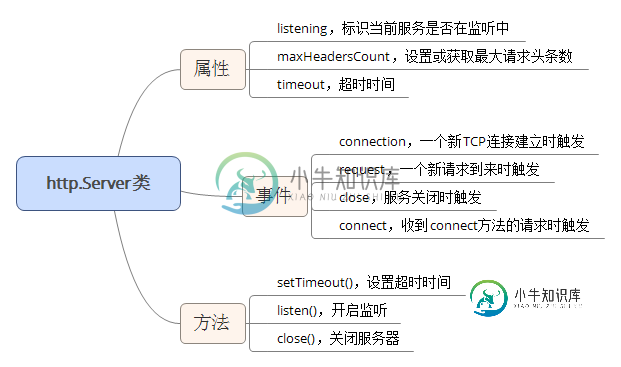 nodejs利用http模块实现银行卡所属银行查询和骚扰电话验证示例
nodejs利用http模块实现银行卡所属银行查询和骚扰电话验证示例本文向大家介绍nodejs利用http模块实现银行卡所属银行查询和骚扰电话验证示例,包括了nodejs利用http模块实现银行卡所属银行查询和骚扰电话验证示例的使用技巧和注意事项,需要的朋友参考一下 http模块内部封装了http服务器和客户端,因此Node.js不需要借助Apache、IIS、Nginx、Tomcat等传统HTTP服务器,就可以构建http服务器,亦可以用来做一些爬虫。下面简单介
-
如何在AWS设备农场中获得更细粒度的测试结果?[鸦片node.js]
我在AWS设备农场上运行Appiumnode.js测试。我想在设备农场中显示粒度测试结果,但是我总是得到一个包含所有测试的“测试套件”结果。因此,如果一个小测试失败,整个测试套件就会失败。我在设备农场文档中读到,在标准环境中会显示更细粒度的结果,但我不确定如何切换或使用标准环境。我认为它与YAML文件有关,因为在设备场用户界面上不再提供在标准或自定义环境之间进行选择的可能性。 这是我当前的YAML