《同花顺》专题
-
同一组下不同分区上的Kafka消费者仍然间歇地消费相同的消息
我有1个消费者群体和5个消费者。也有5个分区,因此每个消费者得到1个分区。 CLI还显示 bin/Kafka-console-consumer . sh-bootstrap-server localhost:9092-Topic Topic-1-from-beginning-partition { n }正确显示每个分区的不同消息。 然而,我经常看到两个或两个以上的消费者在处理同一条信息,而且对于
-
火花有多少JVM运行在带有多个应用程序的worker上
spark.executor.cores=2 spark.executor.memory=10GB 现在Spark在每个worker节点上启动一个Executor的JVM,对吗? 然后,在第一个会话使用configs进行之前,启动另一个Spark应用程序/会话 JVM的开销有多大?我的意思是,在用例2中,节点的RAM被分成7个JVM时,有多少RAM不会用于计算目的?
-
从Kafka主题读取数据并使用scala和火花写回Kafka主题
嗨,我正在阅读kafka主题,我想处理从kafka接收到的数据,例如tockenize,过滤掉不必要的数据,删除停用词,最后我想写回另一个kafka主题 然后我得到以下错误 线程"main"中的异常org.apache.spark.sql.Analysis Exception:具有流源的查询必须使用WriteStream.start()执行; 然后,我对代码进行了如下编辑,以从Kafka中读取并写
-
在ubuntu上启动一个Spring Boot应用程序,但花费太多时间
当我在Windows10上(在IDE内)启动我的Spring Boot应用程序时,我可以在Chrome中键入url,并立即获得我想要的东西。 然而,当我在ubuntu服务器上启动它时,它将需要10分钟甚至半小时才能工作。我看没必要这样,想把它剪了。 (但是当我启动它时,我可以看到“started Application in 18.193 seconds(JVM running for 19.08
-
Spark结构化流应用程序将空拼花文件生成到Azure blob
我正在读取来自Apache Kafka的json消息,然后使用Apache Spark在Azure blob存储中编写拼花文件。我使用方法partitionBy将这些拼花地板文件写入嵌套文件夹中。我的代码如下: 我注意到火花应用程序会产生空的镶木地板文件。这对我来说是一个瓶颈,因为我在hive导入过程中读取了这些镶木地板文件,并且抛出了一个异常,即这不是镶木地板文件(长度太小:0) 一般来说,我想
-
使用附加写入模式将新数据写入现有拼花文件
我正在使用下面的代码片段来保存数据。它只会在同一分区文件夹下创建一个新的拼花地板文件。是否有任何方法可以将数据真正附加到现有的拼花地板文件中。所以,如果一天中有许多附件,我们就不会有多个文件? <代码>测向。聚结(1)。写模式(“追加”)。partitionBy(“paritionKey”)。拼花地板(“…\parquet\u file\u folder\”) 非常感谢你的帮助。
-
Excel ODBC数据连接查询刷新每个查询所花费的时间
问题内容: 我正在尝试测试从Excel数据连接运行的查询的三种变体。 我有三个单独的数据连接和三个单独的选项卡,它们分别从每个连接获取数据。 每个查询的连接字符串相同,只有命令文本(Oracle SQL)不同。 Excel中是否可以查看每个查询的执行时间? 我专门使用版本 问题答案: 可能是这样的事情(假设所有连接都将其结果放置在工作表中,而不是在数据透视表中): 要运行此命令: +转到VBA编辑
-
在Azure HDInsights中从分区拼花文件创建配置单元外部表
我错过了什么?
-
如何将数据集[行]保存为火花中的文本文件?[重复]
我想将数据集[行]保存为文本文件,并在特定位置使用特定名称。有人能帮我吗? 我已经试过了,但这会产生一个文件夹(LOCAL\u folder\u TEMP/filename),其中包含一个拼花文件:Dataset。写保存(LOCAL\u FOLDER\u TEMP filename) 谢谢
-
如何在删除 blob 时删除存储在雪花中的 Blob 的内容
我正在构建一个数据管道,我使用了一个azure函数,当blob(一个json文件)被上传到azure容器时触发,然后将数据生成到kafka中,json数据最终将存储在snowflake中。当有人从容器中删除blob时,是否有任何方法可以获取blob的内容,以便我也可以从snowflake中删除已删除blob的属性?我曾考虑使用eventhub,但我对它不太熟悉。
-
为什么列表初始化(使用花括号)比其他选项更好?
为什么?
-
swagger2和SpringMVC的问题-运行应用程序需要花费大量时间
我目前正在使用Springfox Swagger2来提供API UI(Swagger-UI),并使用Java配置来记录我的spring mvc应用程序。要启动我的API,最初需要大约90秒,整个扫描过程。我的项目中大约有12-15个模块和100个控制器,它是一个基于servlet的桌面应用程序 我目前只需要控制器信息,而不需要任何型号信息。我已经从启动过程中排除了模型扫描,以便启动我的API,但它
-
火花内部-重新分区是否加载内存中的所有分区?
我在任何地方都找不到如何在RDD内部执行重新分区?我知道您可以在RDD上调用重新分区方法来增加分区数量,但它是如何在内部执行的呢? 假设,最初有5个分区,他们有- 第一个分区 - 100 个元素 第二个分区 - 200 个元素 第 3 个分区 - 500 个元素 第 4 个分区 - 5000 个元素 第 5 分区 - 200 个元素 一些分区是倾斜的,因为它们是从HBase加载的,并且数据没有正确
-
火花下推过滤器如何与cassandra表非分区键一起工作?
我在cassandra中有一个表,其中日期不是分区键的一部分,但它是聚类键的一部分。在读取火花中的表时,我正在应用日期过滤器,它正在向下推送。我想了解下推是如何工作的,因为通过cql,我们不能直接查询集群键。数据是否在某处被过滤? Java实施: 物理平面图显示为 类型,那么即使date是分区键的一部分,也不会推送过滤器。我不得不把它写成< code>transactions.filter("da
-
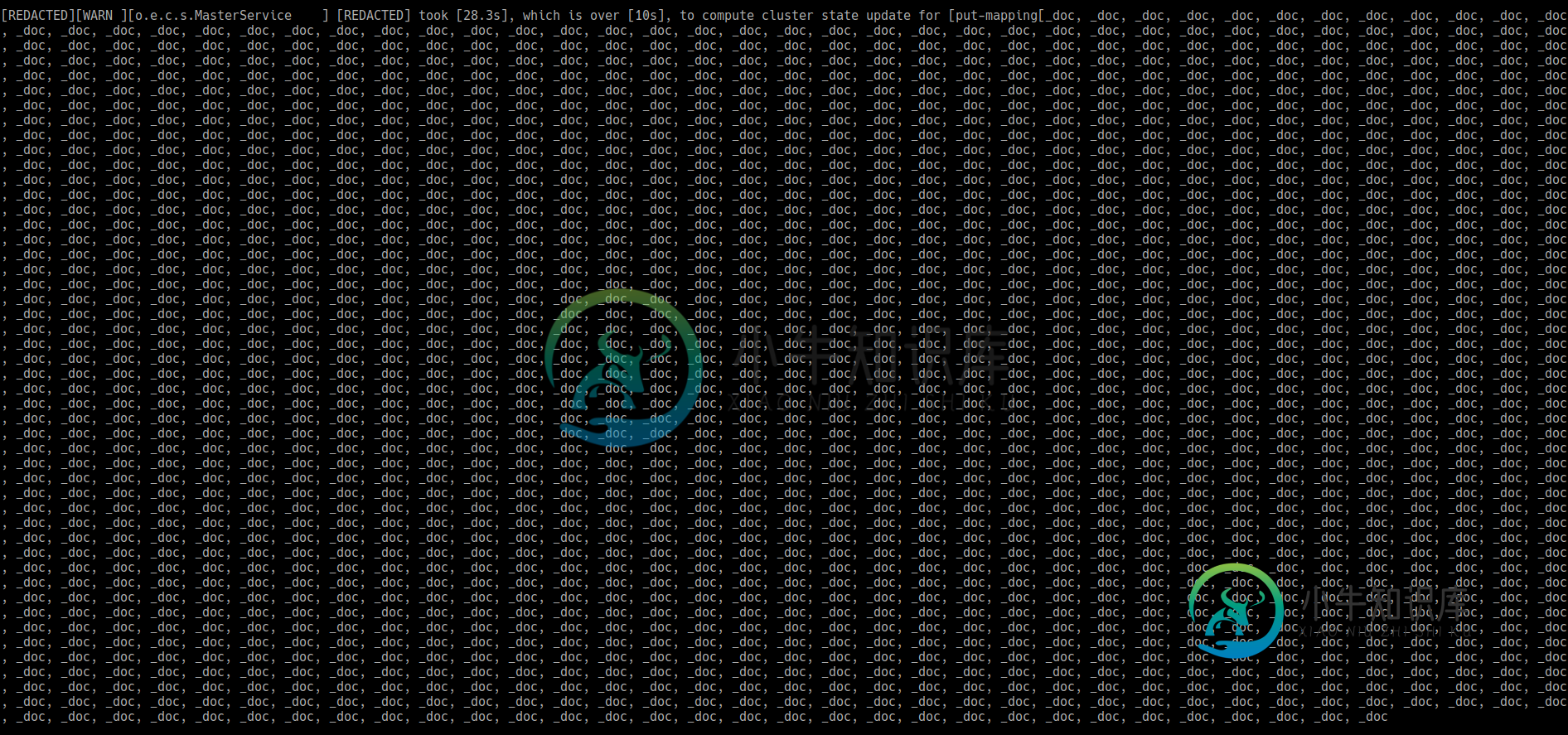 ElasticSearch的MasterService计算集群状态花费的时间太长,并引发ProcessClusterEventTimeoutException
ElasticSearch的MasterService计算集群状态花费的时间太长,并引发ProcessClusterEventTimeoutException我们有一个应用程序,每秒向 ES 集群添加数千个文档。每次滚动更新要写入的索引并开始写入新索引时,都会收到以下错误,这些错误不允许在大约 1 分钟内引入文档。在那 1 分钟之后,一切都恢复正常,直到我们再次滚动索引。 在第一行中,我在末尾加了省略号,因为它实际上相当大,这里是我们看到的图像(如图所示,行突然结束): 你知道这些错误消息是关于什么的吗? 我们是否可能因为集群状态太大而看到这些消息?这