《join》专题
-
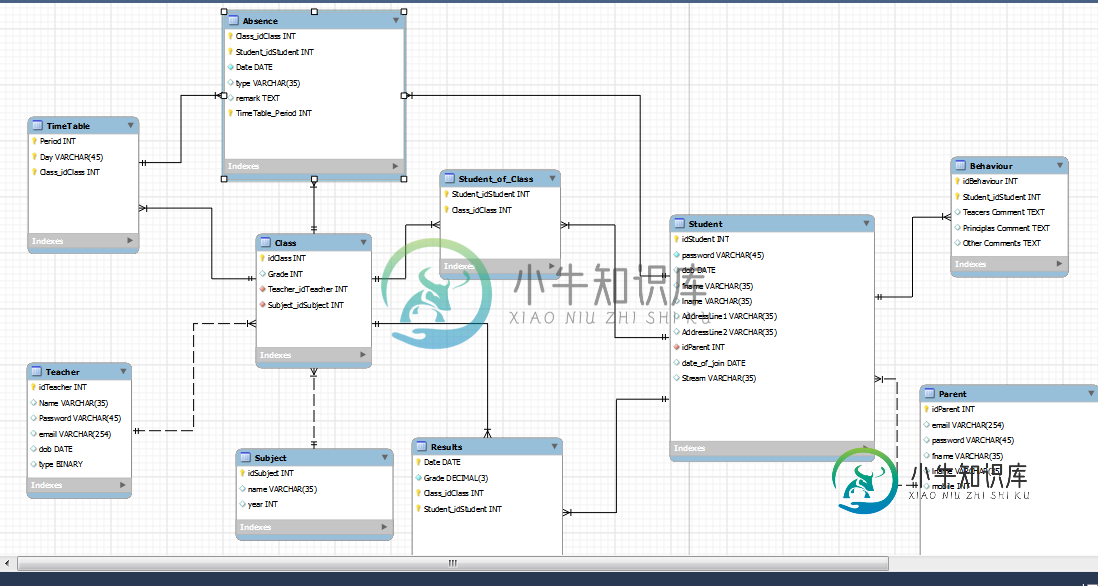 自动生成实体类的Netbeans@JoinColoumns错误
自动生成实体类的Netbeans@JoinColoumns错误我已经使用Netbeans 7.4从数据源创建了实体。 我有一个错误,它发生在所有具有复合主键的实体上。错误如下所示。 我已经在堆栈溢出上搜索了这个问题,这通常是因为人们没有定义连接列。但我已经这样做了。我也不确定netbean生成的代码中如何存在错误。 这是我的MySQL数据库的一个图像,我将其向前设计以创建这些实体: 任何帮助都将不胜感激! 这是唯一相关的代码 缺勤实体: 缺勤PK实体: 错误
-
在SpringBoot中设置一对一关系失败,@JoinColumns(Column不存在)
我有表,我不会翻译数据库对象,因为ORM可能使用命名约定。 科雷托尔 当我尝试使用findById时,我得到:org.PostgreSQL L.util.psqlException:error:casavenda0_1_.id_anunciante列不存在提示:也许您是想引用“casavenda0_.id_anunciante”列。
-
什么时候应该使用STD::Thread::Joinable?
如果->get_id()==std::this_thread::get_id()(检测到死锁),resource_deadlock_would_accurt 这种方法的唯一目的是检测这样的情况吗?我们目前厚颜无耻地只调用thread->join,而没有一个可接合的包装器,这样的方法有什么危险?
-
防止GroovyDefaultMethods join()隐藏Java类的join()方法?
这很奇怪返回一个:https://static.javadoc.io/tech.tablesaw/tablesaw-core/0.32.6/tece/tablesaw/api/table.html#join-java.lang.String...- 我认为,是一个,所以也许Groovy正在使用它自己的join方法。 真正奇怪的是,如果我将Tablesaw版本从切换到,即使也在该版本中实现了 知道如
-
JPA(带Hibernate)@ManyTomany@Jointable relationship cascade
为了使问题变得简单,让我们假设我有一个具有三个属性的用户实体:id、email和一组角色(owner、@manytomany、@jointable)。我将合并至少具有一个或多个角色用户实体,而不通过EntityManager查找它: 数据库中的结果是:
-
AppendStreamTableSink不支持使用节点Join产生的更新更改(joinType=[InnerJoin]
当我使用Flink SQL执行以下语句时,错误报告如下: 请求 根据< code>user_id字段对user_behavior_kafka_table中的数据进行分组,然后取出每组中< code>ts字段值最大的数据 Excute sql Flink 版本 1.11.2 错误消息 作业部署 在纱线上 表消息 < li >来自消费者kafka主题的user_behavior_kafka_table
-
两个流之间的 Scala Flink Join 不起作用
我想加入来自 kafka producer 的两个流,但该连接不起作用。我使用 AssignerWithPeriodicWatermark 来定义我的分配器,我尝试使用 3 分钟的窗口连接两个流。但我没有得到任何输出。我打印了这两个流,以确保它们的事件在时间上足够接近。
-
Apache Flink中Join的输出
在Apache Flink中,如果我在一个主键上连接两个数据集,我会得到一个元组2,其中包含每个数据集中相应的数据集条目。 问题是,当将方法应用于即将到来的tuple 2数据集时,它看起来并不漂亮,尤其是如果两个数据集的条目都具有大量功能。 在两个输入数据集中使用元组会给我一些这样的代码: 我不介意使用POJO或case类,但我不明白这会如何使它变得更好。 问题1:有没有一个很好的方法来扁平化元组
-
 Hibernate@joincolumns,可插入 true 不允许插入
Hibernate@joincolumns,可插入 true 不允许插入我有两个表,它们的关系如下图所示 我创建了Hibernate数据模型,如下所示 我打算创建如下实体 当我运行这个时,我得到以下错误 org.hibernate.MappingException:实体映射中的重复列:*。SSI 列:CLIENT_ID(应使用 insert=“false” update=“false”进行映射) 如果我设置为CLIENT_ID,它将再次错误关于插入的混合 如果我为所有
-
Spring Data JPA如何在使用get("property") chain vs Join时指定连接类型或获取模式
我有两个(基于Hibernate的)Spring Data JPA域类,“One”侧Customer.class: 和“许多”侧顺序.class: 我有OrderRepository接口,它扩展了JpaRepository接口和JpaSpecificationExecitor接口: 我有一份订单说明书。使用静态方法<code>searchByCustomerName</code>初始化: 为了找到
-
Java线程,join()耗时太长?
所以我有一些代码,我在我的主线程中创建了6个线程,它们运行一些代码。我启动线程。然后我在线程上调用,以便主线程在继续执行之前等待它们全部死亡。 现在,我正在使用一些非常基本而且很可能不准确的方法来衡量代码运行的时间。只需调用以获取开始和结束时的系统时间,然后打印差异。 比方说,运行我的所有代码大约需要500毫秒。 我决定删除每个线程对的调用,而是让我的主线程睡眠20毫秒。这导致我的代码在大约200
-
Spring Data@JoinColumn和实体更新
问题陈述 我有以下实体: 如果更新,我希望更新对象。例如,我使用我希望对象是id为的对象 更新并使用保存对象,并将当前的对象替换为保存在数据库中的新的对象 失败,因为未从数据库中提取对象 这个也失败了。
-
如何在单分区kafka主题上运行多个应用程序实例的ktable-ktable-joins-kafka streams应用程序?
对于我的应用程序,我使用KTable-Ktable连接,这样无论何时在主数据流或子数据流上接收数据,它都可以为所有三个表设置带有setters和getters的复合对象。这三个传入流具有不同的键,但是在创建KTable时,我为所有三个KTable设置相同的键。 我有一个分区的所有主题。当我在单个实例上运行应用程序时,一切都运行良好。我可以看到compositeObject填充了所有三个表中的数据。
-
JoinColumn注释在同一个表上创建列
我是Hibernate的新手,正在尝试学习它。我对@JoinCol列的用法感到困惑。我知道它创建了一个列来关联两个实体。我尝试过的是: 有两个阶级的人和房子 个人阶级有一套与一个家庭有关系的房子 当面授课: 这将在表上创建一个名为的列。 内部课程: 这将在表上再次创建列。但我希望能在表上看到这个专栏。为什么会这样? 我在想@JoinColumn annotation会在表上创建一个连接列,这就是我
-
可分页+@query+JOIN(fetch?)在Spring数据不起作用
我试图通过使用Spring Data中的注释,将排序与集成在联接字段上。 有人建议将添加到参数中,以便在某种程度上与分页(spring data jpa@query和pagable)相对应 我已经学习了Baeldung的教程,但这不包括联接 Spring-Data FETCH JOIN与分页不起作用也建议使用,但我更喜欢使用,而不是. 我将在下面留下一些代码示例。如果我遗漏了一些重要的东西,请随时