《负载均衡》专题
-
http负载平衡器和运行状况检查
我发现了这个问题。。 您希望使用最少的步骤为在多个区域中运行的一组计算引擎实例配置网络负载平衡的自动修复。如果VM在3次尝试后无响应,则需要配置VM的重新创建,每次10秒。你应该怎么做? A、 使用引用现有实例组的后端配置创建HTTP负载平衡器。将运行状况检查设置为健康(HTTP) B、 使用引用现有实例组的后端配置创建HTTP负载平衡器。定义平衡模式并将最大RPS设置为10。 C.创建托管实例组
-
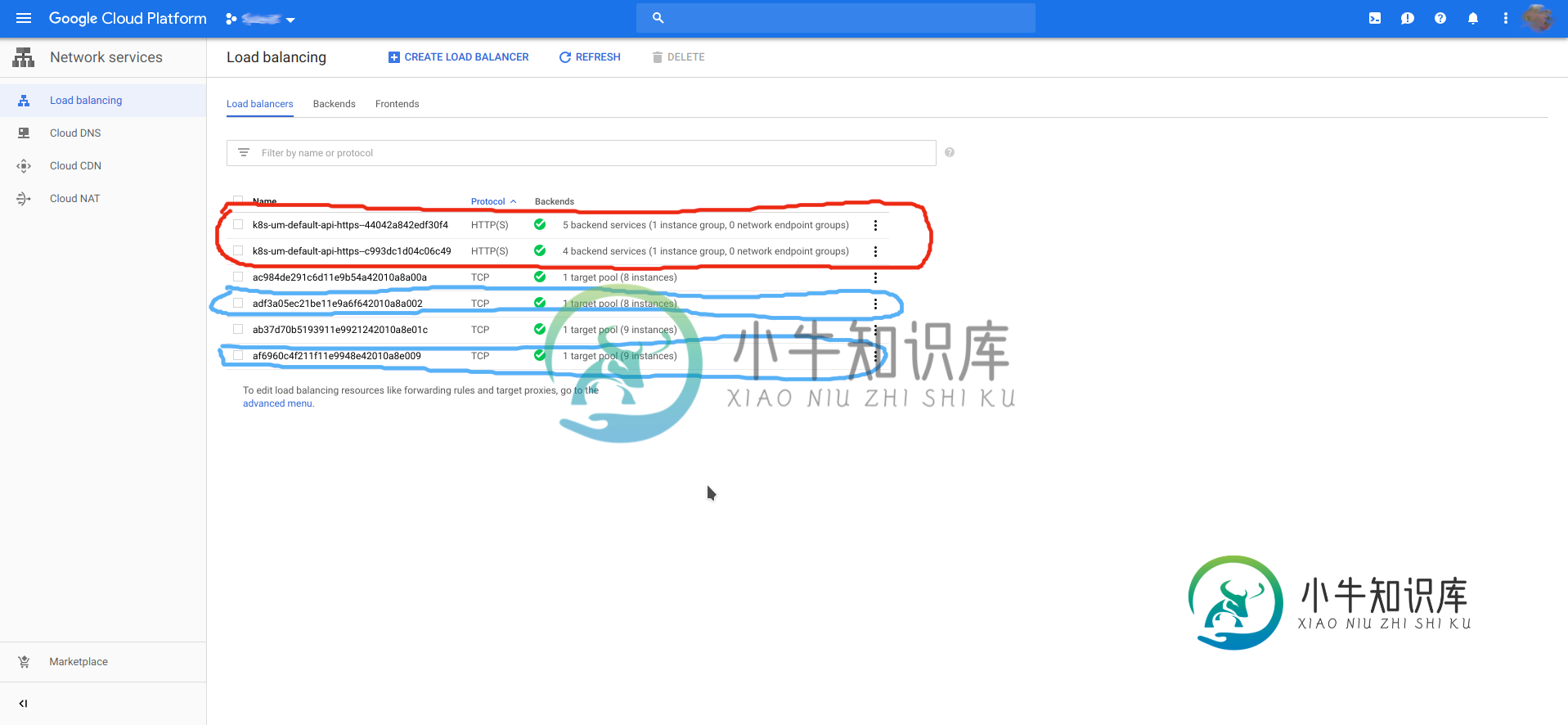 gke nginx ingress创建额外的负载平衡器
gke nginx ingress创建额外的负载平衡器有一个入口配置,比如 gke创建了nginx ingress负载平衡器,但也创建了另一个具有后端的负载平衡器,就像如果没有选择nginx,而是选择gcp作为ingress一样。 下面的屏幕截图以红色显示了两个意外的LB,蓝色显示了两个nginx ingress LB,分别用于我们的qa和prod env。 kubectl的输出获取服务 gcp gke服务视图中错误信息入口的屏幕截图 这是意料之中的
-
谷歌云负载平衡健康检查重置
Google容器引擎(kubernetes) 使用我的Web服务器应用程序(Torando/python)部署/pod kubernetes中Web服务器服务的入口-它在GCP中创建了负载均衡器 负载均衡器中的后端服务,后端是Web服务器 指向后端服务器的前端 将自定义域和子域引导到相关后端的主机和路径规则 防火墙规则设置为由入口创建 当我创建上述所有内容时,我使用正确的端口和所有内容创建了一个新
-
使用负载平衡器终止Kafka/SSL连接
我们有两个Kafka节点,出于本问题范围之外的原因,我们希望设置一个负载平衡器来终止生产者(客户端)的SSL。负载平衡器托管的SSL证书将由客户端本机应信任的受信任/根CA签名。 所以连接看起来像: 这是否可行,或者Kafka是否以某种方式要求直接在Kafka服务器上设置SSL? 谢谢
-
应用程序负载平衡器(ELBv2)SSL直通
我正在尝试配置AWS应用型负载均衡器(与经典负载均衡器相比)以将流量分配到我的EC2 Web服务器。出于合规性原因,我的应用程序需要端到端SSL/HTTPS加密。 在我看来,确保在客户端和web服务器之间的整个过程中对流量进行加密的最简单方法是终止web服务器上的HTTPS连接。 我的第一个问题:是否可以通过AWS应用程序负载平衡器将HTTPS流量以这种方式传递到负载平衡器后面的web服务器? 根
-
WSO2 ESB动态负载平衡endpoint平衡算法
我使用的是WSO2 470 ESB。我需要使用一个提供自定义负载平衡策略的动态负载平衡endpoint。我知道WSO2是基于apache Synapse的,在此基础上我可以找到以下内容: http://synapse.apache.org/userguide/config.html#dlbendpointconfig 真的吗?是否可以通过我自己的类自定义平衡策略?
-
Python-均线或均线
问题内容: 是否有python的scipy函数或numpy函数或模块来计算给定特定窗口的一维数组的运行平均值? 问题答案: 对于一个简短,快速的解决方案,它可以在一个循环中完成所有事情,而没有依赖关系,下面的代码效果很好。
-
如何使用代理协议版本2通过AWS网络负载均衡器获取客户端的真实IP地址?
目前,我们正在通过AWS网络负载平衡器将请求传递给AWS应用程序负载平衡器。然而,我们正试图保留请求的原始IP地址,但这正在被剥离。我们正在尝试启用代理协议v2,但这会导致错误。AWS ALB是否使用代理协议v2?
-
很大的JTable,RowFilter和额外的负载
问题内容: 我想要求澄清有关RowFilter的使用及其对性能的影响。我通过方法include(Entry)实现了一个过滤器,该过滤器针对每行仅检查模型中其对应值是否设置了布尔标志:如果是,则返回true,否则返回false。 现在,我拥有的JTable可能非常大(超过1000000行),而且我不确定应用于这种大输入集的这种简单过滤是否会很昂贵。 过滤后的行与基础数据之间的映射如何正确工作?我的意
-
哈希图的负载因子和容量
问题内容: 如何找到哈希表的当前负载率和容量? 问题答案: 您不应该能够获得负载系数和容量。它们是hashmap类的实现细节。但是,您可以使用反射。尽量避免使用它,但这通常是一个坏主意。
-
Jmeter动态生成请求的JSON负载
问题内容: 我有一个Jmeter测试计划,希望我的HttpSampler发送一个发布请求。 请求的正文应包含Json,如下所示: 我已经设置了一个随机变量生成器,该变量生成器在每次调用时都返回格式正确的productId。我想做的是通过直接在请求主体中填充从生成器获取的随机pid的productId来生成有效负载。像这样(假设***是脚本转义符): 可能吗?如果是,怎么办?如果没有,您将如何处理该
-
CodeIgniter:控制器内的负载控制器
问题内容: 我有一个控制器,该控制器的操作可以显示一组特色产品。但是,产品是通过包含专有模型和视图的控制器进行管理的。 如何从控制器中的操作中访问信息?实例化无法运行,因为该类未在运行时加载,并且CodeIgniter也未提供动态加载控制器的方法。将类放入库文件中实际上也不起作用。 确切地说,我需要在索引视图中插入产品视图(填充有控制器处理的数据)。我正在运行CodeIgniter 2.0.2。
-
Spring BootREST读取JSON数组有效负载
我有这个邮戳方法 我使用下面的JSON负载来提出我的帖子请求: 这将返回以下内容: “消息”:“JSON解析错误:无法反序列化超出起始\u数组标记的实例;嵌套异常为com.fasterxml.jackson.databind.exc.MismatchedInputException:无法反序列化超出起始\u数组标记的实例\n位于[源:(PushbackInputStream);行:1,列:1]“,
-
在Django中提供大文件(高负载)
问题内容: 我一直在使用一种提供下载服务的方法,但是由于它不安全,所以我决定对此进行更改。(该方法是到存储中原始文件的链接,但是风险是每个知道链接的人都可以下载该文件!)因此,我现在通过我的视图提供文件,这样,只有拥有权限的用户才能下载文件,但是我注意到服务器上的负载很高,同时有许多文件同时下载请求。这是我为用户处理下载的代码的一部分(考虑文件是图像) 在保持安全性并降低服务器端负载的情况下,有没
-
Spark 2.4 CSV负载问题,选项为“nullvalue”
我们以前使用过Spark 2.3,现在使用的是2.4: 我们在生产中运行了一段代码,将csv文件转换为拼花格式。我们设置csv加载的选项之一是option(“nullValue”,null)。spark 2.4中的工作方式有问题。 这里有一个例子来说明这个问题。 让我们创建以下/tmp/test。csv文件: 结果更糟: 这是新版Spark 2.4.0中的错误吗?任何机构都面临类似的问题吗?