《集合》专题
-
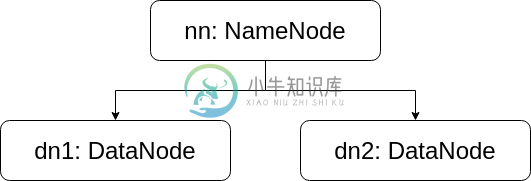 5.0 HDFS 集群
5.0 HDFS 集群主要内容:部署集群HDFS 集群是建立在 Hadoop 集群之上的,由于 HDFS 是 Hadoop 最主要的守护进程,所以 HDFS 集群的配置过程是 Hadoop 集群配置过程的代表。 使用 Docker 可以更加方便地、高效地构建出一个集群环境。 每台计算机中的配置 Hadoop 如何配置集群、不同的计算机里又应该有怎样的配置,这些问题是在学习中产生的。本章的配置中将会提供一个典型的示例,但 Hadoop 复
-
 HTML 字符集
HTML 字符集主要内容:HTML 字符集,在开始的时候:ASCII,在 Windows 中:ANSI,在 HTML 4 中:ISO-8859-1,实例,在 HTML5 中:Unicode(UTF-8)要正确显示一个 HTML 页面,浏览器必须知道要使用的字符集(字符编码)。 HTML 字符集 在 HTML 中,正确的字符编码是什么? HTML5 中默认的字符编码是 UTF-8。 这并非总是如此。早期网络的字符编码是 ASCII 码。 后来,从 HTML 2.0 到 HTML 4.01,ISO-8859-1 被
-
 Spring集成AspectJ
Spring集成AspectJ主要内容:AspectJ Jar 包下载我们知道,Spring AOP 是一个简化版的 AOP 实现,并没有提供完整版的 AOP 功能。通常情况下,Spring AOP 是能够满足我们日常开发过程中的大多数场景的,但在某些情况下,我们可能需要使用 Spring AOP 范围外的某些 AOP 功能。 例如 Spring AOP 仅支持执行公共(public)非静态方法的调用作为连接点,如果我们需要向受保护的(protected)或私有的(
-
 集度面经
集度面经集度一面 9.22(90min) 1.自我介绍 2.项目介绍 3.项目难点介绍和如何解决的 4.集合的了解 5.使用for循环对ArrayList在遍历的时候进行删除会有什么问题。(i是累加的,但list的长度是变短的,会导致有些元素不会被遍历到)。 6.使用Iterator对List集合进行删除操作时会报什么异常 7.Iterator底层原理实现。 8.ThreadLocal的理解 9.Thre
-
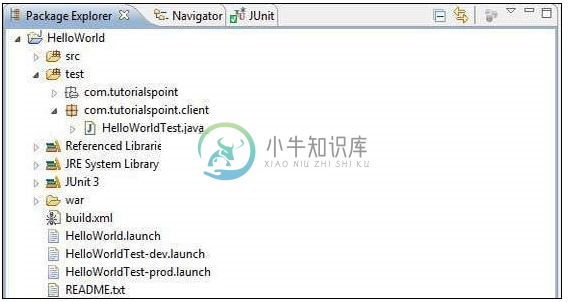 GWT Junit集成
GWT Junit集成主要内容:GWT Junit集成 示例,使用生成的启动配置在 Eclipse 中运行测试用例GWT Junit集成 示例 以下将是eclipse中的项目结构。 以下是修改后的模块描述符src/cn.xnip/HelloWorld.gwt.xml 的内容。 以下是修改后的样式表文件war/HelloWorld.css 的内容。 以下是修改后的 HTML 主机文件war/HelloWorld.html 的内容。 将src/cn.xnip/client包中的 HelloWorld.java 内
-
PyTorch数据集
在本章中,将更多地关注及其各种类型。PyTorch包括以下数据集加载器 - MNIST COCO (字幕和检测) 数据集包括以下两种函数 - - 一种接收图像并返回标准内容的修改版本的函数。这些可以与变换一起组合。 - 获取目标并对其进行转换的函数。例如,接受标题字符串并返回索引张量。 MNIST 以下是MNIST数据集的示例代码 - 参数如下 - - 存在已处理数据的数据集的根目录。 - =训练
-
JDBC结果集
主要内容:ResultSet类型,ResultSet的并发性,浏览结果集,查看结果集,更新结果集SQL语句执行后从数据库查询读取数据,返回的数据放在结果集中。 语句用于从数据库中选择行并在结果集中查看它们的标准方法。 接口表示数据库查询的结果集。 对象维护指向结果集中当前行的游标。 术语“结果集”是指包含在对象中的行和列数据。 接口的方法可以分为三类: 浏览方法:用于移动光标。 获取方法:用于查看光标指向的当前行的列中的数据。 更新方法:用于更新当前行的列中的数据。 然后在基础数据库中更新数
-
SpringMVC集成Fastjson
主要内容:1 XML配置方式,2 注解方式如果你使用 Spring MVC 来构建 Web 应用并对性能有较高的要求的话,可以使用 Fastjson 提供的FastJsonHttpMessageConverter 来替换 Spring MVC 默认的 HttpMessageConverter 以提高 @RestController @ResponseBody @RequestBody 注解的 JSON序列化速度。下面是配置方式,非常简单。
-
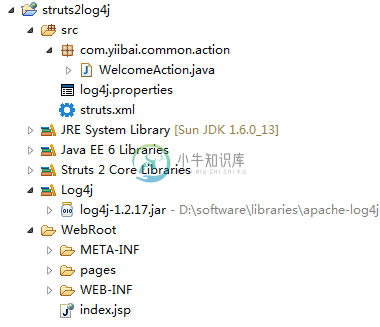 Struts2+Log4j集成
Struts2+Log4j集成主要内容:1. 工程结构,2. log4j.properties,4. Struts2 Action 和 Logging,5. Struts2配置,6. 实例测试在本教程中,我们学习如何将log4j框架在Struts2的Web应用程序集成。所有需要做的有: 包含 log4j.jar 作为项目依赖 创建一个 log4j.properties 文件,并把它放入 classpath 的根目录-放到资源文件夹中。 相关技术和工具的使用: Log4j 1.2.17 Struts 2.1.8 Tomcat
-
 欢聚集团
欢聚集团9.1 一面 (1h) 自我介绍+实习经历 js基本数据类型以及类型判断方法 为什么 typeof null==object以及typeof原理 flex布局以及常见的display有哪些 行内元素与行内块元素 触发回流(reflow)的条件以及改变font-size会发生什么 object与map区别 promise相关以及常见方法 垃圾回收机制以及内存泄露解决方案 浏览器有哪些进程,针对于不同
-
 集度前端
集度前端9.13 面了一个小时多点 从css,js,vue,webpack,git都问了一遍 忘了录音,几个记得的问题: 手写深拷贝考虑循环引用 webpack构建流程 vue原理 script defer async属性 vue2和vue3的diff算法区别 git rebase,git reset css的BFC,transition, 事件循环 宏任务,微任务(判断代码输出) async await
-
Storm 集成 Kafka
一、整合说明 Storm 官方对 Kafka 的整合分为两个版本,官方说明文档分别如下: Storm Kafka Integration : 主要是针对 0.8.x 版本的 Kafka 提供整合支持; Storm Kafka Integration (0.10.x+) : 包含 Kafka 新版本的 consumer API,主要对 Kafka 0.10.x + 提供整合支持。 这里我服务端安装的
-
持续集成
我们做的还不够好,先占个坑。 欢迎贡献章节。
-
数据聚集
概述 MongoDB可以执行数据聚合,比如按指定Key分组,计算总数,求不同分组的值。 使用aggregate()方法执行一个基于步骤的聚合操作(类似于Linux管道)。aggregate()接收一个步骤数组成为它的参数,每个步骤描述对数据处理的操作。 db.collection.aggregate( [ <stage1>, <stage2>, ... ] ) 按字段分组并计算总数 使用$grou
-
4.3.3 并查集
一、并查集的介绍 并查集(Union/Find)从名字可以看出,主要涉及两种基本操作:合并和查找。这说明,初始时并查集中的元素是不相交的,经过一系列的基本操作(Union),最终合并成一个大的集合。 而在某次合并之后,有一种合理的需求:某两个元素是否已经处在同一个集合中了?因此就需要Find操作。 并查集是一种 不相交集合 的数据结构,设有一个动态集合S={s1,s2,s3,.....sn},每个