《反射》专题
-
神经网络反向传播和偏见
我很难构建好的神经网络教学算法,因为有一些人工操作。第一件事:我的目标是教nn-xor函数,我使用sigmoid作为激活函数和简单的梯度下降。前馈很容易,但backprop在某种程度上令人困惑——大多数算法描述中常见的步骤有:1。计算输出层上的错误。2、将此错误传播到有关权重3的隐藏层。更新突触上的权重 所以我的问题:1。偏差也应该更新吗?如果是,如何更新?目前我随机选择偏差[0.5;1]?2.在
-
quarkus反应性兵变线程池管理
背景:本周我刚刚开始学习Quarkus,尽管我以前使用过一些流媒体平台(特别是scala中的http4s/fs2)。 工作与夸克斯反应性(与兵变)和任何反应性数据库客户端(兵变反应性postgres,反应性elasticsearch,等)我有点困惑如何正确管理阻塞调用和线程池。 quarkus文档建议使用注释命令式代码或cpu密集型代码,以确保将其转移到工作池以不阻塞IO池。这是有道理的。 考虑以
-
Java jackson如何反序列化为日期
无法从字符串“1979-12-05T08:00Z”反序列化java.util.Date类型的值:无效表示(错误:无法分析日期值“1979-12-05T08:00Z”:无法分析日期“1979-12-05T08:00.000Z”:虽然它似乎符合格式“yyyy-mm-dd't'hh:mm:ss.sss'z'',但分析失败 到目前为止,我试图包含这种依赖关系: 还有: 但没有奏效。
-
反应:“PrevState”和“=>”的代码解释[重复]
我是一个新手,需要做出反应并尝试更好地理解java脚本代码。 我使用了下面的代码,它工作正常:基本上,当用户输入某个内容时,该函数将采用“description”的先前状态,并使用新值更新“description”。 然而,我不太明白这是如何在代码中完成的,我希望得到一个解释(特别是关于"= 我还想用
-
反应-无法在promise内设置状态
我试图在promise的内设置状态,但状态值未保存,在then()外无法访问。 以下是更新后的代码: 如果我我得到一个值。但是,如果我console.log在那么()块,我得到正确的值。在这种情况下如何设置状态? 更新的说明: 为了给整个逻辑提供更好的上下文:我使用了一个GooglePlacesAutoComplete组件,它允许用户从下拉列表中选择一个位置。当用户从下拉列表中选择位置时,将调用上
-
反应路由器“#在路线内签名”
我在我的项目中使用react router,因为每个路由都有一个问题,在每个路由器路径的开始处都添加了“#”符号。。例如:http://localhost:3000/#/login 我想去掉那个标志,但我自己解决不了。 我的路由程序是在app.jsIM检查用户是否登录,如果没有登录,那么他将重定向到 /login页面。( 下面是app.js 否则他将登录,然后我将使用名为DefaultLayout
-
反向外键上的Django级联删除
Django演示了如何设置或覆盖在文档中使用外键的级联删除。 但是如果我们想让这种效果反过来呢?如果我们希望fk模型的删除导致该模型的删除,该怎么办? 谢谢
-
Jackson反序列化classImpl对象的列表
我有一个抽象的超类A,我有几个具体的子类B,C,D 在序列化方面,我执行以下操作: 没问题。我现在想反序列化这个。我知道我不能实例化一个抽象类,那么这是如何实现的呢? 这不起作用: 编辑:我把这个添加到我的抽象超类中:(仍然没有运气) 再次编辑:我现在遇到以下错误: 看看JSON,@class不在那里。我怎样才能做到?我试过: 但这并没有奏效。有这方面的例子吗?如何告诉对象映射器对类使用我的注释?
-
Android-不想反编译我的apk文件
在一些网站上,我读过“使用一些反编译程序反编译apk是可能的”。(即)从apk文件中获取源代码。 但我想保护我的代码。反编译后不显示加密算法代码或者不想反编译我的apk文件。那有可能吗?请你给点建议好吗?
-
NGINX反向代理背后的SpringBoot-API REST
我想在代理之后提供Restful API,但我不知道如何将请求重定向到Spring Boot应用程序,以便可以使用域名访问它。 我的Spring Boot应用程序使用spring-boot-starter-tomcat运行,应用程序部署良好,我可以在服务器上使用java-jar myApplication.jar部署它。 该应用程序还可以通过写入远程访问https://1.2.3.4:8090在浏
-
自定义处理器和反压,节流
NiFi 1.2.0 有一个自定义处理器从db读取数据并进一步传递数据。在最近的一次压力测试中,'success'关系队列被阻塞,后来的流也被阻塞,因为处理器转储了几个GBs的数十万个流文件。显然,反压力没有实施。我还读了一篇关于节流和反压的信息帖子。 在处理器中是否需要额外的编码(例如:要实现的某个接口)以使其能够“Hibernate/停止消耗数据”来进行反压,或者一旦处理器的“成功”关系被配置
-
管理员通过反向代理登录
我正在运行Nginx,它被配置为允许我访问另一台服务器上的几个资源,该服务器可用作反向代理。举个例子 到目前为止一切正常。我在Adminer中输入我的DB用户名和密码,问题就开始了。通过检查管理员登录后返回的标题,我注意到它返回了一个 标题。这就是麻烦的根源。在我的浏览器上,这自然会被解释为相对于当前服务器而不是反向代理的含义。我试图破解管理员代码后,找到了一个地方,它有一个位置头,但这只是阻止了
-
带扩展的反应器延迟分页
基于如何使用Spring引导WebClient收集分页API响应? 我创建了以下爬虫类 我希望避免不必要的请求,但它执行的请求比满足请求所需的多。 只需要一个请求,因为每个页面包含20个条目,但它会启动第二个页面请求。它似乎总是要求多出一页。我尝试使用,但似乎没有效果。 有没有一种方法可以让它变得懒惰,即只有在当前页面用完时才请求下一页?
-
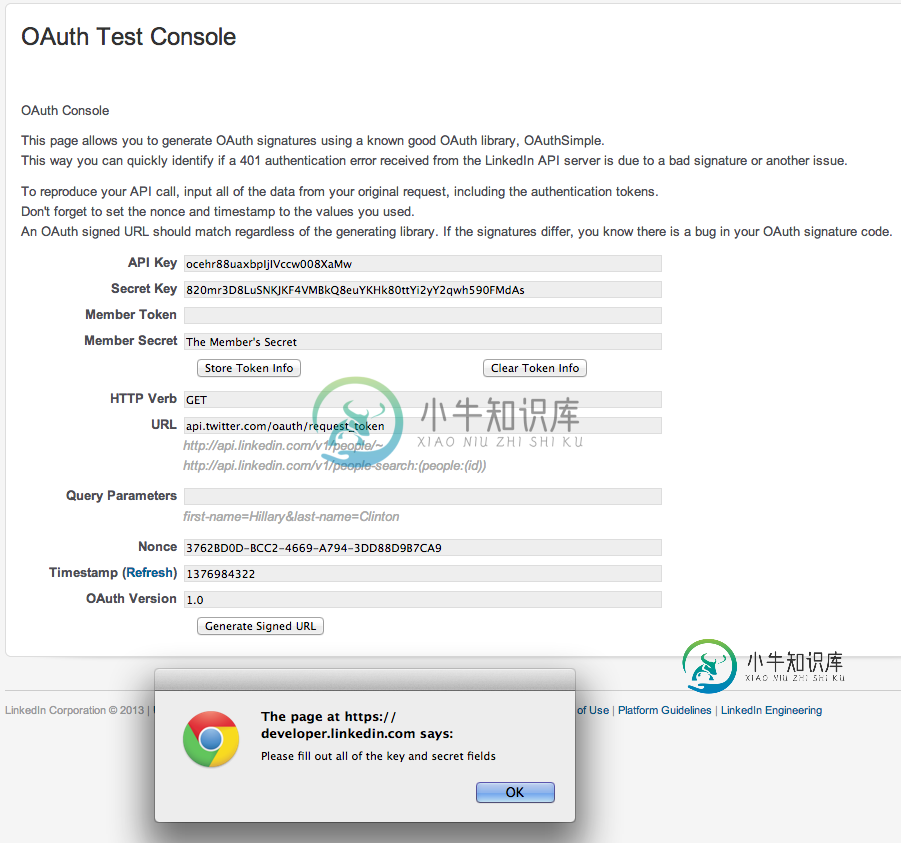 401响应推特反向身份验证
401响应推特反向身份验证这是我使用的授权标头: 以下是我使用的基本字符串: 以下是我的推特文档: 步骤1:获取特殊请求令牌 首先,您使用应用程序的使用者密钥向Twitter请求令牌URLhttps://api.twitter.com/oauth/request_token发出HTTPS请求。除了传统的oauth_*签名参数之外,您还必须包含设置为reverse_auth值的x_auth_mode。 例如,考虑使用令牌秘密
-
Angular 2:迭代反应式表单控件
我想标记中的所有控件。