《jdbc》专题
-
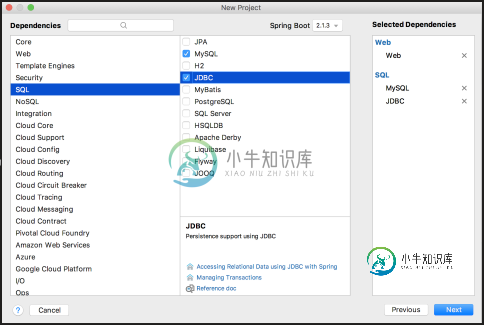 Spring JdbcTemplate整合使用方法及原理详解
Spring JdbcTemplate整合使用方法及原理详解本文向大家介绍Spring JdbcTemplate整合使用方法及原理详解,包括了Spring JdbcTemplate整合使用方法及原理详解的使用技巧和注意事项,需要的朋友参考一下 基本配置 JdbcTemplate基本用法实际上很简单,开发者在创建一个SpringBoot项目时,除了选择基本的Web依赖,再记得选上Jdbc依赖,以及数据库驱动依赖即可,如下: 项目创建成功之后,记得添加Drui
-
Grails 3.3.3 war部署在tomcat 8.5版本上,具有封闭的jdbc连接
当我在容器中运行war文件时,服务器端断开的连接(默认空闲超时为8h)会导致异常(根本原因:连接已关闭/向服务器发送的最后一个成功包是在0ms前发送的,或者是一个表示 问题1)当添加jdbc-tomcat池作为依赖在build.grade运行时"org.apache.tomcat: tomcat-jdbc"重新连接到断开连接的"除了主"数据源(下面的数据源)不尝试.无论这些属性:数据源:poole
-
如何避免与TomEE的JDBC连接池的DB连接停滞?
我正在TomEE1.7.2(通过tomcat7、javaEE6)上创建一个JSF web应用程序。我有JDBC到mysql5.6.23的连接设置,如下所示,它工作得很好,只有几个小时。 我的数据访问超类: 我的数据访问类: 我的META-INF/persistence.xml: 我的WEB-INF/资源。xml: 我有两个问题要解决: 无法永远重新连接mysql。我已经尝试过一些JDBC的auto
-
我可以多次更改JDBC连接的AutoCommit属性吗
我正在处理一个仅使用“autoCommit=true”创建连接的连接池。 然而,对于我的特定用例,我需要“autoCommit=false”,以便可以在JDBC语句上设置“fetch size”属性。 我的初始测试表明,我可以在JDBC连接实例上设置AutoCommit属性,然后在将连接返回到池之前再次重置它。 有人知道这是一个正确的用例吗? 我正在使用Postgres,但稍后可能会迁移到Orac
-
JDBC连接超时无法重新连接
我的Spring Hibernate Web应用程序在MySQL上运行,这给我带来了麻烦。 我四处寻找并尝试了不同的配置,在这个网站上阅读了相当多的帖子,但它仍然会弹出微笑的头像。 错误消息是:由:com.mysql.jdbc.exceptions.jdbc4.通信异常:从服务器成功接收到的最后一个数据包是63,313,144毫秒前。最后一个成功发送到服务器的数据包是63,313,144毫秒前。比
-
tomcat jdbc池最大活动不工作?
我在应用程序中使用spring jdbc模板。。并在tomcat中部署它。。我想在tomcat jdbc中使用连接池。我的连接配置是 我不知道怎么做,但当我运行一些测试,并检查mysql中的最大线程时,它表明活动线程比配置中配置的最大活动线程多。那么,为什么配置中的maxActive不工作?如何使其工作?例如,maxActive是100,但当我签入mysql时,活动线程比maxActive多。
-
从ConnectionPools获取和释放JDBC连接的频率?
我正在重构一个最初设计于20世纪90年代中期的遗留系统。在那些日子里,JDBC连接是一种稀缺资源,没有可靠的连接池实现,因此连接被保持得尽可能长。这导致以下结构: 这只是一个例子来说明这种结构中的数据库连接 > 提前打开 会长期开放 传递给所有必须访问数据库的人 现在,在重构过程中,我想删除这种操作模式。考虑到连池和操作尽可能无状态,我可以想象删除数据库连接的每一次传递,并在我需要的时候简单地(从
-
JDBC连接池管理器
我们正在用Java重写来自PHP的web应用程序。我认为,但我不是很确定,我们可能会在连接池方面遇到问题。应用程序本身是多租户的,是“独立数据库”和“独立模式”的组合。 对于每个Postgres数据库服务器实例,可以有一个以上的数据库(命名为schemax_XXX),其中包含一个以上的模式(模式是租户)。注册时,可能会发生以下两种情况之一: 在编号最高的schema_XXX数据库中创建新的租户模式
-
使用JDBC实现迭代器设计模式
我正在解决以下问题: 迭代器设计模式具有很强的封装性。例如,一个图书馆想要一个图书管理系统。一个类用于存储它们的详细信息,一个类用于存储图书和书架号。假设图书馆想要使用将数据存储在数据库中。 如何使用JDBC实现迭代器设计模式以确保数据的封装? 我关心的是在哪里处理数据库以及如何在应用程序之间共享数据。 数据库处理程序可以是库类的内部类吗?那么是否可以保存数据并根据请求检索它而不影响封装? 我还在
-
如何在Spring中将JdbcTemplate转换为Flux?
我有一个返回列表的现有服务 我如何将下面的示例转换为通量,这样我的结果就可以流式传输,而不必在内存中聚集所有项目? 第一个问题:这里我首先将第一个查询的所有结果提取到内存中,然后在内存中迭代并形成我所有的,然后返回整个列表。 因此我试图返回
-
不同模式的Tomcat JDBC连接池
我们如何使用tomcat jdbc为同一个数据库配置两个不同的模式。我们是否需要为不同的模式创建两个不同配置的tomcat jdbc池连接,或者是否可以配置一个jdbc连接池,然后使用该连接池连接到两个不同的模式。
-
JDBC连接池-简单设置和库
这个问题是在前面的问题(使用JDBC实现迭代器设计模式)之后形成的。 我理解连池的基本概念,但仅此而已。我的应用程序需要一个数据库,由于实现迭代器模式的要求,我相信数据库需要经常打开和关闭。因此,需要一个连接池来防止严重的应用程序延迟。最好(从我的理解来看,这是一个很好的做法)我希望池在应用程序启动时打开,关闭时关闭。 我研究了许多连接池库,如BoneCP、DBPool、C3P0和Proxool。
-
我无法使用jdbc调用该函数,但如果它是流水线的,那么一切都可以正常工作
我使用Spring jdbc和oracle 12。 我无法从package函数获得响应。但如果我使用完全相同的函数,但使用管道,一切都会正常。 创建了一个包并在其中声明了2个函数。它们都以一个数字作为输入,并输出一个pl/sql记录表。函数的不同之处在于,一个是流水线的,另一个不是 该宣言是: 主体为: 第一个功能是工作正确: 第二个函数工作不正确: 组织。springframework。jdbc
-
我可以使用postgres JDBC驱动程序从java调用postgres“过程”(不是“函数”)吗?
我是postgres新手,但我正在尝试调用postgres 11中的过程(新的“过程”不是“函数”),以spring SimpleJDBCall(使用Postgresql-42.2.5 jdbc驱动程序)的形式从java调用。然而,当我执行该过程时,我遇到以下异常: (?)}]; BadSqlGrammarException: CallableStatementCallback;坏SQL语法[{调
-
使用Spring jdbcTemplate时的连接池配置
我正在开发一个需要在大型机上调用DB2函数以获取id的应用程序。 在spring应用程序上下文中,我定义了jdbc模板来查询zOS上的DB2: 然后,我将数据源定义如下: 以上工作。然而,看看ibm的db2jcc内部。jar文件中,我看到了一个用于连接池的datasource类-com。ibm。db2.jcc。DB2ConnectionPoolDataSource。所以我试着用它来代替上面的一个,