《负载》专题
-
为什么我得到的是-2147483648和-1的乘法,负数是-2147483648,而不是+2147483648[重复]
这是我在LeetCode中为这个问题编写的代码片段。 } 为什么会这样?请解释一下。
-
如果我们提供参数'count'的负值,MySQL SUBSTRING_INDEX()函数如何返回子字符串?
本文向大家介绍如果我们提供参数'count'的负值,MySQL SUBSTRING_INDEX()函数如何返回子字符串?,包括了如果我们提供参数'count'的负值,MySQL SUBSTRING_INDEX()函数如何返回子字符串?的使用技巧和注意事项,需要的朋友参考一下 MySQL SUBSTRING_INDEX()函数可以接受参数'count'的负值,在这种情况下,它从最终定界符的右边返回子
-
每个微服务的客户端与一般客户端谁负责微服务客户端?
我有一个包含10个微服务的微服务架构,每个微服务提供一个客户端。在由微服务团队管理/控制的客户机内部,我们只接收参数并将它们传递给一个通用http调用程序,该调用程序接收endpoint和N个params,然后进行调用。所有微服务都使用http和web api(我猜技术并不重要)。 对于我来说,作为微服务团队提供一个客户是没有意义的,应该是消费者的责任,如果他们想创建一些抽象或者直接调用它是他们的
-
为什么按位和0xFF负有符号整数将导致正有符号整数?[重复]
我的目标是了解两者的互补性。 有符号整数中的等于。但是,如果您使用十六进制的或十进制的按位与它,它将等于。 在我看来,这不应该发生,因为顶部字节与结果字节相同 我的预期结果是该值不应该改变,它等于< code>-121。 我的实际结果是值发生变化。 我的猜测是,是一个。因此,顶部字节的有符号位和下部字节的无符号位将导致无符号位。但是......那不可能是对的。
-
如何根据日志负载中的某个关键字在Fluentd中更改日志消息的严重性级别(信息、错误、警告等)?
我有集装箱在GKE的kubernetes运行。在/var/log/containers/my_container.log中,我有如下内容(在其他一些不同格式的日志中): 此日志显示在Stackdriver(GKE中的Fluentd输出)上,作为信息日志和类似内容: 所以 我错过了什么?在编写Regex模式时,我不确定是否应该考虑kubernetes日志文件中消息的“log”字段,还是我称之为for
-
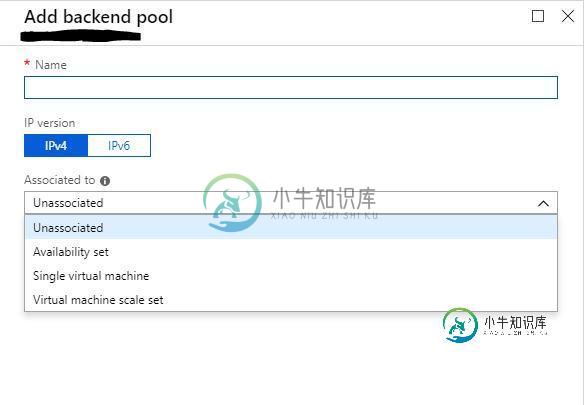 Azure-将连接到Service Fabric VM Scale集的负载均衡器从一个更改为另一个,或者将现有的从public更改为private
Azure-将连接到Service Fabric VM Scale集的负载均衡器从一个更改为另一个,或者将现有的从public更改为private我们有一个公共负载均衡器附加到我们的服务Fabric集群的VM scale集。我创建了一个新的内部私有负载均衡器来附加到VM以获得更好的安全性。但是当我在新的私有负载均衡器的后端池配置中进入Add时,添加VM scale集的选项并不存在。事实上,该屏幕看起来与公共负载均衡器中的添加屏幕不同:(公共负载均衡器有一个“关联到”的下拉菜单,您可以在其中选择虚拟机规模设置,而私有负载均衡器没有该菜单--它
-
当我尝试使用负边距向上移动图像时,整个容器都向上移动
问题内容: 因此,这是html代码: And here is css: 因此,我使用margin-top:-10px,但它移动了整个容器,而不仅仅是图像。 问题答案: 这是由于保证金合拢规则。要解决此问题,您可以简单地在元素上使用透明边框: 现在,为什么添加边框会中止边距折叠规则? 这不是防止保证金崩溃的唯一方法。还有其他方法,例如向元素添加填充。 为什么这可以防止利润减少?因为它(元素)与盒子布
-
带有平衡组的Regex可以处理负前瞻,但不能处理正前瞻(.net方言)
我发布了这个问题的答案,其中OP希望正则表达式匹配不同的JSON类型数据块,条件是其中一个属性具有特定值。 稍微简化一下问题 - 假设一些示例数据如下: 正则表达式应该与匹配,但仅限于存在数据元素的地方。 我在回答中的正则表达式是: < code>layer\s*{(? 它不是明确识别包含< code>foo的匹配,而是排除那些包含< code>fee的匹配。如果所有非< code > fee -
-
通过Cython将C ++向量传递给Numpy,而无需自动复制并负责内存管理
问题内容: 处理大型矩阵(1x <= N <= 20K和10K <= M <= 200K的NxM)时,我经常需要通过Cython将Numpy矩阵传递给C ++,以完成工作,这按预期进行且无需复制。 但是 ,有时我需要在C 中初始化和预处理矩阵并将其传递给 Numpy(Python 3.6) 。假设矩阵是线性化的(因此大小为N * M,它是一维矩阵-col / row major无关紧要)。按照这里
-
从正数和负数集合中找出所有可能的等于0的子集和?[副本]
如果有一个包含一组正数和负数的数组,请打印所有等于0的子集和。 我可以想出一种方法,在那里我可以制作givcen阵列的所有功率集,并检查它们的总和是否为0。但对我来说,这不像是优化的解决方案。 看完网上看起来有点类似的问题,好像可以用下面的程序动态编程来解决,看看是否有组合存在,让和11只是一个例子? 但是我不知道如何将上述程序扩展到 1)包括负数 2)找到使和为零的元素组合(上面的程序只是发现它
-
Dijkstra处理一个负边,并给出正确的解决方案,一旦给出不正确的
我知道这可能会被选为副本(因为我已经看到了这张使用Dijkstra算法的负权重图,所以我认为其中没有一个答案是我想要的。我对Dijkstra算法在有一条负边的图中的解感兴趣,但Dijkstra仍然会显示正确的解。那张图会是什么样子?我无法想象,或者我不擅长enough需要了解Dijkstra如何处理负边缘。我知道有一个带负边的图,可以用Dijkstra遍历,并且仍然有正确的路径。请不要告诉我使用贝
-
来自附近依赖商店的奇怪性能影响,在IvyBridge上的指针追逐循环中。添加额外的负载会加快速度?
首先,我在IvyBridge上有下面的设置,我将在注释的位置插入测量有效载荷代码。< code>buf的前8个字节存储< code>buf本身的地址,我用它来创建循环携带的依赖关系: 我插入有效载荷位置: 显示循环为5.4c/iter。这有点容易理解,因为L1d延迟是4个周期。 我颠倒这两个指令的顺序: 结果突然变成9c/iter。我不明白为什么。因为下一次迭代的第一条指令不依赖于当前迭代的第二条
-
当使用Google Drive API(v3)创建推送通知通道时,在请求正文中将有效负载设置为true会有什么作用吗?
我想从谷歌驱动器API接收元数据或我的推送通知的更改摘要。 文档指出是“一个布尔值,指示是否需要payload。可选。” 有没有人知道这个字段是做什么的(如果有的话),以及是否有方法包括额外的信息?
-
如何使用一台本地计算机作为客户端,使用 aws VM 实例作为服务器来设置分布式 JMeter 负载测试?
我想使用 JMeter 和我的本地计算机作为客户端以及一些 AWS Ubuntu 实例作为服务器来设置负载测试环境。我几乎关注了每篇文章和答案,比如在AWS中设置JMeter以进行分布式测试,包括连接问题和youtube教程,但我每次都会遇到不同的异常。有人能一步一步地清楚地描述如何做到这一点吗? 另外,我找不到这些问题的明确答案: > 哪些更改只需要在服务器端的 jmeter.属性中,还是仅在客
-
为什么两个火花流作业从具有相同组id的相同Kafka主题拉消息不平衡负载,但得到相同的消息?
Kafka 0.8官方文档对Kafka消费者描述如下: “消费者用一个消费者组名称给自己贴标签,发布到主题的每条消息都被传递到每个订阅消费者组中的一个消费者实例。消费者实例可以在不同的进程中或在不同的机器上。如果所有消费者实例都有相同的消费者组,那么这就像传统的队列平衡消费者的负载一样。” 我用Kafka0.8.1.1设置一个Kafka集群,并使用Spark Streaming作业(Spark 1