《内存淘汰》专题
-
简单了解python的内存管理机制
本文向大家介绍简单了解python的内存管理机制,包括了简单了解python的内存管理机制的使用技巧和注意事项,需要的朋友参考一下 Python引入了一个机制:引用计数。 引用计数 python内部使用引用计数,来保持追踪内存中的对象,Python内部记录了对象有多少个引用,即引用计数,当对象被创建时就创建了一个引用计数,当对象不再需要时,这个对象的引用计数为0时,它被垃圾回收。 总结一下对象会在
-
JVM Metaspace内存溢出问题解决方案
本文向大家介绍JVM Metaspace内存溢出问题解决方案,包括了JVM Metaspace内存溢出问题解决方案的使用技巧和注意事项,需要的朋友参考一下 一. 现象 前段时间公司线上环境的一个Java应用因为OOM的异常报警,导致整个服务不可用被拉出集群,本地模拟重现的现象如下: 当时的解决方案是增加metaspace的容量:-XX:MaxMetaspaceSize=500m,从原来默认的256
-
Elasticsearch数据二进制文件内存不足
问题内容: 我试图将800GB的文件上传到elasticsearch,但是我不断收到内存错误,告诉我数据二进制文件内存不足。我的系统上有64GB的RAM和3TB的存储空间 我想知道配置文件中是否有设置可以增加内存量,以便我可以上传到他的文件 谢谢 问题答案: 800GB一次发送就足够了,ES必须将所有内容都放入内存中才能进行处理,因此对于您拥有的内存量来说可能太大了。 解决此问题的一种方法是将您的
-
了解Elasticsearch如何在内部存储日期
问题内容: 我想了解ES如何在其索引内部存储日期值。可以转换为UTC吗? 我有一个日期类型的字段“ t”。这是映射: 现在,当我向ES插入/添加文档时,它如何存储在索引中。 “ t”:“ 1427700477165”(从Date.now()函数生成的毫秒数)。ES是否在UTC中识别其时代时间并按原样存储? “ t”:“ 2015-03-29T23:59:59”(我会相应地调整映射日期格式)-ES如
-
节点Redis发布者占用过多内存
问题内容: 我使用node_redis库在node中编写了一个小的redis发布者。程序完成发布1M消息后,它将继续容纳约 350 MB 的内存。谁能提供任何线索说明该程序为何需要这么多的内存以及如何释放内存? 以下是代码段- 问题答案: 这里有两个问题。 为什么程序需要这么多的内存? 我认为这是由于缺乏反压力。 您的脚本仅向Redis发送1M发布命令,但不处理对这些命令的任何答复(因此,它们仅由
-
造成内存泄漏的操作有哪些?
本文向大家介绍造成内存泄漏的操作有哪些?相关面试题,主要包含被问及造成内存泄漏的操作有哪些?时的应答技巧和注意事项,需要的朋友参考一下 以前使用"引用计数"的时候, 还挺多的, 现在都使用"标记清除"好很多了 最起码循环引用之类的, 不会再内存泄漏了 我觉得比较可能的是, 创建了时间循环, setInterval, 但是没有没有释放掉, 这个比较容易造成内存泄漏
-
在模型执行后清除Tensorflow GPU内存
我已经训练了3个模型,现在正在运行代码,按顺序加载3个检查点中的每一个,并使用它们运行预测。我在用GPU。 当加载第一个模型时,它会预先分配整个GPU内存(我希望用于处理第一批数据)。但它不会在完成时卸载内存。加载第二个模型时,使用第一个型号的GPU内存仍然被完全消耗,第二个型号的内存不足。 除了使用Python子进程或多重处理来解决这个问题(这是我通过谷歌搜索找到的唯一解决方案),还有其他方法可
-
Linux查看内存使用状态(free命令)
free 命令用来显示系统内存状态,包括系统物理内存、虚拟内存(swap 交换分区)、共享内存和系统缓存的使用情况,其输出和 top 命令的内存部分非常相似。 free 命令的基本格式如下: [root@localhost ~]# free [选项] 表 1 罗列出了此命令常用的选项及各自的含义。 表 1 free 命令常用选项及含义 选项 含义 -b 以 Byte(字节)为单位,显示内存使用情况
-
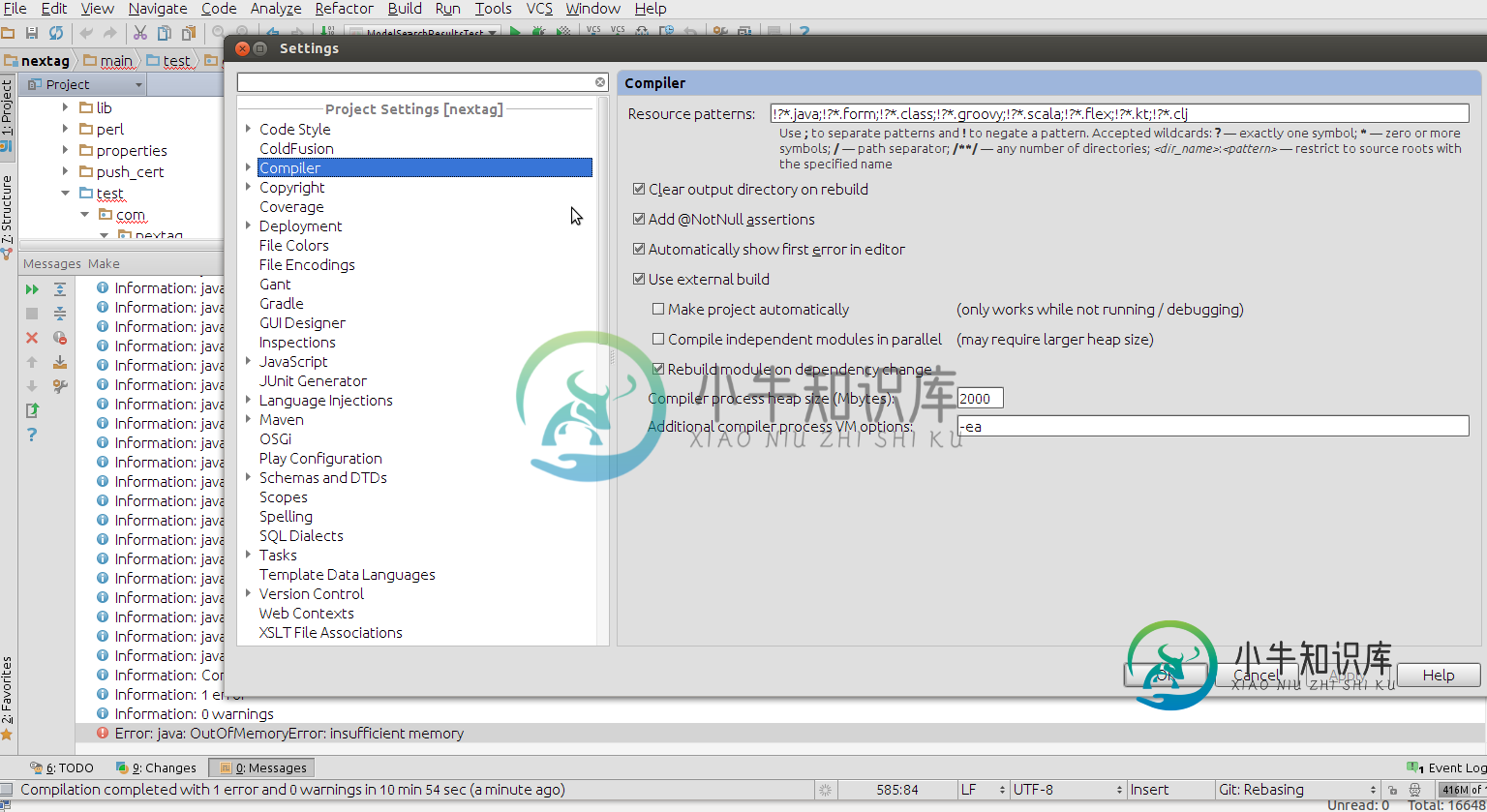 Java:OutofMemoryError:在Idea中运行JUnits时内存不足
Java:OutofMemoryError:在Idea中运行JUnits时内存不足我试图从IntelliJ的想法运行JUnits,当我试图运行test.java文件时,它给了我一个错误,上面写着 Java:OutofMemoryError:内存不足 我尝试将分配给Idea的内存增加到6GB,但它仍然给我带来同样的错误,我遗漏了什么:/
-
 如何计算/供应EMR上的Spark内存?
如何计算/供应EMR上的Spark内存?--Executor-Cores 5--Executor-Memory 35GB--num-Executors 6--conf spark.dynamicallocation.enabled=false 执行器内存计算(236 GB/6执行器)*0.9=35 GB 当我提交一个spark作业并查看spark UI或控制台的执行器度量时,这些数字非常不同,我对如何计算和提供这些度量感到困惑。执行器只
-
如何强制程序显示内存不足?
问题内容: 我有一个C / C ++程序,它在内存不足时可能会挂起。我们通过同时运行许多副本发现了这一点。我想在不完全破坏开发机性能的情况下调试程序。有没有一种方法来限制可用的内存,以便在请求了500K内存之后,new或malloc将返回NULL指针? 问题答案: 试着反省这个问题,并询问如何限制操作系统将允许您的进程使用的内存量。 尝试查看http://ss64.com/bash/ulimit.
-
Java如何处理内存中的String对象?
问题内容: 有人问我这个问题: 根据以上详细信息,在以下代码的println语句之前创建了多少String对象和多少参考变量? 我的回答是,此代码片段的结果是spring winter spring summer 有两个参考变量s1和s2。总共创建了八个String对象,如下所示:“ spring”,“ summer”(丢失),“ spring summer”,“ fall”(丢失),“ spri
-
安装配置/MapReduce的内存使用设置
一、背景 今天采用10台异构的机器做测试,对500G的数据进行运算分析,业务比较简单,集群机器的结构如下: A:双核CPU×1、500G硬盘×1,内存2G×1(Slaver),5台 B:四核CPU×2、500G硬盘×2,内存4G×2(Slaver),4台 C:四核CPU×2、500G硬盘×2,内存4G×8(Master),1台 软件采用Hadoop 0.20.2,Linux操作系统。 二、过程 1
-
使用cElementTree.iterparse解析XML的Python内存不足
问题内容: 我的XML解析功能的简化版本在这里: 这会导致Python的内存不足,这没有任何意义。我真正存储的唯一内容是计数,一个整数。 看到内存和CPU使用率突然下降了吗?那是Python的惊人崩溃。至少它给了我一个(取决于我在循环中所做的事情,它给了我更多的随机错误,如)和堆栈跟踪而不是段错误。但是为什么会崩溃? 问题答案: 该文档确实告诉您“将XML节逐步地解析 到元素树中 (我的重点)”,
-
 详解如何减少python内存的消耗
详解如何减少python内存的消耗本文向大家介绍详解如何减少python内存的消耗,包括了详解如何减少python内存的消耗的使用技巧和注意事项,需要的朋友参考一下 Python 打算删除大量涉及像C和C++语言那样的复杂内存管理。当对象离开范围,就会被自动垃圾收集器回收。然而,对于由 Python 开发的大型且长期运行的系统来说,内存管理是不容小觑的事情。 在这篇博客中,我将会分享关于减少 Python 内存消耗的方法和分析导致